This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in Data Science.
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. We will start by setting up libraries and datapreparation.
source env_vars After setting your environment variables, download the lifecycle scripts required for bootstrapping the compute nodes on your SageMaker HyperPod cluster and define its configuration settings before uploading the scripts to your S3 bucket. script to download the model and tokenizer. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
In the following sections, we demonstrate how to import and prepare the data, optionally export the data, create a model, and run inference, all in SageMaker Canvas. Download the dataset from Kaggle and upload it to an Amazon Simple Storage Service (Amazon S3) bucket.
In such situations, it may be desirable to have the data accessible to SageMaker in the ephemeral storage media attached to the ephemeral training instances without the intermediate storage of data in Amazon S3. We add this data to Snowflake as a new table. Launch a SageMaker Training job for training the ML model.
Artificialintelligence (AI) and machine learning (ML) have seen widespread adoption across enterprise and government organizations. Processing unstructured data has become easier with the advancements in natural language processing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend.
Identifying Traditional Nigerian Textiles using ArtificialIntelligence on Android Devices ( Part 1 ) Nigeria is a country blessed by God with 3 major ethnic groups( Yoruba, Hausa, and Ibo) and these different ethnic groups have their different cultural differences in terms of dressing, marriage, food, etc.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. jpg") or doc.endswith(".png")) b64encode(fIn.read()).decode("utf-8")
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import. This can take a few minutes.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificialintelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. This process might take a couple of hours.
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., To download our dataset and set up our environment, we will install the following packages.
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket.
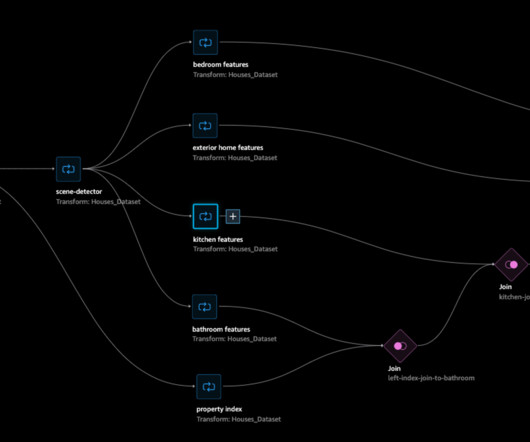
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. Our training script uses this location to download and prepare the training data, and then train the model. split('/',1) s3 = boto3.client("s3")
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
In the rapidly expanding field of artificialintelligence (AI), machine learning tools play an instrumental role. Moreover, the library can be downloaded in its entirety from reliable sources such as GitHub at no cost, ensuring its accessibility to a wide range of developers.
GenASL is a generative artificialintelligence (AI) -powered solution that translates speech or text into expressive ASL avatar animations, bridging the gap between spoken and written language and sign language. You can download and install Docker from Docker’s official website. That’s where GenASL comes in.
Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform datapreparation and transformation, build ML models, and deploy these models into a governed workflow. Download the following student dataset to your local computer. Set up SageMaker Canvas. csv dataset into SageMaker Canvas.
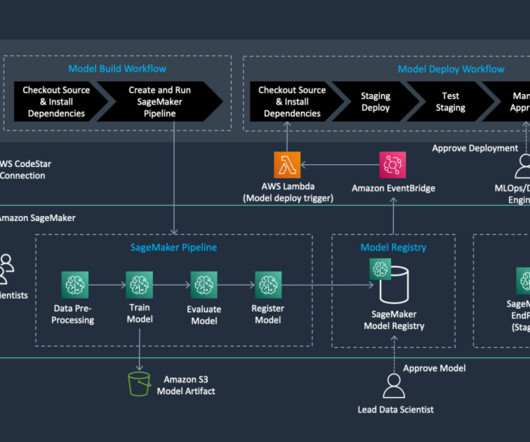
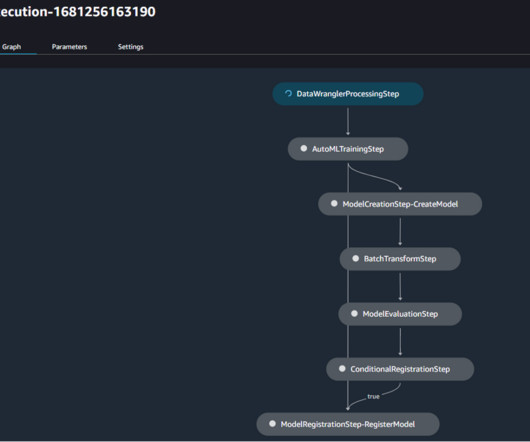
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Download the template.yml file to your computer. Upload the template you downloaded. Choose Create a new portfolio. Choose Review.
