This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. Streamlined Collaboration Among Teams Data Warehouse Systems in the cloud often involve cross-functional teams — dataengineers, data scientists, and system administrators.
Familiarity with data preprocessing, feature engineering, and model evaluation techniques is crucial. Additionally, knowledge of cloud platforms (AWS, Google Cloud) and experience with deployment tools (Docker, Kubernetes) are highly valuable. This role builds a foundation for specialization.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
One of this aspect is the cloud architecture for the realization of Data Mesh. Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. It offers robust IoT and edge computing capabilities, advanced data analytics, and AI services.
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
Accordingly, one of the most demanding roles is that of AzureDataEngineer Jobs that you might be interested in. The following blog will help you know about the AzureDataEngineering Job Description, salary, and certification course. How to Become an AzureDataEngineer?
Data Lakehouses werden auf Cloud-basierten Objektspeichern wie Amazon S3 , Google Cloud Storage oder Azure Blob Storage aufgebaut. In einem Data Lakehouse werden die Daten in ihrem Rohformat gespeichert, und Transformationen und Datenverarbeitung werden je nach Bedarf durchgeführt. So basieren z.
For example, you might have acquired a company that was already running on a different cloud provider, or you may have a workload that generates value from unique capabilities provided by AWS. We show how you can build and train an ML model in AWS and deploy the model in another platform.
Data science and dataengineering are incredibly resource intensive. By using cloud computing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
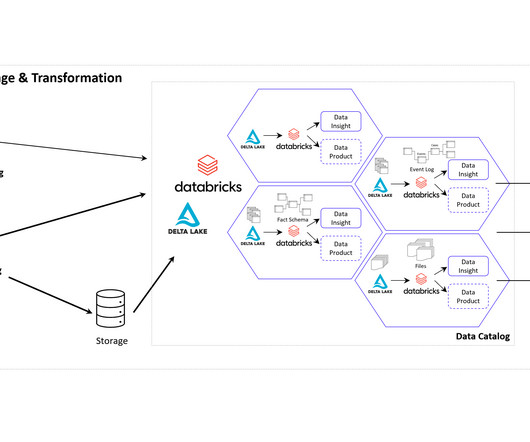
The creation of this data model requires the data connection to the source system (e.g. SAP ERP), the extraction of the data and, above all, the data modeling for the event log. DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Central data models in a cloud-based Data Mesh Architecture (e.g.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Azure Active Directory (AD) is a popular identity and access management service provided by Microsoft which works well as a Single Sign On (SSO) for the Snowflake Data Cloud. In this blog post, we will guide you through the steps of connecting Azure AD SCIM to Snowflake and provide some tips and tricks for ease of implementation.
One of them is Azure functions. In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. A batch ETL works under a predefined schedule in which the data are processed at specific points in time.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
In this blog, we’re going to try our best to remove as much of the uncertainty as possible by walking through the interview process here at phData for DataEngineers. Whether you’re officially job hunting or just curious about what it’s like to interview and work at phData as a DataEngineer, this is the blog for you!
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloud computing resources. Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options.
auf den Analyse-Ressourcen der Microsoft Azure Cloud oder in auf der databricks-Plattform. Gemeinsam haben sie alle die Funktion als Zwischenebene zwischen den Datenquellen und den Process Mining, BI und Data Science Applikationen. Umgesetzt werden diese Anwendungsfälle bisher vor allem auf dritten Plattformen, wie z.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. The top certification was for AWS (3.9%
Scale is worth knowing if you’re looking to branch into dataengineering and working with big data more as it’s helpful for scaling applications. Cloud Services The only two to make multiple lists were Amazon Web Services (AWS) and Microsoft Azure.
The Biggest Data Science Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
Length of Interview: 30 – 45 minutes Interview 2: Leadership In this interview, you will meet with the Director of the Solutions Engineering team. The discussion points in this interview will include a review of your current experience as it relates to cloud dataengineering and solution engineering.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. The first insert statement loads data having c_custkey between 30001 and 40000 – INSERT INTO ib_customers2 SELECT *, '11111111111111' AS HASHKEY FROM snowflake_sample_data.tpch_sf1.customer
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? The post Data Science Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
This article was published as a part of the Data Science Blogathon. In this article, we shall discuss the upcoming innovations in the field of artificial intelligence, big data, machine learning and overall, Data Science Trends in 2022. Times change, technology improves and our lives get better.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. DataEngineering Platforms Spark is still the leader for data pipelines but other platforms are gaining ground. Google Cloud is starting to make a name for itself as well.
Hello, fellow data science enthusiasts, did you miss imparting your knowledge in the previous blogathon due to a time crunch? Well, it’s okay because we are back with another blogathon where you can share your wisdom on numerous data science topics and connect with the community of fellow enthusiasts.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
One big issue that contributes to this resistance is that although Snowflake is a great cloud data warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
Key roles include Data Scientist, Machine Learning Engineer, and DataEngineer. Data Scientists use programming languages like Python and R to analyze large datasets and develop models that predict outcomes. DataEngineers design and manage the data architecture, ensuring its optimized for analysis.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Fivetran works with all three Snowflake cloud providers.
Since data is left in its raw form within the data lake, it’s easier for data teams to experiment with models and analysis techniques with greater flexibility. So let’s take a look at a few of the leading industry examples of data lakes. Snowflake Snowflake is a cross-cloud platform that looks to break down data silos.
You can adopt these strategies as well as focus on continuous learning to upscale your knowledge and skill set. Leverage Cloud Platforms Cloud platforms like AWS, Azure, and GCP offer a suite of scalable and flexible services for data storage, processing, and model deployment.
Enterprise data architects, dataengineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. 2) When data becomes information, many (incremental) use cases surface.
(By the way, if you’re interested in diving deeper, Ricard and colleagues described this setup in more detail on the AWS Machine Learning Blog.) The documentation is poor, and you need people from AWS to tell you how it works. This means that the more AWS services you use along with SageMaker, the better it becomes.
Fivetran then consumes data from these functions and writes to the desired source, along with all the perks that Fivetran offers. At the time of writing this article, Fivetran supports cloud function connectors for Amazon Web Services (AWS), Microsoft Azure, and Google Cloud.
While a data analyst isn’t expected to know more nuanced skills like deep learning or NLP, a data analyst should know basic data science, machine learning algorithms, automation, and data mining as additional techniques to help further analytics. Cloud Services: Google Cloud Platform, AWS, Azure.
Integration : Can it connect with existing systems like AWS, Azure, or Google Cloud? The Top List of ETL Tools In the world of data management, Extract, Transform, Load (ETL) tools play a crucial role in enabling organizations to efficiently process and analyse large volumes of data.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. IBM Turbonomic is a software platform that helps organizations improve the performance and reduce the cost of their IT infrastructure, including public , private and hybrid cloud environments.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Read Further: AzureDataEngineer Jobs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content