This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative artificialintelligence is the talk of the town in the technology world today. These challenges are primarily due to how data is collected, stored, moved and analyzed. With most AI models, their training data will come from hundreds of different sources, any one of which could present problems.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
(Y Combinator Photo) Seattle-area startups that just graduated from Y Combinator’s summer 2023 batch are tackling a wide range of problems — with plenty of help from artificialintelligence. Neum AI, a platform designed to assist companies in maintaining the relevancy of their AI applications with the latest data.
Defining Cloud Computing in Data Science Cloud computing provides on-demand access to computing resources such as servers, storage, databases, and software over the Internet. For Data Science, it means deploying Analytics , Machine Learning , and Big Data solutions on cloud platforms without requiring extensive physical infrastructure.
Source: IBM Cloud Pak for Data Feature Computation Engine Users can transform batch, streaming, and real-time data into features Source: IBM Cloud Pak for Data To productionize a machine learning system, it is necessary to process new data continuously. Spark, Flink, etc.) How to Get Started?
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificialintelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
The project’s first phase focused on leveraging data replication offered by Precisely to enable near real-time replication of midrange data to AWS with support for heterogeneous source and target databases.
Automation Automating datapipelines and models ➡️ 6. The Data Engineer Not everyone working on a data science project is a data scientist. Data engineers are the glue that binds the products of data scientists into a coherent and robust datapipeline.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a user name, password, and database name. For this post, we add our restaurant data. Choose Add connection.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. VisiData works with CSV files, Excel spreadsheets, SQL databases, and many other data sources.
AI is quickly scaling through dozens of industries as companies, non-profits, and governments are discovering the power of artificialintelligence. This can be helpful for businesses that need to track data from multiple sources, such as sales, marketing, and customer service.
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model. The value of data lineage applies across all industries, but there are three key focuses when you consider it for banking use cases: 1.
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. Amazon DynamoDB is a fast and flexible nonrelational database service for any scale. The ML model is trained from pet profiles pulled from Purina’s database, assuming the primary breed label is the true label.
Generative artificialintelligence (gen AI) is transforming the business world by creating new opportunities for innovation, productivity and efficiency. Data Engineer: A data engineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models.
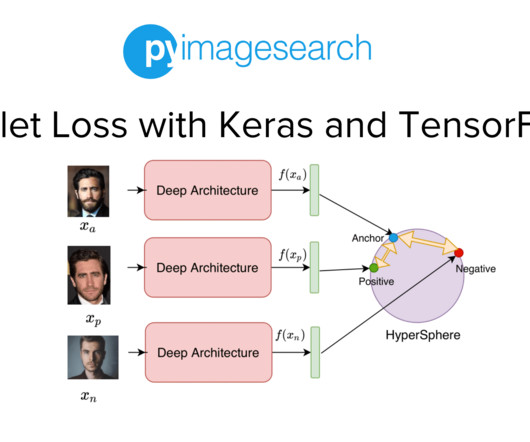
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
Generative artificialintelligence (generative AI) has enabled new possibilities for building intelligent systems. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW Cloud Data Hub (BMW’s data lake on AWS) and on-premises databases. Furthermore, the notebooks can be integrated into the corporate Git repositories to collaborate using version control.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
We’re thrilled to announce our first group of Keynote Speakers, representing the groundbreaking AI companies shaking up the industry including Anthropic, Voltron Data, NVIDIA, Google DeepMind, and Microsoft. Develop the tools to build your future in AI at ODSC West. Learn more about this lineup here!
The release of ChatGPT in late 2022 introduced generative artificialintelligence to the general public and triggered a new wave of AI-oriented companies, products, and open-source projects that provide tools and frameworks to enable enterprise AI.
Implementing Face Recognition and Verification Given that we want to identify people with id-1021 to id-1024 , we are given 1 image (or a few samples) of each person, which allows us to add the person to our face recognition database. On Lines 40 and 41 , we define the path to our face database (i.e.,
Artificialintelligence (AI) adoption is still in its early stages. The Stanford Institute for Human-Centered ArtificialIntelligence’s Center for Research on Foundation Models (CRFM) recently outlined the many risks of foundation models, as well as opportunities. Trustworthiness is critical.
