This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
At PeerDB, we are building a fast and a cost-effective way to replicate data from Postgres to DataWarehouses such as Snowflake, BigQuery, ClickHouse, Postgres and so on. All our customers run Postgres at the heart of the data stack, running fully ma.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
Introduction Google’s BigQuery is a powerful cloud-based datawarehouse that provides fast, flexible, and cost-effective data storage and analysis capabilities. BigQuery was created to analyse data […] The post Building a Machine Learning Model in BigQuery appeared first on Analytics Vidhya.
Schon damals in Ansätzen, aber spätestens heute gilt es zu recht als Best Practise, die Datenanbindung an ein DataWarehouse zu machen und in diesem die Daten für die Reports aufzubereiten. Ein DataWarehouse ist eine oder eine Menge von Datenbanken. Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses.
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Welcome to Cloud Data Science 8. This weeks news includes information about AWS working with Azure, time-series, detecting text in videos and more. Amazon Redshift now supports Authentication with Microsoft Azure AD Redshift, a datawarehouse, from Amazon now integrates with Azure Active Directory for login.
Datawarehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. datawarehouse. Read Many of the preferred platforms for analytics fall into one of these two categories.
Azure Synapse. Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and AzureData Lake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. R Support for Azure Machine Learning. Azure Quantum.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements. Conclusion.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Azure Functions now support Python 3.8 Amazon Redshift now has Pause and Resume Redshift, the datawarehouse, now has the ability to pause compute during unused times. This is big for Google. Announcing Tensorflow Quantum Google Announces an open source library for prototyping quantum machine learning models.
Accordingly, one of the most demanding roles is that of AzureData Engineer Jobs that you might be interested in. The following blog will help you know about the AzureData Engineering Job Description, salary, and certification course. How to Become an AzureData Engineer?
The extraction of raw data, transforming to a suitable format for business needs, and loading into a datawarehouse. Data transformation. This process helps to transform raw data into clean data that can be analysed and aggregated. Data analytics and visualisation. Microsoft Azure. SharePoint.
Understand data warehousing concepts: Data warehousing is the process of collecting, storing, and managing large amounts of data. Understanding how data warehousing works and how to design and implement a datawarehouse is an important skill for a data engineer.
auf den Analyse-Ressourcen der Microsoft Azure Cloud oder in auf der databricks-Plattform. Alternativ zu Databricks können auch andere DataWarehouse Datenbankplattformen zur Anwendung kommen, beispielsweise auch snowflake mit dbt. Umgesetzt werden diese Anwendungsfälle bisher vor allem auf dritten Plattformen, wie z.
Most enterprises today store and process vast amounts of data from various sources within a centralized repository known as a datawarehouse or data lake, where they can analyze it with advanced analytics tools to generate critical business insights.
One of them is Azure functions. In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. A batch ETL works under a predefined schedule in which the data are processed at specific points in time.
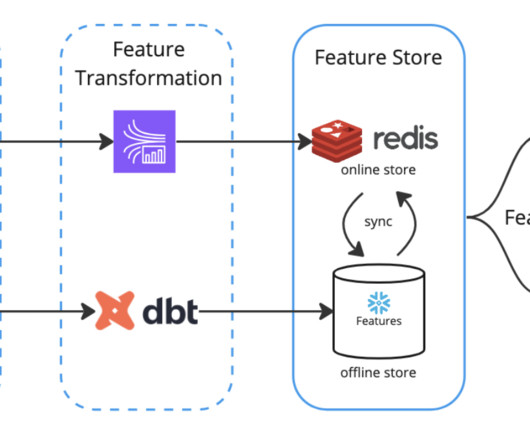
Feature stores capture features from enterprise datawarehouses or streaming applications in an online and offline store, syncing the values between the two stores. Feature stories can require the integration of diverse technologies, such as datawarehouses, streaming pipelines, and processing engines.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Downtime, like the AWS outage in 2017 that affected several high-profile websites, can disrupt business operations. Data integration: Integrate data from various sources into a centralized cloud datawarehouse or data lake. Ensure that data is clean, consistent, and up-to-date.
Data is at the core of any ML project, so data infrastructure is a foundational concern. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing datawarehouses. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch.
In a perfect world, Microsoft would have clients push even more storage and compute to its Azure Synapse platform. One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery).
Oracle – The Oracle connector, a database-type connector, enables real-time data transfer of large volumes of data from on-premises or cloud sources to the destination of choice, such as a cloud data lake or datawarehouse. File – Fivetran offers several options to sync files to your destination.
Azure Functions now support Python 3.8 Amazon Redshift now has Pause and Resume Redshift, the datawarehouse, now has the ability to pause compute during unused times. This is big for Google. Announcing Tensorflow Quantum Google Announces an open source library for prototyping quantum machine learning models.
ETL (Extract, Transform, Load) is a core process in data integration that involves extracting data from various sources, transforming it into a usable format, and loading it into a target system, such as a datawarehouse. It supports both batch and real-time data processing , making it highly versatile.
Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. It offers a cloud-agnostic data productivity hub called Matillion Data Productivity Cloud. Below is a sample scenario for 3 business units within an organization for the data mart layer of the datawarehouse.
Thankfully, there are tools available to help with metadata management, such as AWS Glue, AzureData Catalog, or Alation, that can automate much of the process. What are the Best Data Modeling Methodologies and Processes? Data lakes are meant to be flexible for new incoming data, whether structured or unstructured.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Introduction Struggling with expanding a business database due to storage, management, and data accessibility issues? To steer growth, employ effective data management strategies and tools. This article explores data management’s key tool features and lists the top tools for 2023.
Snowflake is one of the most powerful cloud-based datawarehouses on the market, offering a scalable solution built for analytics. However, when storing sensitive data in Snowflake, it’s crucial to implement every security measure possible to protect it from unauthorized access and potential breaches.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? So let’s take a look at a few of the leading industry examples of data lakes. Where does it go?
Some projects manage this folder like the data folder and sync it to a canonical store (e.g., AWS S3) separately from source code. Data storage ¶ V1 was designed to encourage data scientists to (1) separate their data from their codebase and (2) store their data on the cloud.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024. What is ETL?
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
Db2 can run on Red Hat OpenShift and Kubernetes environments, ROSA & EKS on AWS, and ARO & AKS on Azure deployments. Customers can also choose to run IBM Db2 database and IBM Db2 Warehouse as a fully managed service. Db2 database SaaS is a fully managed service for a high – performance, transactional workload.
Salesforce Sync Out is a crucial tool that enables businesses to transfer data from their Salesforce platform to external systems like Snowflake, AWS S3, and Azure ADLS. Warehouse for loading the data (start with XSMALL or SMALL warehouses).
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
This allows data that exists in cloud object storage to be easily combined with existing datawarehousedata without data movement. The advantage to NPS clients is that they can store infrequently used data in a cost-effective manner without having to move that data into a physical datawarehouse table.
Focus Area ETL helps to transform the raw data into a structured format that can be easily available for data scientists to create models and interpret for any data-driven decision. A data pipeline is created with the focus of transferring data from a variety of sources into a datawarehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content