This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Within the ever-evolving cloud computing scene, Microsoft Azure stands out as a strong stage that provides a wide range of administrations that disentangle applications’ advancement, arrangement, and administration.
For instance, Berkeley’s Division of Data Science and Information points out that entry level data science jobs remote in healthcare involves skills in NLP (Natural Language Processing) for patient and genomic dataanalysis, whereas remote data science jobs in finance leans more on skills in risk modeling and quantitative analysis.
By working on real datasets and deploying applications on platforms like Azure and Hugging Face, you will gain valuable practical experience that reinforces your learning. You get a chance to work on various projects that involve practical exercises with vector databases, embeddings, and deployment frameworks.
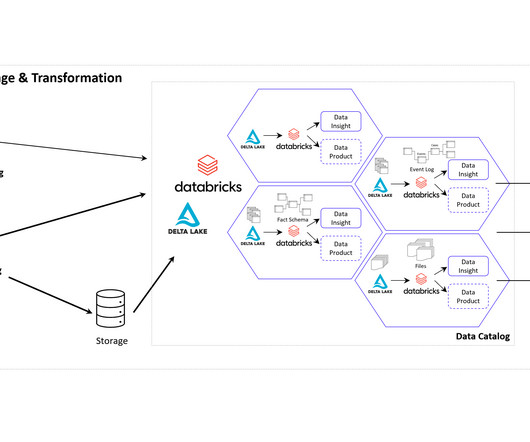
Companies use Business Intelligence (BI), Data Science , and Process Mining to leverage data for better decision-making, improve operational efficiency, and gain a competitive edge. One of this aspect is the cloud architecture for the realization of Data Mesh. See this as an example which has many possible alternatives.
Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like dataanalysis, fraud detection, and machine learning. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing.
Each platform offers unique capabilities tailored to varying needs, making the platform a critical decision for any Data Science project. Major Cloud Platforms for Data Science Amazon Web Services ( AWS ), Microsoft Azure, and Google Cloud Platform (GCP) dominate the cloud market with their comprehensive offerings.
Google Releases a tool for Automated Exploratory DataAnalysis Exploring data is one of the first activities a data scientist performs after getting access to the data. This command-line tool helps to determine the properties and quality of the data as well the predictive power. Courses & Learning.
Industry-recognised certifications, like IBM and AWS, provide credibility. Who is a Data Analyst? A Data Analyst collects, processes, and interprets data to help organisations make informed decisions. Key Features: Hands-on Training: Covers real-world DataAnalysis methodologies, SQL , Python, and visualisation.
The lower part of the iceberg is barely visible to the normal analyst on the tool interface, but is essential for implementation and success: this is the Event Log as the data basis for graph and dataanalysis in Process Mining. The creation of this data model requires the data connection to the source system (e.g.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
Redshift is the product for data warehousing, and Athena provides SQL data analytics. AWS Glue helps users to build data catalogues, and Quicksight provides data visualisation and dashboard construction. The services from AWS can be catered to meet the needs of each business user. Microsoft Azure.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. The top certification was for AWS (3.9%
How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
For enjoying all the benefits that IoT technologies can offer us today, it is vital to find a place where all the gathered data will be kept. Usually, companies choose a platform provided by one of the most well-known vendors like Amazon (AWS), Google Cloud, or Microsoft Azure. Proceed to dataanalysis.
Being able to discover connections between variables and to make quick insights will allow any practitioner to make the most out of the data. Analytics and DataAnalysis Coming in as the 4th most sought-after skill is data analytics, as many data scientists will be expected to do some analysis in their careers.
For example, the Google Earth API can be used to access Landsat , MODIS , VIIRS , GEDI , and SMAP data. To get started, check out the Earth Engine installation instructions and Python API introduction VEDA Dashboard : VEDA (Visualization, Exploration, and DataAnalysis) is NASA's open-source Earth Science platform in the cloud.
With the amount of increase in data, the complexity of managing data only keeps increasing. It has been found that data professionals end up spending 75% of their time on tasks other than dataanalysis. Advantages of data fabrication for data management. Data quality and governance.
Colab allows anybody to write and execute arbitrary python code through the browser, and is especially well suited to machine learning, dataanalysis and education. More technically, Colab is a hosted Jupyter notebook service that requires no setup to use, while providing access free of charge to computing resources including GPUs”.
These communities will help you to be updated in the field, because there are some experienced data scientists posting the stuff, or you can talk with them so they will also guide you in your journey. DataAnalysis After learning math now, you are able to talk with your data.
Unlike traditional cloud computing, where data is sent to centralized data centers, edge computing brings processing closer to the data source. This proximity significantly reduces latency and enhances real-time dataanalysis, making it indispensable for applications like IoT, autonomous vehicles, smart cities, and more.
Here is a short list of the possibilities built-in loaders allow: loading specific file types (JSON, CSV, pdf) or a folder path (DirectoryLoader) in general with selected file types use pre-existent integration with cloud providers (Azure, AWS, Google, etc.) connect to applications (Slack, Notion, Figma, Wikipedia, etc.).
Here’s a list of key skills that are typically covered in a good data science bootcamp: Programming Languages : Python : Widely used for its simplicity and extensive libraries for dataanalysis and machine learning. R : Often used for statistical analysis and data visualization.
