This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
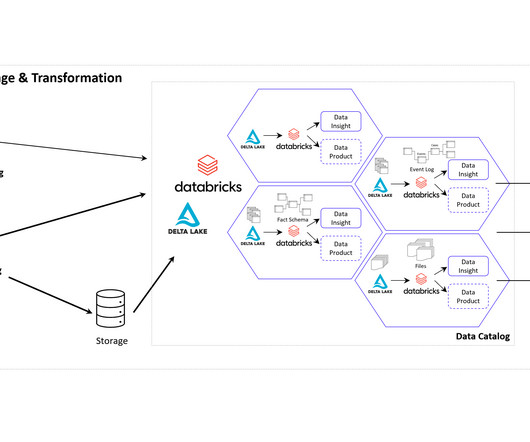
One of this aspect is the cloud architecture for the realization of Data Mesh. Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. It offers robust IoT and edge computing capabilities, advanced data analytics, and AI services.
This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern. Of course, Terraform and the Azure CLI needs to be installed before.
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with datamodeling and ETL processes.
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Understanding how data warehousing works and how to design and implement a data warehouse is an important skill for a data engineer. Learn about datamodeling: Datamodeling is the process of creating a conceptual representation of data.
Accordingly, one of the most demanding roles is that of AzureData Engineer Jobs that you might be interested in. The following blog will help you know about the AzureData Engineering Job Description, salary, and certification course. How to Become an AzureData Engineer?
You can only deploy DynamoDB on Amazon Web Services (AWS), and it does not support on-premise deployments. With DynamoDB, you are essentially locked into AWS as your cloud provider. MongoDB is deployable anywhere, and the MongoDB Atlas database-as-a-service can be deployed on AWS, Azure, and Google Cloud Platform (GCP).
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
One big issue that contributes to this resistance is that although Snowflake is a great cloud data warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
Key features of cloud analytics solutions include: Datamodels , Processing applications, and Analytics models. Datamodels help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for business intelligence.
We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
That’s why our data visualization SDKs are database agnostic: so you’re free to choose the right stack for your application. Multi-model databases combine graphs with two other NoSQL datamodels – document and key-value stores. Transactional, analytical, or both…?
Microsoft Power BI – Power BI is a comprehensive suite of tools which allows you to visualize data and create interactive reports and dashboards. Tableau – Tableau is celebrated for its advanced data visualization and interactive dashboard features. You can also share insights across organizations.
Claims data is often noisy, unstructured, and multi-modal. Manually aligning and labeling this data is laborious and expensive, but—without high-quality representative training data—models are likely to make errors and produce inaccurate results.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Claims data is often noisy, unstructured, and multi-modal. Manually aligning and labeling this data is laborious and expensive, but—without high-quality representative training data—models are likely to make errors and produce inaccurate results.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Read Further: AzureData Engineer Jobs.
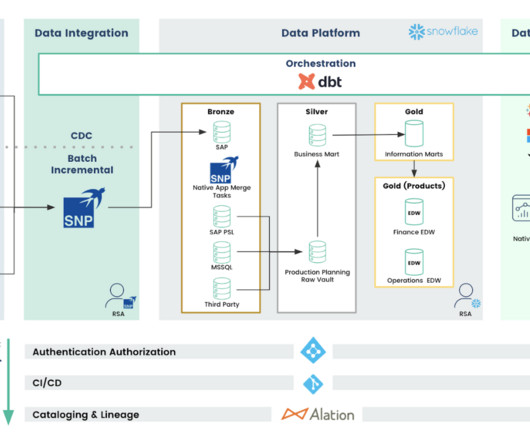
By centralizing SAP ERP data in Snowflake, organizations can gain deeper insights into key business metrics, trends, and performance indicators, enabling more informed decision-making, strategic planning, and operational optimization. SAP is relatively easy to work with. What is SNP Glue?
Claims data is often noisy, unstructured, and multi-modal. Manually aligning and labeling this data is laborious and expensive, but—without high-quality representative training data—models are likely to make errors and produce inaccurate results.
