This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The fields of Data Science, ArtificialIntelligence (AI), and Large Language Models (LLMs) continue to evolve at an unprecedented pace. In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields.
RAG helps models access a specific library or database, making it suitable for tasks that require factual accuracy. What is Retrieval-Augmented Generation (RAG) and when to use it Retrieval-Augmented Generation (RAG) is a method that integrates the capabilities of a language model with a specific library or database.
This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data. The goal of datapreparation is to present data in the best forms for decision-making and problem-solving.
Businesses face significant hurdles when preparingdata for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Why do some embedded analytics projects succeed while others fail? We surveyed 500+ application teams embedding analytics to find out which analytics features actually move the needle. Read the 6th annual State of Embedded Analytics Report to discover new best practices. Brought to you by Logi Analytics.
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. Imagine a database with billions of samples ( ) (e.g., So, how can we perform efficient searches in such big databases?
Introduction In the rapidly evolving landscape of ArtificialIntelligence (AI), Retrieval-Augmented Generation (RAG) has emerged as a transformative approach that enhances the capabilities of language models. Creating a Vector Database Once the data is vectorized, the next step is to store these vectors in a vector database.
Summary: This guide explores ArtificialIntelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. It equips you to build and deploy intelligent systems confidently and efficiently.
With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data. You only need to provide a relevant data file as input and choose your FM to get started.
Online analytical processing (OLAP) database systems and artificialintelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Defining OLAP today OLAP database systems have significantly evolved since their inception in the early 1990s.
Robotic process automation vs machine learning is a common debate in the world of automation and artificialintelligence. RPA tools can be programmed to interact with various systems, such as web applications, databases, and desktop applications. It works on structured data and follows a predefined set of rules to perform tasks.
The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables. For instructions to catalog the data, refer to Populating the AWS Glue Data Catalog. Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular.
Generative artificialintelligence (gen AI) is transforming the business world by creating new opportunities for innovation, productivity and efficiency. Start by identifying all potential data sources across your organization, including structured databases.
Multimodal Retrieval Augmented Generation (MM-RAG) is emerging as a powerful evolution of traditional RAG systems, addressing limitations and expanding capabilities across diverse data types. Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models.
Imagine a future where artificialintelligence (AI) seamlessly collaborates with existing supply chain solutions, redefining how organizations manage their assets. If you’re currently using traditional AI, advanced analytics, and intelligent automation, aren’t you already getting deep insights into asset performance?
Generative artificialintelligence ( generative AI ) models have demonstrated impressive capabilities in generating high-quality text, images, and other content. However, these models require massive amounts of clean, structured training data to reach their full potential. Access to Amazon OpenSearch as a vector database.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificialintelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. Your job is to answer questions about a database.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
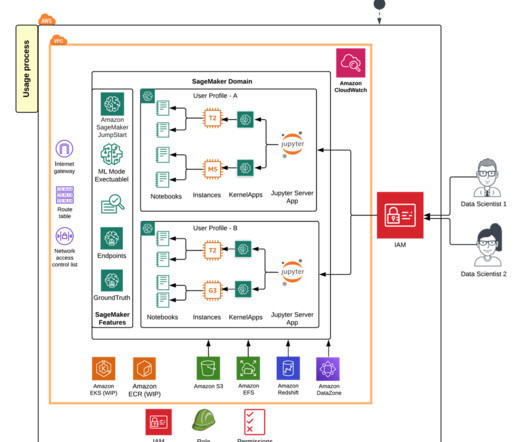
Solution overview With SageMaker Studio JupyterLab notebook’s SQL integration, you can now connect to popular data sources like Snowflake, Athena, Amazon Redshift, and Amazon DataZone. For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem.
However, the majority of enterprise data remains unleveraged from an analytics and machine learning perspective, and much of the most valuable information remains in relational database schemas such as OLAP. Datapreparation happens at the entity-level first so errors and anomalies don’t make their way into the aggregated dataset.
RAG provides additional knowledge to the LLM through its input prompt space and its architecture typically consists of the following components: Indexing : Prepare a corpus of unstructured text, parse and chunk it, and then, embed each chunk and store it in a vector database.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
This means that individuals can ask companies to erase their personal data from their systems and from the systems of any third parties with whom the data was shared. Datapreparation Before creating a knowledge base using Knowledge Bases for Amazon Bedrock, it’s essential to prepare the data to augment the FM in a RAG implementation.
They all agree that a Datamart is a subject-oriented subset of a data warehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW Cloud Data Hub (BMW’s data lake on AWS) and on-premises databases. Furthermore, the notebooks can be integrated into the corporate Git repositories to collaborate using version control.
GenASL is a generative artificialintelligence (AI) -powered solution that translates speech or text into expressive ASL avatar animations, bridging the gap between spoken and written language and sign language. If the gloss is not available in the GenASL database, the logic falls back to fingerspelling each alphabet letter.
The following screenshot shows the Data Catalog schema. Access permission to the AWS Glue databases and tables are managed by AWS Lake Formation. You can find the AWS Glue database name on the Outputs tab of the CloudFormation stack. We have completed the datapreparation step. Choose Create data source.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
Only involving necessary people to do case validation or augmentation tasks reduces the risk of document mishandling and human error when dealing with sensitive data. Sensitive data in these data stores needs to be secured. You can either secure the output PII in your data store or redact the PII in your IDP output.
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring.
Robotic process automation vs machine learning is a common debate in the world of automation and artificialintelligence. RPA tools can be programmed to interact with various systems, such as web applications, databases, and desktop applications. It works on structured data and follows a predefined set of rules to perform tasks.
Being one of the largest AWS customers, Twilio engages with data and artificialintelligence and machine learning (AI/ML) services to run their daily workloads. Here, we predict whether an order is a high_value_order or a low_value_order based on the orderpriority as given from the TPC-H data.
Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform datapreparation and transformation, build ML models, and deploy these models into a governed workflow. He has good experience in databases, AI/ML, data analytics, compute, and storage. csv dataset into SageMaker Canvas.
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability.
File-Based Management: HNSW allows the management of vector indexes as files, providing ease of use and portability, whether stored as blob or stored in a database. This is particularly useful for applications that require dynamic content generation based on current data, such as chatbots and recommendation systems.
Fine tuning Now that your SageMaker HyperPod cluster is deployed, you can start preparing to execute your fine tuning job. Datapreparation The foundation of successful language model fine tuning lies in properly structured and prepared training data.
A recent PwC CEO survey unveiled that 84% of Canadian CEOs agree that artificialintelligence (AI) will significantly change their business within the next 5 years, making this technology more critical than ever. As such, an ML model is the product of an MLOps pipeline, and a pipeline is a workflow for creating one or more ML models.
He highlights innovations in data, infrastructure, and artificialintelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Embeddings can be stored in a database and are used to enable streamlined and more accurate searches.
A Gentle Introduction to Vector Databases and Their Implementation with Balaji Dhamodharan Slides Balaji Dhamodharan’s AI slides offered a deep dive into vector databases, a foundational technology for LLMs. Steven Pousty showcased how to transform unstructured data into a vector-based query system.
Visual modeling: Delivers easy-to-use workflows for data scientists to build datapreparation and predictive machine learning pipelines that include text analytics, visualizations and a variety of modeling methods. foundation models to help users discover, augment, and enrich data with natural language.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content