This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
First, private cloud infrastructure providers like Amazon (AWS), Microsoft (Azure), and Google (GCP) began by offering more cost-effective and elastic resources for fast access to infrastructure. Now, almost any company can build a solid, cost-effective data analytics or BI practice grounded in these new cloud platforms.
Redshift is the product for data warehousing, and Athena provides SQL data analytics. AWS Glue helps users to build data catalogues, and Quicksight provides data visualisation and dashboard construction. The services from AWS can be catered to meet the needs of each business user. Microsoft Azure.
A data fabric solution must be capable of optimizing code natively using preferred programming languages in the data pipeline to be easily integrated into cloud platforms such as Amazon Web Services, Azure, Google Cloud, etc. This will enable the users to seamlessly work with code while developing data pipelines.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Understand what insights you need to gain from your data to drive business growth and strategy. Use ETL (Extract, Transform, Load) processes or data integration tools to streamline data ingestion.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
These models allow large enterprises to tier and scale their AWS Accounts, Azure Subscriptions, and Google Projects across hundreds and thousands of cloud users and services. The deliverability of cloud governance models has improved as public cloud usage continues to grow and mature. When we first started […].
Talend Talend is a leading open-source ETL platform that offers comprehensive solutions for data integration, dataquality , and cloud data management. It supports both batch and real-time data processing , making it highly versatile. ADF allows users to create complex ETL pipelines using a drag-and-drop interface.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. This process involves extracting data from multiple sources, transforming it into a consistent format, and loading it into the data warehouse. ETL is vital for ensuring dataquality and integrity.
Assessment Evaluate the existing dataquality and structure. This step involves identifying any data cleansing or transformation needed to ensure compatibility with the target system. Assessing dataquality upfront can prevent issues later in the migration process.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Read Further: AzureData Engineer Jobs.
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Techniques such as data cleansing, aggregation, and trend analysis play a critical role in ensuring dataquality and relevance.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Our ability to catalog every data asset means that we can partner with other ISVs in dataquality and observability, like BigEye and Soda ; privacy, like BigID and OneTrust; access governance, like Immuta and Privacera; not to mention the core platforms, like Snowflake , Databricks , AWS , GCP, and Azure.
Summary: Data ingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances dataquality, enables real-time insights, and supports informed decision-making. It provides a user-friendly interface for designing data flows.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality. Why is ETL Important for Businesses?
Thankfully, there are tools available to help with metadata management, such as AWS Glue, AzureData Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
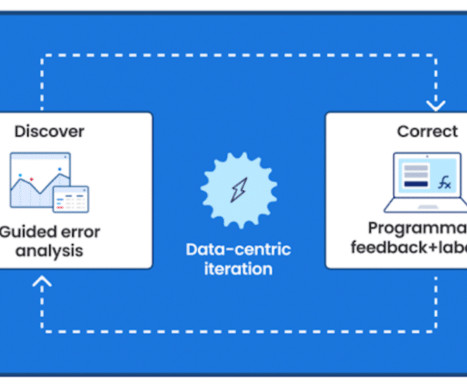
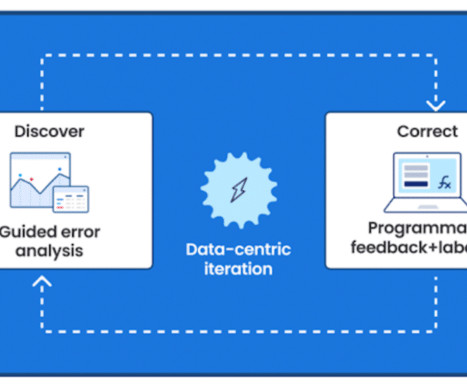
Snorkel offers enterprise-grade security in the SOC2-certified Snorkel Cloud , as well as partnerships with Google Cloud, Microsoft Azure, AWS, and other leading cloud providers. Snorkel’s data-centric approach and user-friendly platform can vastly simplify the training and deployment of credit-scoring models.
The same can be said of other leading platforms such as Databricks, Cloudera, and data lakes offered by the major cloud providers such as AWS, Google, and Microsoft Azure. Precisely helps enterprises manage the integrity of their data. Hadoop and Snowflake represent tremendous advances in analytics capabilities.
Snorkel offers enterprise-grade security in the SOC2-certified Snorkel Cloud , as well as partnerships with Google Cloud, Microsoft Azure, AWS, and other leading cloud providers. Snorkel’s data-centric approach and user-friendly platform can vastly simplify the training and deployment of credit-scoring models.
This section explores the essential steps in preparing data for AI applications, emphasising dataquality’s active role in achieving successful AI models. Importance of Data in AI Qualitydata is the lifeblood of AI models, directly influencing their performance and reliability.
Data Integration and ETL (Extract, Transform, Load) Data Engineers develop and manage data pipelines that extract data from various sources, transform it into a suitable format, and load it into the destination systems. DataQuality and Governance Ensuring dataquality is a critical aspect of a Data Engineer’s role.
Here are some specific reasons why they are important: Data Integration: Organizations can integrate data from various sources using ETL pipelines. This provides data scientists with a unified view of the data and helps them decide how the model should be trained, values for hyperparameters, etc.