The constant evolution of artificialintelligence has opened up exciting new perspectives in the field of natural language processing (NLP). Modeling tabular data distributions with GReaT Generate datasets without training data What is an LLM and how does it work? Outline What is an LLM and how does it work?
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. And that’s exactly what I do.
This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline. They’re essentially an entire datapipeline within itself. Snowflake even handles the orchestration and scheduling of the refresh.
Data observability is a key element of data operations (DataOps). It enables a big-picture understanding of the health of your organization’s data through continuous AI/ML-enabled monitoring – detecting anomalies throughout the datapipeline and preventing data downtime.
Modin empowers practitioners to use pandas on data at scale, without requiring them to change a single line of code. Modin leverages our cutting-edge academic research on dataframes — the abstraction underlying pandas to bring the best of databases and distributed systems to dataframes. Run operations in pandas - all in Snowflake!
Automated testing to ensure data quality. There are many inefficiencies that riddle a datapipeline and DataOps aims to deal with that. DataOps encourages better collaboration between data professionals and other IT roles. DataOps makes processes more efficient by automating as much of the datapipeline as possible.
It’s the critical process of capturing, transforming, and loading data into a centralised repository where it can be processed, analysed, and leveraged. Data Ingestion Meaning At its core, It refers to the act of absorbing data from multiple sources and transporting it to a destination, such as a database, data warehouse, or data lake.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. In practice, tabular data is anything but clean and uncomplicated.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into data warehouses or databases for analysis. The goal is to retrieve the required data efficiently without overwhelming the source systems.
She’ll cover the distinct challenges that come with handling different data types and how modern tools can turn what feels like chaos into a manageable, streamlined architecture. Data lakes allow for the ingestion of vast amounts of data — regardless of type or format — without the need for a pre-defined schema.
Under this category, tools with pre-built connectors for popular data sources and visual tools for data transformation are better choices. Integration: How well does the tool integrate with your existing infrastructure, databases, cloud platforms, and analytics tools? What is Fivetran?
If you’re in the market for a data integration solution, there are many things to consider – including the flexibility of integration solutions, the availability of a strong network of service providers, and the vendor’s reputation for thought leadership in the integration space.
Well according to Brij Kishore Pandey, it stands for Extract, Transform, Load and is a fundamental process in data engineering, ensuring data moves efficiently from raw sources to structured storage for analysis. The stepsinclude: Extraction : Data is collected from multiple sources (databases, APIs, flatfiles).
This unified schema streamlines downstream consumption and analytics because the data follows a standardized schema and new sources can be added with minimal datapipeline changes. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it.
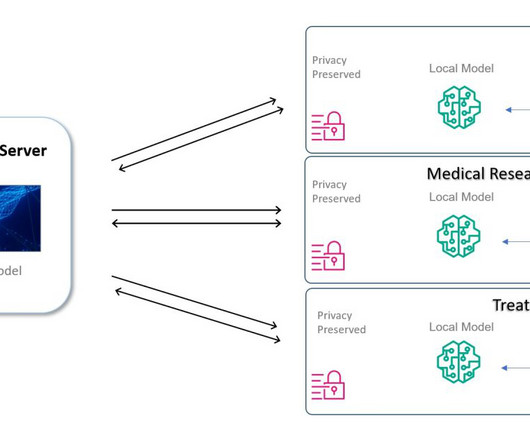
Federation learning to save the day (and save lives) For good artificialintelligence (AI), you need good data. Legacy systems, which are frequently found in the federal domain, pose significant data processing challenges before you can derive any intelligence or merge them with newer datasets.
Through workload optimization across multiple query engines and storage tiers, organizations can reduce data warehouse costs by up to 50 percent. 1 Watsonx.data offers built-in governance and automation to get to trusted insights within minutes, and integrations with existing databases and tools to simplify setup and user experience.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content