This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: This guide explores ArtificialIntelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. It equips you to build and deploy intelligent systems confidently and efficiently.
These statistical models are growing as a result of the wide swaths of available current data as well as the advent of capable artificialintelligence and machine learning. Data Sourcing. The applications of predictive analytics are extensive and often require four key components to maintain effectiveness.
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificialintelligence. Part 1: Datapreparation & feature extraction The first step in any machine learning project is to prepare your data.
Introduction Data Science and ArtificialIntelligence (AI) are at the forefront of technological innovation, fundamentally transforming industries and everyday life. Enhanced data visualisation aids in better communication of insights. Domain knowledge is crucial for effective data application in industries.
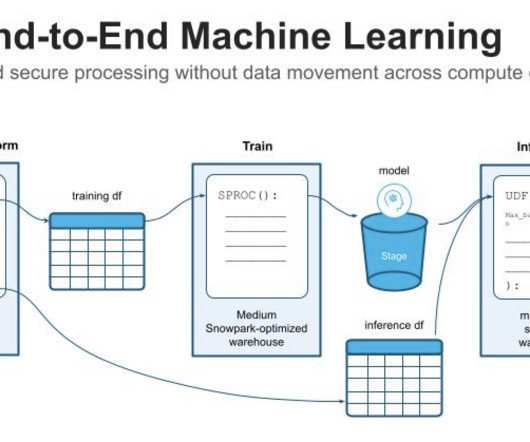
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
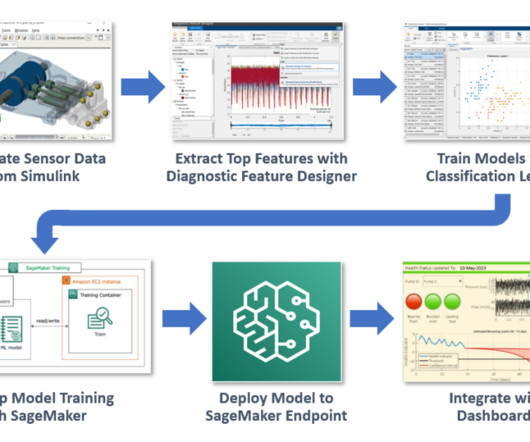
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., On Lines 21-27 , we define a Node class, which represents a node in a decisiontree.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. For example, linear regression is typically used to predict continuous variables, while decisiontrees are great for classification and regression tasks.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: Data Ingestion: Collecting data from various sources and ensuring it’s available for analysis. DataPreparation: Cleaning and transforming raw data to make it usable for machine learning.
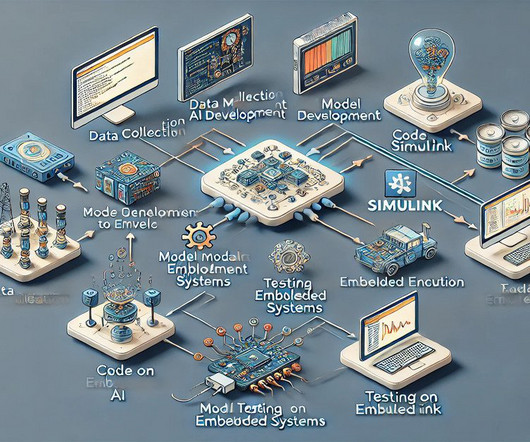
Understanding Embedded AI Embedded AI refers to the integration of ArtificialIntelligence capabilities directly into embedded systems. This involves: DataPreparation : Collect and preprocess data to ensure it is suitable for training your model. Model Selection : Choose appropriate algorithms (e.g.,
Introduction Boosting is a powerful Machine Learning ensemble technique that combines multiple weak learners, typically decisiontrees, to form a strong predictive model. It identifies the optimal path for missing data during tree construction, ensuring the algorithm remains efficient and accurate. Lower values (e.g.,
The quality and quantity of data collected play a crucial role in the accuracy of predictions. DataPreparation Once the data is collected, it must be cleaned and prepared for analysis. This involves removing duplicates, correcting errors, and formatting the data appropriately.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
With a modeled estimation of the applicant’s credit risk, lenders can make more informed decisions and reduce the occurrence of bad loans, thereby protecting their bottom line. More recently, ensemble methods and deep learning models are being explored for their ability to handle high-dimensional data and capture complex patterns.
In the modern digital era, this particular area has evolved to give rise to a discipline known as Data Science. Data Science offers a comprehensive and systematic approach to extracting actionable insights from complex and unstructured data. Machine learning algorithms Machine learning forms the core of Applied Data Science.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. Dive Deep into Machine Learning and AI Technologies Study core Machine Learning concepts, including algorithms like linear regression and decisiontrees.
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificialintelligence. Machine learning algorithms are specialized computational models designed to analyze data, recognize patterns, and make informed predictions or decisions.
It groups similar data points or identifies outliers without prior guidance. Type of Data Used in Each Approach Supervised learning depends on data that has been organized and labeled. This datapreparation process ensures that every example in the dataset has an input and a known output.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content