This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
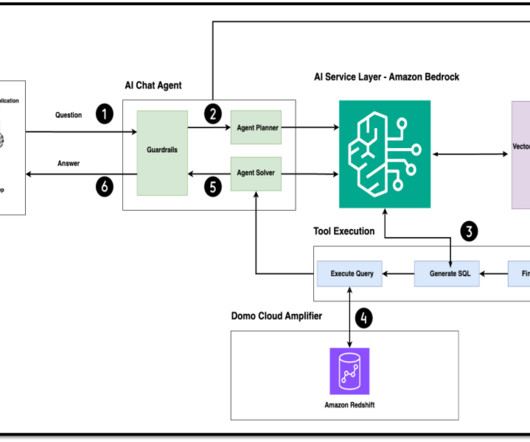
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
This includes sourcing, gathering, arranging, processing, and modeling data, as well as being able to analyze large volumes of structured or unstructured data. The goal of datapreparation is to present data in the best forms for decision-making and problem-solving.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificialintelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. This process might take a couple of hours.
Its cloud-native architecture, combined with robust data-sharing capabilities, allows businesses to easily leverage cutting-edge tools from partners like Dataiku, fostering innovation and driving more insightful, data-driven outcomes. One of the standout features of Dataiku is its focus on collaboration.
Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Tapping into these schemas and pulling out machine learning-ready features can be nontrivial as one needs to know where the data entity of interest lives (e.g., customers), what its relations are, and how they’re connected, and then write SQL, python, or other to join and aggregate to a granularity of interest.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Specifically, we cover the computer vision and artificialintelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Previously, he was a software solutions architect for deep learning, analytics, and big data technologies at Intel.
Being one of the largest AWS customers, Twilio engages with data and artificialintelligence and machine learning (AI/ML) services to run their daily workloads. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. All pipeline parameters used in this solution exist in a single config.yml file.
Generative artificialintelligence ( generative AI ) models have demonstrated impressive capabilities in generating high-quality text, images, and other content. However, these models require massive amounts of clean, structured training data to reach their full potential. This will land on a data flow page.
Forbes reports that global data production increased from 2 zettabytes in 2010 to 44 ZB in 2020, with projections exceeding 180 ZB by 2025 – a staggering 9,000% growth in just 15 years, partly driven by artificialintelligence. However, raw data alone doesn’t equate to actionable insights.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. Data professionals such as data scientists want to use the power of Apache Spark , Hive , and Presto running on Amazon EMR for fast datapreparation; however, the learning curve is steep.
Power BI Datamarts provide no-code/low-code datamart capabilities using Azure SQL Database technology in the background. The Power BI Datamarts support sensitivity labels, endorsement, discovery, and Row-Level Security ( RLS ), which help protect and manage the data according to the business requirements and compliance needs.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
Data insights are crucial for businesses to enable data-driven decisions, identify trends, and optimize operations. Generative artificialintelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape. Interprets data to uncover actionable insights guiding business decisions.
This means that individuals can ask companies to erase their personal data from their systems and from the systems of any third parties with whom the data was shared. Datapreparation Before creating a knowledge base using Knowledge Bases for Amazon Bedrock, it’s essential to prepare the data to augment the FM in a RAG implementation.
Businesses face significant hurdles when preparingdata for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
QuickSight connects to your data and combines data from many different sources, such as Amazon S3 and Athena. For our solution, we use Athena as the data source. Athena is an interactive query service that makes it easy to analyze data directly in Amazon S3 using standard SQL.
You can now optionally select or deselect columns, join tables by dragging another table into the Drag and drop datasets to join section, or write SQL queries to specify your data slice. For this post, we use all the data in the table. To import the data, choose Import data. Volkan Unsal is a Sr.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Visual modeling: Delivers easy-to-use workflows for data scientists to build datapreparation and predictive machine learning pipelines that include text analytics, visualizations and a variety of modeling methods. Presto engine: Incorporates the latest performance enhancements to the Presto query engine.
Challenges Learning Curve : Qlik’s unique Data Analysis approach requires a bit of a learning curve, especially for new users. DataPreparation : Preparingdata in Qlik is not as intuitive as other BI tools, which may slow the time to actionable insights.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. Understand data structures and explore data warehousing concepts to efficiently manage and retrieve large datasets.
We also examined the results to gain a deeper understanding of why these prompt engineering skills and platforms are in demand for the role of Prompt Engineer, not to mention machine learning and data science roles. Kubernetes: A long-established tool for containerized apps.
Data Wrangler simplifies the process of datapreparation and feature engineering like data selection, cleansing, exploration, and visualization from a single visual interface. Data Wrangler has more than 300 preconfigured data transformations that can effectively be used in transforming the data.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. However, a master’s degree or specialised Data Science or Machine Learning courses can give you a competitive edge, offering advanced knowledge and practical experience.
Tools like Apache NiFi, Talend, and Informatica provide user-friendly interfaces for designing workflows, integrating diverse data sources, and executing ETL processes efficiently. Choosing the right tool based on the organisation’s specific needs, such as data volume and complexity, is vital for optimising ETL efficiency.
For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023. We have a number of records, each with A target (or label ) column, dessert, containing a binary input (1.0 if the recipe is a dessert, 0.0
Generative artificialintelligence (AI) applications built around large language models (LLMs) have demonstrated the potential to create and accelerate economic value for businesses. Define strict data ingress and egress rules to help protect against manipulation and exfiltration using VPCs with AWS Network Firewall policies.
How the watsonx Regulatory Compliance Platform accelerates risk management The watsonx.ai™, watsonx.gov, and watsonx.data™ components of the platform are advanced artificialintelligence (AI) modules that offer a wide range of advance technical features designed to meet the unique needs of the industry.
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve.
The assistant is connected to internal and external systems, with the capability to query various sources such as SQL databases, Amazon CloudWatch logs, and third-party tools to check the live system health status. Creating ETL pipelines to transform log dataPreparing your data to provide quality results is the first step in an AI project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content