This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative artificialintelligence is the talk of the town in the technology world today. These challenges are primarily due to how data is collected, stored, moved and analyzed. With most AI models, their training data will come from hundreds of different sources, any one of which could present problems.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. With a multicloud data strategy, organizations need to optimize for data gravity and data locality.
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
Generative artificialintelligence (generative AI) has enabled new possibilities for building intelligent systems. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and of course, plenty related to large language models and generative AI. You can see our photos from the event here , and be sure to follow our YouTube for virtual highlights from the conference as well.
Because it runs Snowflake SQL from an easy-to-use, code-first GUI interface, it can take advantage of everything Snowflake offers, even if the feature is brand new. This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline.
Automation Automating datapipelines and models ➡️ 6. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. The Data Engineer Not everyone working on a data science project is a data scientist.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Knowing some SQL is also essential.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
With the explosion of big data and advancements in computing power, organizations can now collect, store, and analyze massive amounts of data to gain valuable insights. Machine learning, a subset of artificialintelligence , enables systems to learn and improve from data without being explicitly programmed.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
Great Expectations provides support for different data backends such as flat file formats, SQL databases, Pandas dataframes and Sparks, and comes with built-in notification and data documentation functionality. VisiData works with CSV files, Excel spreadsheets, SQL databases, and many other data sources.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
As the scale and complexity of data handled by organizations increase, traditional rules-based approaches to analyzing the data alone are no longer viable. This is achieved by using the pipeline to transfer data from a Splunk index into an S3 bucket, where it will be cataloged.
That’s a problem when you’re trying to work with that data in pandas because you have to pull the dataset into the memory of your machine, which can be slow, expensive, and lead to fatal out-of-memory issues. Ponder solves this problem by translating your pandas code to SQL that can be understood by your data warehouse.
Create an AI-driven data and process improvement loop to continuously enhance your business operations. An increasing number of GenAI tools use large language models that automate key data engineering, governance, and master data management tasks.
Large manufacturers are starting to use computer vision artificialintelligence (AI) to detect defects cheaper and more efficiently than using human eyes. Detecting product defects can be time-consuming, costly (both for paying people to catch them and if you don’t catch them soon enough), and tedious.
Databases These are structured data collections managed by Database Management Systems (DBMS). Organisations often extract data from relational databases like MySQL, Oracle, or SQL Server to facilitate analysis. It consolidates data into a single source, facilitating accurate reporting and analytics.
Generative AI can be used to automate the data modeling process by generating entity-relationship diagrams or other types of data models and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. This allows you to control which IAM principals are allowed to decrypt the data and view it. For testing, choose yes.
Real-time analytics and BI: Combine data from existing sources with new data to unlock new, faster insights without the cost and complexity of duplicating and moving data across different environments. Presto engine: Incorporates the latest performance enhancements to the Presto query engine.
It’s distributed both in the cloud and on-premises, allowing extensive use and movement across clouds, apps and networks, as well as stores of data at rest. An architecture designed for data democratization aims to be flexible, integrated, agile and secure to enable the use of data and artificialintelligence (AI) at scale.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
Open table formats, such as Delta Lake or Apache Iceberg, add a crucial metadata layer over raw data files, allowing us to manage schema, enforce transactions, and even track changes to datasets over time. Lastly, data version control systems, like lakeFS, allow for a Git-like approach to managing data.
Furthermore, we’ve developed data encryption and governance solutions for HPCC Systems to help secure data, ensure it is only accessed by appropriate personnel, and to create audit trails to ensure data security SLAs and regulations are met. It truly is an all-in-one data lake solution. Tell me more about ECL.
Though scripted languages such as R and Python are at the top of the list of required skills for a data analyst, Excel is still one of the most important tools to be used. Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as Power BI and Tableau as well.
However, a master’s degree or specialised Data Science or Machine Learning courses can give you a competitive edge, offering advanced knowledge and practical experience. Essential Technical Skills Technical proficiency is at the heart of an Azure Data Scientist’s role.
A legacy data stack usually refers to the traditional relational database management system (RDBMS), which uses a structured query language (SQL) to store and process data. While an RDBMS can still be used in a modern data stack, it is not as common because it is not as well-suited for managing big data.
Yet despite these rich capabilities, challenges stillarise The Fragmentation Challenge With so many modular open-source libraries and frameworks now available, effectively stitching together coherent data science application workflows poses a frequent headache for practitioners.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
Support for Numerous Data Sources: Fivetran supports over 200 data sources, including popular databases, applications, and cloud platforms like Salesforce, Google Analytics, SQL Server, Snowflake, and many more. Additionally, unsupported data sources can be integrated using Fivetran’s cloud function connectors.
I have worked with customers where R and SQL were the first-class languages of their data science community. You don’t need a bigger boat : The repository curated by Jacopo Tagliabue shows how several (mostly open-source) tools can be effectively combined together to run datapipelines at scale with very small teams.
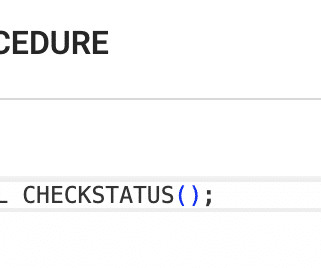
The agent can generate SQL queries using natural language questions using a database schema DDL (data definition language for SQL) and execute them against a database instance for the database tier. Make sure to add a semicolon after the end of the SQL statement generated. Create, invoke, test, and deploy the agent.
As shown in the preceding figure, we define our solution to include planning and reasoning with multiple tools including: Biomarker query engine : Convert natural language questions to SQL statements and execute on an Amazon Redshift database of biomarkers. We reuse the datapipelines described in this blog post.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content