Cloud platforms like AWS , Google Cloud Platform (GCP), and Microsoft Azure provide managed services for Machine Learning, offering tools for model training, storage, and inference at scale. Scalability Considerations Scalability is a key concern in model deployment.
To help, phData designed and implemented AI-powered data pipelines built on the Snowflake AI Data Cloud , Fivetran, and Azure to automate invoice processing. This is where AI truly shines. phData’s Approach One of our largest financial services customers was struggling to keep up with the growing demand for invoice processing.
But by partnering with a professional consultant in dataquality management systems, forward-thinking enterprises gain a significant competitive edge over their competitors. Amazon Web Services (AWS). Microsoft Azure. Let’s start with some simple definitions. What is cloud-native? Google Cloud Platform (GCP).
How will AI adopters react when the cost of renting infrastructure from AWS, Microsoft, or Google rises? Given the cost of equipping a data center with high-end GPUs, they probably won’t attempt to build their own infrastructure. Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3%
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
Snorkel offers enterprise-grade security in the SOC2-certified Snorkel Cloud , as well as partnerships with Google Cloud, Microsoft Azure, AWS, and other leading cloud providers. Snorkel’s data-centric approach and user-friendly platform can vastly simplify the training and deployment of credit-scoring models.
I break down the problem into smaller manageable tasks, define clear objectives, gather relevant data, apply appropriate analytical techniques, and iteratively refine the solution based on feedback and insights. Describe a situation where you had to think creatively to solve a data-related challenge.
Here are some of the essential tools and platforms that you need to consider: Cloud platforms Cloud platforms such as AWS , Google Cloud , and Microsoft Azure provide a range of services and tools that make it easier to develop, deploy, and manage AI applications. How to improve your dataquality in four steps?
They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for big data applications. Popular data lake solutions include Amazon S3 , AzureData Lake , and Hadoop. Data Processing Tools These tools are essential for handling large volumes of unstructured data.
In general, this data has no clear structure because it may manifest real-world complexity, such as the subtlety of language or the details in a picture. Advanced methods are needed to process unstructured data, but its unstructured nature comes from how easily it is made and shared in today's digital world.
You can use a pre-trained model and fine-tune it on your specific dataset, then deploy it on a cloud platform such as AWS , Google Cloud , or Azure. This is why you need to monitor the whole solution pipeline, dataquality, and model performance for a few months after the deployment.
Source: AWS re:Invent Storage: LLMs require a significant amount of storage space to store the model and the training data. This can be achieved by deploying LLMs in a cloud-based environment that allows for on-demand scaling of resources, such as Amazon Web Services (AWS) or Microsoft Azure.
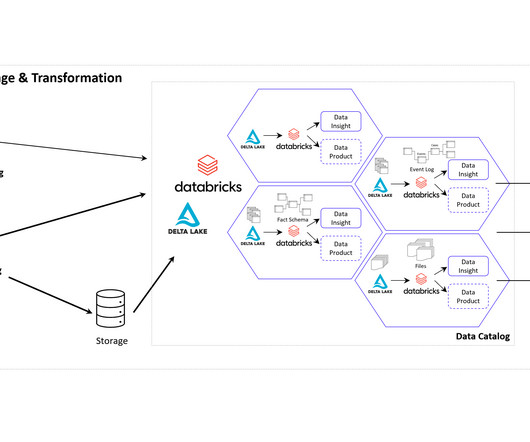
It advocates decentralizing data ownership to domain-oriented teams. Each team becomes responsible for its Data Products , and a self-serve data infrastructure is established. This enables scalability, agility, and improved dataquality while promoting data democratization.
DataQuality and Standardization The adage “garbage in, garbage out” holds true. Inconsistent data formats, missing values, and data bias can significantly impact the success of large-scale Data Science projects. This is crucial for building trust in models and addressing potential biases.
Scalability: DaaS allows businesses to scale up or down their data usage based on their needs without having to worry about the cost of building, maintaining, and updating data sources.
Scalability: DaaS allows businesses to scale up or down their data usage based on their needs without having to worry about the cost of building, maintaining, and updating data sources.
Therefore, the question is not if a business should implement cloud data management and governance, but which framework is best for them. Whether you’re using a platform like AWS, Google Cloud, or Microsoft Azure, data governance is just as essential as it is for on-premises data. DataQuality Metrics.
It’s about more than just looking at one project; dbt Explorer lets you see the lineage across different projects, ensuring you can track your data’s journey end-to-end without losing track of the details. These jobs can be triggered via schedule or events, ensuring your data assets are always up-to-date.
Embracing Automation: As already mentioned, the abstraction that the Modern Data Stack provides means that most of the infrastructure maintenance that would typically be required to maintain an enterprise data platform is automated away. Read more here.
Olalekan said that most of the random people they talked to initially wanted a platform to handle dataquality better, but after the survey, he found out that this was the fifth most crucial need. And when the platform automates the entire process, it’ll likely produce and deploy a bad-quality model.
A comprehensive assessment also highlights gaps in your current capabilities, such as insufficient dataquality or outdated systems, which need to be addressed before proceeding with implementation. Build a robust data infrastructure AIs performance depends heavily on the quality of data it processes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content