Back-end System for Data Acquisition, Storage, and Analytics. Amazon, for instance, provides an entire suite of services that allow developers to integrate connectivity into hardware, design scalable home automation solutions , and apply advanced machine learning algorithms while conducting sensor dataanalysis.
Knowing how spaCy works means little if you don’t know how to apply core NLP skills like transformers, classification, linguistics, question answering, sentiment analysis, topic modeling, machine translation, speech recognition, named entity recognition, and others. Google Cloud is starting to make a name for itself as well.
Navigate through 6 Popular Python Libraries for Data Science R R is another important language, particularly valued in statistics and dataanalysis, making it useful for AI applications that require intensive data processing. Python’s versatility allows AI engineers to develop prototypes quickly and scale them with ease.
We looked at over 25,000 job descriptions, and these are the data analytics platforms, tools, and skills that employers are looking for in 2023. Excel is the second most sought-after tool in our chart as you’ll see below as it’s still an industry standard for data management and analytics.
As an open-source system, Kubernetes services are supported by all the leading public cloud providers, including IBM, Amazon Web Services (AWS), Microsoft Azure and Google. While Docker includes its own orchestration tool, called Docker Swarm , most developers choose Kubernetes container orchestration instead.
Understanding the Challenges of Scaling Data Science Projects Successfully transitioning from Data Analyst to Data Science architect requires a deep understanding of the complexities that emerge when scaling projects. But as data volume and complexity increase, traditional infrastructure struggles to keep up.
A data warehouse enables advanced analytics, reporting, and business intelligence. The data warehouse emerged as a means of resolving inefficiencies related to data management, dataanalysis, and an inability to access and analyze large volumes of data quickly.
For this data scenario, the current flight delay data (2019 – 2022) is contained in a regular, internal NPS database table residing in an NPS as a Service (NPSaaS) instance within the U.S. The external table capability of NPS makes it transparent to a client that some of the data resides externally to the data warehouse.
Blind 75 LeetCode Questions - LeetCode Discuss Data Manipulation and Analysis Proficiency in working with data is crucial. This includes skills in data cleaning, preprocessing, transformation, and exploratory dataanalysis (EDA).
Key Skills Experience with cloud platforms (AWS, Azure). Proficiency in DataAnalysis tools for market research. Data Engineer Data Engineers build the infrastructure that allows data generation and processing at scale. Knowledge of tools like Pandas , NumPy , and big data frameworks (e.g.,
Top 50+ Interview Questions for Data Analysts Technical Questions SQL Queries What is SQL, and why is it necessary for dataanalysis? SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. How would you segment customers based on their purchasing behaviour?
It has a wide range of features, including data preprocessing, feature extraction, deep learning training, and model evaluation. Pandas: Pandas is a powerful dataanalysis library that makes it easy to work with datasets of any size or shape. To build a data science or machine learning project 2. To work with big data 7.
Augmented Analytics Augmented analytics is revolutionising the way businesses analyse data by integrating Artificial Intelligence (AI) and Machine Learning (ML) into analytics processes. Understand data structures and explore data warehousing concepts to efficiently manage and retrieve large datasets.
Microsoft Power BI – Power BI is a comprehensive suite of tools which allows you to visualize data and create interactive reports and dashboards. Tableau – Tableau is celebrated for its advanced data visualization and interactive dashboard features. You can also share insights across organizations.
AI users say that AI programming (66%) and dataanalysis (59%) are the most needed skills. How will AI adopters react when the cost of renting infrastructure from AWS, Microsoft, or Google rises? Given the cost of equipping a data center with high-end GPUs, they probably won’t attempt to build their own infrastructure.
For example, when it comes to deploying projects on cloud platforms, different companies may utilize different providers like AWS, GCP, or Azure. Therefore, having proficiency in a specific cloud platform, such as Azure, does not mean you will exclusively work with that platform in the industry.
Data Backup and Recovery : Have a data storage platform that supports a contingency plan for unexpected data loss and deletion, which can be quite common in a long-duration project. Data Compression : Explore data compression techniques to optimize storage space, primarily as long-term ML projects collect more data.
At the core of Data Science lies the art of transforming raw data into actionable information that can guide strategic decisions. Role of Data Scientists Data Scientists are the architects of dataanalysis. They clean and preprocess the data to remove inconsistencies and ensure its quality.
Many enterprises, large or small, are storing data in cloud object storage like AWS S3, Azure ADLS Gen2, or Google Bucket because it offers scalable and cost-effective solutions for managing vast amounts of data. However, there are business reasons why you need to start your dataanalysis with external tables.
Data Warehousing A data warehouse is a centralised repository that stores large volumes of structured and unstructured data from various sources. It enables reporting and DataAnalysis and provides a historical data record that can be used for decision-making.
How to use the Codex models to work with code - Azure OpenAI Service Codex is the model powering Github Copilot. GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. The article has good points with any LLM Use prompt to guide.
In the most generic terms, every project starts with raw data, which comes from observations and measurements i.e. it is directly downloaded from instruments. It can be gradually “enriched” so the typical hierarchy of data is thus: Raw data ↓ Cleaned data ↓ Analysis-ready data ↓ Decision-ready data ↓ Decisions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content