You can watch the full video of this session here and download the slideshere. Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. For instance: DataPreparation: GoogleSheets.
Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. For more information, refer to Granting Data Catalog permissions using the named resource method. We have completed the datapreparation step.
Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics. Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data.
With the addition of forecasting, you can now access end-to-end ML capabilities for a broad set of model types—including regression, multi-class classification, computer vision (CV), natural language processing (NLP), and generative artificialintelligence (AI)—within the unified user-friendly platform of SageMaker Canvas.
Complete the following steps to use Autopilot AutoML to build, train, deploy, and share an ML model with a business analyst: Download the dataset , upload it to an Amazon S3 ( Amazon Simple Storage Service ) bucket, and make a note of the S3 URI. Download the abalone dataset from Kaggle. In this example, we use the abalone dataset.
These activities are recorded in a model recipe , which is a series of steps towards datapreparation. This recipe is maintained throughout the lifecycle of a particular ML model from datapreparation to generating predictions. These predictions can be previewed and downloaded for use with downstream applications.
Today, generative artificialintelligence (AI) can enable you to write complex SQL queries without requiring in-depth SQL experience. If you specify model_id=defog/sqlcoder-7b-2 , DJL Serving will attempt to directly download this model from the Hugging Face Hub. The model weights will be stored in your local machine’s cache.
This means that individuals can ask companies to erase their personal data from their systems and from the systems of any third parties with whom the data was shared. Datapreparation Before creating a knowledge base using Knowledge Bases for Amazon Bedrock, it’s essential to prepare the data to augment the FM in a RAG implementation.
Each step of the workflow is developed in a different notebook, which are then converted into independent notebook jobs steps and connected as a pipeline: Preprocessing – Download the public SST2 dataset from Amazon Simple Storage Service (Amazon S3) and create a CSV file for the notebook in Step 2 to run.
Here, we use the term foundation model to describe an artificialintelligence (AI) capability that has been pre-trained on a large and diverse body of data. We selected the model with the most downloads at the time of this writing. The next figure offers a view of how the full-scale data transformation job is run.
Here are some of the key trends and challenges facing telecommunications companies today: The growth of AI and machine learning: Telecom companies use artificialintelligence and machine learning (AI/ML) for predictive analytics and network troubleshooting. Finally, the one-off approach creates a delay.
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Anomaly detection ( Figure 2 ) is a critical technique in data analysis used to identify data points, events, or observations that deviate significantly from the norm.
Users can download datasets in formats like CSV and ARFF. The UCI connection lends the repository credibility, as it is backed by a leading academic institution known for its contributions to computer science and artificialintelligence research. CSV, ARFF) to begin the download. Simply click the preferred format (e.g.,
It does so by covering the ML workflow end-to-end: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, and ready-to-use models powered by AWS AI services and Generative AI, SageMaker Canvas can help you to achieve your goals.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
You can download the endzone and sideline videos , and also the ground truth labels. map(int) return output_df To run the function, we run the following code block to provide the location of the train_labels.csv data and then perform datapreparation to add an additional column and extract only the impact rows.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML.
Please refer to section 4, “Preparingdata,” from the post Building a custom classifier using Amazon Comprehend for the script and detailed information on datapreparation and structure.
Jump Right To The Downloads Section Image Segmentation with U-Net in PyTorch: The Grand Finale of the Autoencoder Series Introduction Image segmentation is a pivotal task in computer vision where each pixel in an image is assigned a specific label, effectively dividing the image into distinct regions. Looking for the source code to this post?
The publicly available Llama models have been downloaded more than 30M times, and customers love that Amazon Bedrock offers them as part of a managed service where they don’t need to worry about infrastructure or have deep ML expertise on their teams.
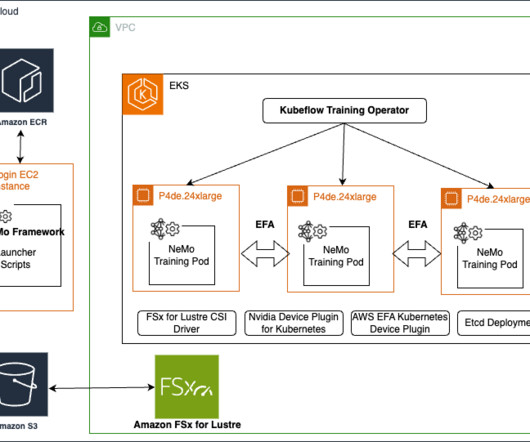
In today’s rapidly evolving landscape of artificialintelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. For training, use gpt3/126m.
Data Wrangler provides an end-to-end solution to import, prepare, transform, featurize, and analyze data. You can integrate a Data Wrangler datapreparation flow into your ML workflows to simplify and streamline data preprocessing and feature engineering using little to no coding.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content