This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
Confluent Confluent provides a robust data streaming platform built around Apache Kafka. AI credits from Confluent can be used to implement real-time datapipelines, monitor data flows, and run stream-based ML applications.
Each platform offers unique capabilities tailored to varying needs, making the platform a critical decision for any Data Science project. Major Cloud Platforms for Data Science Amazon Web Services ( AWS ), Microsoft Azure, and Google Cloud Platform (GCP) dominate the cloud market with their comprehensive offerings.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine. Conclusion.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. Subscribe an AWS Lambda function to the SQS queue.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. The top certification was for AWS (3.9%
A data fabric solution must be capable of optimizing code natively using preferred programming languages in the datapipeline to be easily integrated into cloud platforms such as Amazon Web Services, Azure, Google Cloud, etc. This will enable the users to seamlessly work with code while developing datapipelines.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Google Cloud is starting to make a name for itself as well.
How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
One big issue that contributes to this resistance is that although Snowflake is a great cloud data warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
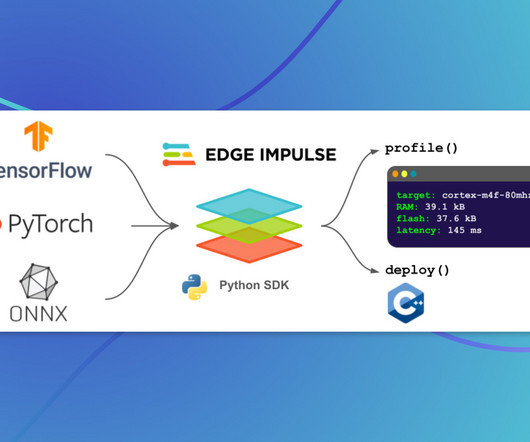
We sketch out ideas in notebooks, build datapipelines and training scripts, and integrate with a vibrant ecosystem of Python tools. Edge Impulse provides powerful automations and low-code capabilities to make it easier to build valuable datasets and develop advanced AI with streaming data.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Cloud Services The only two to make multiple lists were Amazon Web Services (AWS) and Microsoft Azure. Most major companies are using one of the two, so excelling in one or the other will help any aspiring data scientist. Saturn Cloud is picking up a lot of momentum lately too thanks to its scalability.
The phData team achieved a major milestone by successfully setting up a secure end-to-end datapipeline for a substantial healthcare enterprise. Our team frequently configures Fivetran connectors to cloud object storage platforms such as Amazon S3, Azure Blob Storage, and Google Cloud Storage.
If using a network policy with Snowflake, be sure to add Fivetran’s IP address list , which will ensure AzureData Factory (ADF) AzureData Factory is a fully managed, serverless data integration service built by Microsoft. Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.).
It supports both batch and real-time data processing , making it highly versatile. Its ability to integrate with cloud platforms like AWS and Azure makes it an excellent choice for businesses moving to the cloud. Apache Nifi Apache Nifi is an open-source ETL tool that automates data flow between systems.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. 3) Data professionals come in all shapes and forms.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Read Further: AzureData Engineer Jobs.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
Feature Big DataData Science Primary Focus Handling the characteristics of data (Volume, Velocity, Variety, Veracity) Extracting knowledge and insights from data Nature The data itself and the infrastructure to manage it The process and methods for analysing data Core Goal To store, process, and manage massive datasets efficiently To understand, interpret, (..)
Some projects manage this folder like the data folder and sync it to a canonical store (e.g., AWS S3) separately from source code. Data storage ¶ V1 was designed to encourage data scientists to (1) separate their data from their codebase and (2) store their data on the cloud.
It includes a range of technologies—including machine learning frameworks, datapipelines, continuous integration / continuous deployment (CI/CD) systems, performance monitoring tools, version control systems and sometimes containerization tools (such as Kubernetes )—that optimize the ML lifecycle.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
Integration : Can it connect with existing systems like AWS, Azure, or Google Cloud? Airflow is particularly useful for organizations that require flexibility and scalability in their datapipelines. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
Apache Kafka For data engineers dealing with real-time data, Apache Kafka is a game-changer. This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time.
The software you might use OAuth with includes: Tableau Power BI Sigma Computing If so, you will need an OAuth provider like Okta, Microsoft Azure AD, Ping Identity PingFederate, or a Custom OAuth 2.0 When to use SCIM vs phData's Provision Tool SCIM manages users and groups with Azure Active Directory or Okta. authorization server.
The external stage area includes Microsoft Azure Blob storage, Amazon AWS S3, and Google Cloud Storage. Amazon S3 for AWS, Azure Blob Storage for Azure, or Google Cloud Storage for GCP) to store the actual data files in micro-partitions. They are flexible, secure, and provide exceptional performance.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. The Salesforce Sync Out connector moves Salesforce data directly into Snowflake, simplifying the datapipeline and reducing latency.
This includes important stages such as feature engineering, model development, datapipeline construction, and data deployment. For example, when it comes to deploying projects on cloud platforms, different companies may utilize different providers like AWS, GCP, or Azure.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently.
First, private cloud infrastructure providers like Amazon (AWS), Microsoft (Azure), and Google (GCP) began by offering more cost-effective and elastic resources for fast access to infrastructure. Instead of moving customer data to the processing engine, we move the processing engine to the data.
DataRobot now delivers both visual and code-centric data preparation and datapipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Modular and Extensible, Building on Existing Investments.
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. If your datapipeline requirements are quite straightforward—i.e., You have different developers working on building datapipelines/UDFs/stored procedures in the same environment.
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. Implementation of metadata-driven datapipelines for governance and reporting. This is where AI truly shines.
Dolt LakeFS Delta Lake Pachyderm Git-like versioning Database tool Data lake Datapipelines Experiment tracking Integration with cloud platforms Integrations with ML tools Examples of data version control tools in ML DVC Data Version Control DVC is a version control system for data and machine learning teams.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content