This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Microsoft Azure. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service.
Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses. Ein Lakehouse inkludiert auch clevere Art und Weise auch einen DataLake. Ein DataLake ist dann sowas wie die eine böse Schublade, die man eigentlich gar nicht haben möchte, aber in die man dann alle Briefe, Dokumente usw.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
Azure Synapse. Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and AzureDataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. R Support for Azure Machine Learning. Azure Quantum.
AzureData Factory Preserves Metadata during File Copy When performing a File copy between Amazon S3, Azure Blob, and AzureDataLake Gen 2, the metadata will be copied as well. Azure Database for MySQL now supports MySQL 8.0 This is the latest major version of MySQL Azure Functions 3.0
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
Accordingly, one of the most demanding roles is that of AzureData Engineer Jobs that you might be interested in. The following blog will help you know about the AzureData Engineering Job Description, salary, and certification course. How to Become an AzureData Engineer?
One of them is Azure functions. In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. A batch ETL works under a predefined schedule in which the data are processed at specific points in time.
Most enterprises today store and process vast amounts of data from various sources within a centralized repository known as a data warehouse or datalake, where they can analyze it with advanced analytics tools to generate critical business insights.
How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. Solution overview Figure 1 – Solution Architecture Enable Amazon Security Lake with AWS Organizations for AWS accounts, AWS Regions, and external IT environments.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Data integration: Integrate data from various sources into a centralized cloud data warehouse or datalake. Ensure that data is clean, consistent, and up-to-date.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. Data fabric: A mostly new architecture.
Big data isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed. This pushes into big data as well, as many companies now have significant amounts of data and large datalakes that need analyzing.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch. All cloud providers provide commercial solutions as well, such as AWS Sagemaker or Azure ML Studio.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Fivetran works with all three Snowflake cloud providers.
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud datalake or data warehouse. File – Fivetran offers several options to sync files to your destination.
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
Enterprise IT admins can configure access to features and data at an instance, workspace, or role level by leveraging a ccess control rules. Snorkel automatically provisions those users with locked-down feature & data access to a set of permissioned workspaces.
Snowflake-managed Iceberg table’s performance is at par with Snowflake native tables while storing the data in public cloud storage. They are Ideal for situations where the data is already stored in datalakes and do not intend to load into Snowflake but need to use the features and performance of Snowflake.
Data analysts often must go out and find their data, process it, clean it, and get it ready for analysis. This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. Cloud Services: Google Cloud Platform, AWS, Azure.
Data Ingestion Meaning At its core, It refers to the act of absorbing data from multiple sources and transporting it to a destination, such as a database, data warehouse, or datalake. Batch Processing In this method, data is collected over a period and then processed in groups or batches.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
So as you take inventory of your existing skill set, you’ll want to start to identify the areas where you need to focus on to become a data engineer. These areas may include SQL, database design, data warehousing, distributed systems, cloud platforms (AWS, Azure, GCP), and data pipelines.
It can be used to store data outside the database while retaining the ability to query its data. These files need to be in one of the Snowflake-supported cloud systems: Amazon S3, Google Cloud Storage, or Microsoft Azure Blob storage. What are Directory Tables in Snowflake?
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
This functionality provides access to data by storing it in an open format, increasing flexibility for data exploration and ML modeling used by data scientists, facilitating governed data use of unstructured data, improving collaboration, and reducing data silos with simplified datalake integration.
These processes are essential in AI-based big data analytics and decision-making. DataLakesDatalakes are crucial in effectively handling unstructured data for AI applications. They serve as centralized repositories where raw data, whether structured or unstructured, can be stored in its native format.
The post The Move to Public Cloud and an Intelligent Data Strategy appeared first on DATAVERSITY. Click to learn more about author Joe Gaska. It has taken a global pandemic for organizations to finally realize that the old way of doing businesses – and the legacy technologies and processes that came with it – are no longer going to cut it.
Cloud ETL Pipeline: Cloud ETL pipeline for ML involves using cloud-based services to extract, transform, and load data into an ML system for training and deployment. Cloud providers such as AWS, Microsoft Azure, and GCP offer a range of tools and services that can be used to build these pipelines.
The software you might use OAuth with includes: Tableau Power BI Sigma Computing If so, you will need an OAuth provider like Okta, Microsoft Azure AD, Ping Identity PingFederate, or a Custom OAuth 2.0 When to use SCIM vs phData's Provision Tool SCIM manages users and groups with Azure Active Directory or Okta. authorization server.
This typically involves dealing with complexities such as ensuring secure and simple access to internal data warehouses, datalakes, and databases. Some of the most widely adopted tools in this space are Deepnote , Amazon SageMaker , Google Vertex AI , and Azure Machine Learning. Aside neptune.ai
Organizations that want to build their own models or want granular control are choosing Amazon Web Services (AWS) because we are helping customers use the cloud more efficiently and leverage more powerful, price-performant AWS capabilities such as petabyte-scale networking capability, hyperscale clustering, and the right tools to help you build.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. DataRobot Data Prep. free trial.
If your organization runs its workloads on AWS , it might be worth it to leverage AWS SageMaker. Solution Datalakes and warehouses are the two key components of any data pipeline. The datalake is a platform where any kind or amount of data can be stored, processed, and analyzed.
And the highlight, for us data intelligence folks, was the Databricks’ announcement that Unity Catalog , its unified governance solution for all data assets on its Lakehouse platform, will soon be available on AWS and Azure in the upcoming weeks. A simple model to control access to data via a UI or SQL.
Amazon EMR (Elastic MapReduce) Amazon EMR is a cloud-native Big Data platform that simplifies running Big Data frameworks such as Apache Hadoop and Apache Spark on AWS. Statistics : According to AWS reports, EMR reduces the time required for Big Data processing tasks by up to 90% compared to traditional methods.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























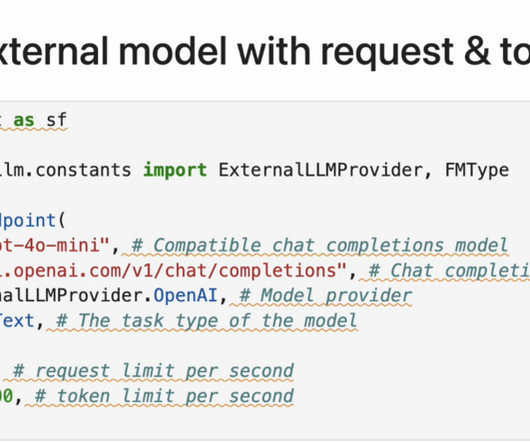
























Let's personalize your content