This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
It provides a large cluster of clusters on a single machine. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing. AWS SageMaker provides managed services, including model management and lifecycle management using a centralized, debugged model.
At Databricks, we run our compute infrastructure on AWS, Azure, and GCP. We orchestrate containerized services using Kubernetes clusters. We develop and manage.
Microsoft Azure. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Azure Synapse Analytics This is the future of data warehousing. If you are at a University or non-profit, you can ask for cash and/or AWS credits. Amazon Web Services. Google Cloud.
I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for Data Science. In my last consulting job, I was asked to do tasks that Data Factory and Form Recognizer can easily do for AWS/Amazon cloud services. It will take a couple of months but it is worth it!
The strategic value of IoT development and data analytics Sierra Wireless Sierra Wireless , a wireless communications equipment designer and service provider, has been honing its focus on IoT software and managed services following its acquisition of M2M Group, a cluster of companies dedicated to IoT connectivity, in 2020.
It then performs transformations using the Hadoop cluster or the features of the database. Azure Data Factory : This is a fully managed service that connects to a wide range of On-Premise and Cloud sources. It can easily transform, copy, and enrich the data, finally writing it to Azure data services as a destination. Conclusion.
The key components of Instana are host agents and agent sensors deployed on platforms like IBM Cloud®, AWS, and Azure. Supported cloud platforms with IBM Instana IBM Instana supports IBM Cloud, AWS, Azure and SAP. Currently, Instana supports SAP BTP Kyma cluster monitoring.
Organizations that want to build their own models or want granular control are choosing Amazon Web Services (AWS) because we are helping customers use the cloud more efficiently and leverage more powerful, price-performant AWS capabilities such as petabyte-scale networking capability, hyperscale clustering, and the right tools to help you build.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others.
Generative AI with LLMs course by AWS AND DEEPLEARNING.AI Build expertise in computer vision, clustering algorithms, deep learning essentials, multi-agent reinforcement, DQN, and more. it consists of 2 courses- a Google AI course for Beginners and a Google AI course for JS Developers.
Decide between cloud-based solutions, such as AWS Redshift or Google BigQuery, and on-premises options, while considering scalability and whether a hybrid approach might be beneficial. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
Autoscaling When traffic spikes, Kubernetes can automatically spin up new clusters to handle the additional workload. However, unlike VMs, Kubernetes orchestrates container interactions that transcend apps and clusters. This includes data in CI/CD pipelines (which feed into K8s clusters) and GitOps workflows (which power K8s clusters).
High-Performance Computing (HPC) Clusters These clusters combine multiple GPUs or TPUs to handle extensive computations required for training large generative models. The demand for advanced hardware continues to grow as organisations seek to develop more sophisticated Generative AI applications.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. As an open-source system, Kubernetes services are supported by all the leading public cloud providers, including IBM, Amazon Web Services (AWS), Microsoft Azure and Google.
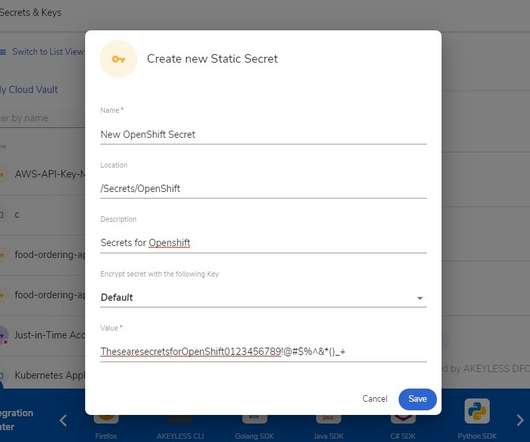
Another option is the environment variable KUBECONFIG=<path-to-kubeconfig> – This is used by OC/Kubectl to set context while working with the cluster Webhook installation – One installation is needed for each Akeyless account. As such, cluster admins can peer into the secrets kept by tenants.
Partitioning and clustering features inherent to OTFs allow data to be stored in a manner that enhances query performance. Cost Efficiency and Scalability Open Table Formats are designed to work with cloud storage solutions like Amazon S3, Google Cloud Storage, and Azure Blob Storage, enabling cost-effective and scalable storage solutions.
IBM Consulting does this with not just the strong technology/product capabilities brought by Red Hat and IBM technology but with a strong ecosystem with hyperscalers like AWS, Azure, IBM Cloud®, GCP and OCI. Get flexibility and scale, with 1-year, 3-year or 5-year committed pricing.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Cloud-based data warehouses, such as Snowflake , AWS’ portfolio of databases like RDS, Redshift or Aurora , or an S3-based data lake , are a great match to ML use cases since they tend to be much more scalable than traditional databases, both in terms of the data set sizes as well as query patterns. Software Development Layers.
TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering. AWS Cloud, Azure Cloud, and others are all compatible with many other frameworks and languages, making them necessary for any NLP skill set.
By creating the appropriate policies to merge clusters (even between vCenters® and data centers), virtual machines can be live migrated to their new destination. Once you’ve consolidated onto fewer hosts, you might want to move to fewer data centers, and potentially reduce your licensing costs.
The Good — Ease of use The key differentiator of Google Colab is its ease of use; the distance from starting a Colab notebook to utilizing a fully working TPUs cluster is super short. Colab's common usage flow relies heavily on G-Drive integration, making complicated actions like authorization almost seamless.
You can adopt these strategies as well as focus on continuous learning to upscale your knowledge and skill set. Leverage Cloud Platforms Cloud platforms like AWS, Azure, and GCP offer a suite of scalable and flexible services for data storage, processing, and model deployment.
Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Horizontal scaling increases the quantity of computational resources dedicated to a workload; the equivalent of adding more servers or clusters. Certain CSPs are even equipped to automatically scale compute resources, based on demand.
Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. But the issue we found was that MP is efficient in single-node clusters, but in a multi-node setting, the inference isn’t efficient. For instance, a 1.5B This is because of the low bandwidth networks.
In this post, we’ll take a look at some of the factors you could investigate, and introduce the six databases our customers work with most often: Amazon Neptune ArangoDB Azure Cosmos DB JanusGraph Neo4j TigerGraph Why these six graph databases?
The MLOps Management Agent provides a framework to automate the entire model deployment lifecycle in any environment or infrastructure such as Azure, GCP, AWS, or your own on-premise Kubernetes cluster. See It Live: Kubernetes Deployment on Azure. A Standardized Lifecycle Management Framework.
Check out this course to upskill on Apache Spark — [link] Cloud Computing technologies such as AWS, GCP, Azure will also be a plus. Check this course to upskill on AWS — [link] Domain Knowledge Having expertise in a specific industry domain, such as finance, healthcare, or marketing, can be advantageous.
In addition to empowering admins to manually provision users and configure access on the platform, Snorkel Flow can sync with external identity providers like Azure Active Directory to directly consume entitlement information within SAML or OIDC SSO integrations.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Hadoop Hadoop is an open-source framework designed for processing and storing big data across clusters of computer servers.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand. authorization server.
In this blog, we will review the steps to create Snowflake-managed Iceberg tables with AWS S3 as external storage and read them from a Spark or Databricks environment. Externally Managed Iceberg Tables – An external system, such as AWS Glue , manages the metadata and catalog. These tables support read-only access from Snowflake.
The two most common types of unsupervised learning are clustering , where the algorithm groups similar data points together, and dimensionality reduction , where the algorithm reduces the number of features in the data. It is highly configurable and can integrate with other tools like Git, Docker, and AWS.
Python facilitates the application of various unsupervised algorithms for clustering and dimensionality reduction. K-Means Clustering K-means partition data points into K clusters based on similarities in feature space.
And the highlight, for us data intelligence folks, was the Databricks’ announcement that Unity Catalog , its unified governance solution for all data assets on its Lakehouse platform, will soon be available on AWS and Azure in the upcoming weeks. Unity features include: Built-in search and discovery.
The shared-nothing architecture ensures that users don’t have to worry about distributing data across multiple cluster nodes. The external stage area includes Microsoft Azure Blob storage, Amazon AWS S3, and Google Cloud Storage. Cloud Storage Snowflake leverages the cloud’s native object storage services (e.g.
Key techniques in unsupervised learning include: Clustering (K-means) K-means is a clustering algorithm that groups data points into clusters based on their similarities. Unsupervised Learning Unsupervised learning involves training models on data without labels, where the system tries to find hidden patterns or structures.
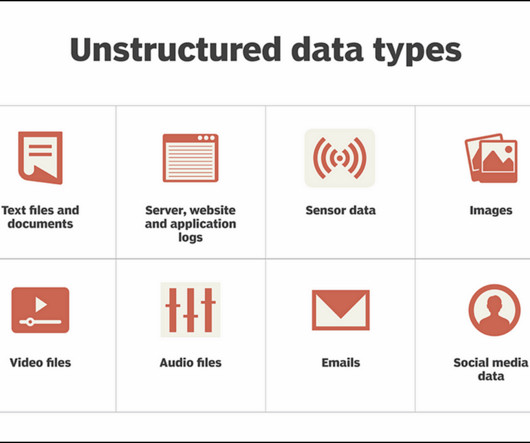
Relational databases (like MySQL) or No-SQL databases (AWS DynamoDB) can store structured or even semi-structured data but there is one inherent problem. A database that help index and search at blazing speed. Unstructured data is hard to store in relational databases.
Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers. Azure Microsoft Azure offers a range of services for Data Engineering, including Azure Data Lake for scalable storage and Azure Databricks for collaborative Data Analytics.
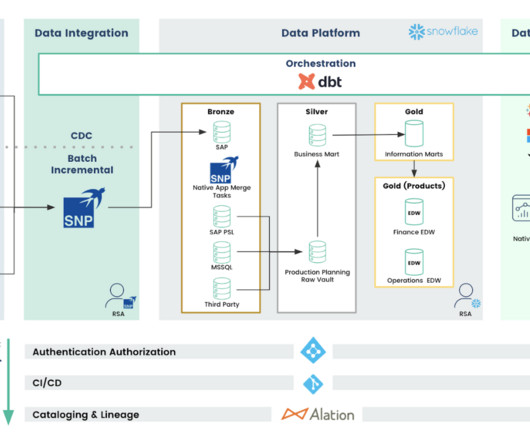
On top of this, SAP uses proprietary data formats such as clustered tables and calculated views that make it difficult to understand. SNP Glue is an SAP-certified connector that seamlessly bridges the gap between your SAP systems and various cloud platforms like Azure, AWS, and Snowflake. What is SNP Glue?
It has what’s known as elastic, multi-cluster scalability, allowing workflows to be provisioned across multiple Kafka clusters, rather than just one, enabling greater scalability, high throughput and low latency. Developers using Apache can speed app development with support for whatever requirements their organization has.
It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more. SageMaker offers a comprehensive set of tools and capabilities for the entire machine-learning lifecycle.
Here are some of the essential tools and platforms that you need to consider: Cloud platforms Cloud platforms such as AWS , Google Cloud , and Microsoft Azure provide a range of services and tools that make it easier to develop, deploy, and manage AI applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content