This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
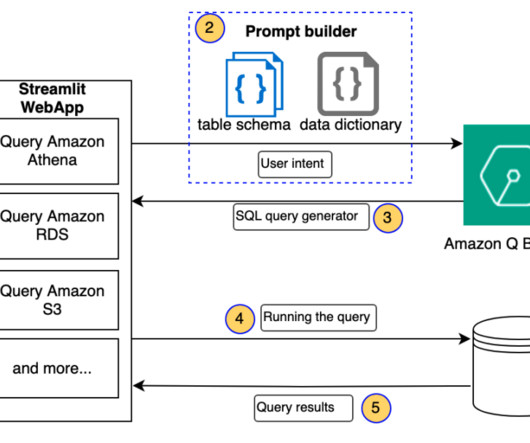
SQL (Structured Query Language) is an important tool for data scientists. It is a programming language used to manipulate data stored in relational databases. Mastering SQL concepts allows a data scientist to quickly analyze large amounts of data and make decisions based on their findings.
In the process of working on their ML tasks, data scientists typically start their workflow by discovering relevant data sources and connecting to them. They then use SQL to explore, analyze, visualize, and integrate data from various sources before using it in their ML training and inference.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Data is reported from one central repository, enabling management to draw more meaningful business insights and make faster, better decisions. By running reports on historical data, a datawarehouse can clarify what systems and processes are working and what methods need improvement.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Generative artificialintelligence is the talk of the town in the technology world today. Space and Time’s creator SxT Labs has created three technologies that underpin its verifiable compute layer, including a blockchain indexer, a distributed datawarehouse and a zero-knowledge coprocessor.
In this article, we will delve into the concept of data lakes, explore their differences from datawarehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. Schema Enforcement: Datawarehouses use a “schema-on-write” approach.
One of the most common applications of generative artificialintelligence (AI) and large language models (LLMs) in an enterprise environment is answering questions based on the enterprise’s knowledge corpus. Natural language is ambiguous and imprecise, whereas data adheres to rigid schemas.
Unified data storage : Fabric’s centralized data lake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. Flexible compute capacity One of the key advantages of Microsoft Fabric is its ability to optimize compute capacity across different workloads.
Its cloud-native architecture, combined with robust data-sharing capabilities, allows businesses to easily leverage cutting-edge tools from partners like Dataiku, fostering innovation and driving more insightful, data-driven outcomes. Dataiku and Snowflake: A Good Combo?
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
The Microsoft Certified Solutions Associate and Microsoft Certified Solutions Expert certifications cover a wide range of topics related to Microsoft’s technology suite, including Windows operating systems, Azure cloud computing, Office productivity software, Visual Studio programming tools, and SQL Server databases.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehouse costs by up to 50 percent by augmenting with this solution. [1]
Run pandas at scale on your datawarehouse Most enterprise data teams store their data in a database or datawarehouse, such as Snowflake, BigQuery, or DuckDB. Ponder solves this problem by translating your pandas code to SQL that can be understood by your datawarehouse.
They all agree that a Datamart is a subject-oriented subset of a datawarehouse focusing on a particular business unit, department, subject area, or business functionality. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
With Great Expectations , data teams can express what they “expect” from their data using simple assertions. Great Expectations provides support for different data backends such as flat file formats, SQL databases, Pandas dataframes and Sparks, and comes with built-in notification and data documentation functionality.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
The rules in this engine were predefined and written in SQL, which aside from posing a challenge to manage, also struggled to cope with the proliferation of data from TR’s various integrated data source. TR customer data is changing at a faster rate than the business rules can evolve to reflect changing customer needs.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
Another unexpected challenge was the introduction of Spark as a processing framework for big data. It gained rapid popularity given its support for data transformations, streaming and SQL. But it never co-existed amicably within existing data lake environments.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
It is a data integration process that involves extracting data from various sources, transforming it into a suitable format, and loading it into a target system, typically a datawarehouse. ETL is the backbone of effective data management, ensuring organisations can leverage their data for informed decision-making.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Common databases appear unable to cope with the immense increase in data volumes. This is where the BigQuery datawarehouse comes into play. Building a data center on your own can be expensive, time-consuming, and difficult to scale. BigQuery for Marketing: What Makes it Special?
Datawarehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as business intelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics that enable faster decision making and insights.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
To start using CloudWatch anomaly detection, you first must ingest data into CloudWatch and then enable anomaly detection on the log group. Using Amazon Redshift ML for anomaly detection Amazon Redshift ML makes it easy to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift datawarehouses.
Classical data systems are founded on this story. Nonetheless, the truth is slowing starting to emerge… The value of data is not in insights Most dashboards fail to provide useful insights and quickly become derelict. We increasingly refer to these technologies collectively as ArtificialIntelligence (AI).
It’s distributed both in the cloud and on-premises, allowing extensive use and movement across clouds, apps and networks, as well as stores of data at rest. An architecture designed for data democratization aims to be flexible, integrated, agile and secure to enable the use of data and artificialintelligence (AI) at scale.
Data science solves a business problem by understanding the problem, knowing the data that’s required, and analyzing the data to help solve the real-world problem. Machine learning (ML) is a subset of artificialintelligence (AI) that focuses on learning from what the data science comes up with.
Amazon Bedrock , a fully managed service designed to facilitate the integration of LLMs into enterprise applications, offers a choice of high-performing LLMs from leading artificialintelligence (AI) companies like Anthropic, Mistral AI, Meta, and Amazon through a single API. The LLM generates output based on the user prompt.
This includes integration with your datawarehouse engines, which now must balance real-time data processing and decision-making with cost-effective object storage, open source technologies and a shared metadata layer to share data seamlessly with your data lakehouse.
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Understanding the differences between SQL and NoSQL databases is crucial for students. Data Warehousing Solutions Tools like Amazon Redshift, Google BigQuery, and Snowflake enable organisations to store and analyse large volumes of data efficiently. Understanding the benefits and challenges of cloud storage is crucial.
However, a master’s degree or specialised Data Science or Machine Learning courses can give you a competitive edge, offering advanced knowledge and practical experience. Essential Technical Skills Technical proficiency is at the heart of an Azure Data Scientist’s role.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content