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. diagram Using ChatGPT to build system diagrams — Part II Generate C4 diagrams using mermaid.js
Processing speeds were considerably slower than they are today, so large volumes of data called for an approach in which data was staged in advance, often running ETL (extract, transform, load) processes overnight to enable next-day visibility to key performance indicators.
Model Evaluation and Tuning After building a Machine Learning model, it is crucial to evaluate its performance to ensure it generalises well to new, unseen data. Model evaluation and tuning involve several techniques to assess and optimise model accuracy and reliability.
Skills and Tools of Data Engineers Data Engineering requires a unique set of skills, including: Database Management: SQL, NoSQL, NewSQL, etc. Data Warehousing: Amazon Redshift, Google BigQuery, etc. DataModeling: Entity-Relationship (ER) diagrams, data normalization, etc.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Model Deployment and Serving Platforms Some of the most popular tools for development, serving and scaling are as follows: Amazon SageMaker Developed by Amazon Web Services (AWS) , Amazon Sagemaker is a fully managed machine learning service that allows developers and data scientists to build, train, and deploy machine learning models at scale.
Predictive Analytics : Models that forecast future events based on historical data. Model Repository and Access Users can browse a comprehensive library of pre-trained models tailored to specific business needs, making it easy to find the right solution for various applications.
As a fully managed service, Snowflake eliminates the need for infrastructure maintenance, differentiating itself from traditional data warehouses by being built from the ground up. It can be hosted on major cloud platforms like AWS, Azure, and GCP. These models are designed to run instantly after syncing data with the Source.
The gateway is designed to handle both internal LLMs (like Llama, Falcon, or models fine-tuned in-house) and external APIs (such as OpenAI, Google, or AWS Bedrock). LLM Gateways can enforce security policies, encrypt sensitive information, and manage access control to protect data. Your team only needs to learn one system.
Now that we understand visibility shares vital details of the model, let us learn what the barriers to visibility are: Decoupled pieces: The data, code, configuration, and results are generated at different steps during the project. But it is not built with machine learning models in mind.
NoSQL Databases NoSQL databases do not follow the traditional relational database structure, which makes them ideal for storing unstructured data. They allow flexible datamodels such as document, key-value, and wide-column formats, which are well-suited for large-scale data management.
For example, an experiment name like 'ResNet50-augmented-imagenet-exp-01' provides more information about the model architecture, dataset, and experiment number. DVC Data Version Control (DVC) is an open-source version control system that is specially designed to track not just code, but also data, models, and machine learning pipelines.
Data can change a lot, models may also quickly evolve and dependencies become old-fashioned which makes it hard to maintain consistency or reproducibility. With weak version control, teams could face problems like inconsistent data, model drift , and clashes in their code. or other dedicated backup servers.
It’s about more than just looking at one project; dbt Explorer lets you see the lineage across different projects, ensuring you can track your data’s journey end-to-end without losing track of the details. These jobs can be triggered via schedule or events, ensuring your data assets are always up-to-date.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? Platforms like AzureData Lake and AWS Lake Formation can facilitate big data and AI processing.
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization.
When training the models on this type of data, models can be biased towards some text while ignoring others. Solution To solve the potential bias in the training data, you can start with debiasing techniques. Solution There are several solutions for deploying a sentiment classification model.
It’s almost like a specialized data processing and storage solution. For example, you can use BigQuery , AWS , or Azure. I think a lot of times there’s this weird antagonism between ML/MLOps engineers, software engineers, and data scientists where it’s like, “Oh, data scientists are just terrible at coding.
These two languages cover most data science workflows. Additionally, languages like DAX can be helpful for specific use cases involving datamodels and dashboards. Model deployment: The ability to build applications that operationalize models, such as Flask or Django apps, is increasingly vital.
It integrates well with various data sources, making analysis easier. dbt (Data Build Tool) dbt is a data transformation tool that allows engineers to manage and automate SQL-based workflows. It simplifies datamodelling and transformation processes, making it easier to maintain data pipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content