This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction BigData is everywhere, and it continues to be a gearing-up topic these days. And Data Ingestion is a process that assists a group or management to make sense of the ever-increasing volume and complexity of data and provide useful insights.
Introduction In bigdata and advanced analytics, PySpark has emerged as a powerful tool for processing large datasets and analyzing distributed data. Deploying PySpark on AWS applications on the cloud can be a game-changer, offering scalability and flexibility for data-intensive tasks.
This question has plagued many businesses and organizations as they navigate the complexities of bigdata. Enter AWS EMR, or Amazon Elastic […] The post What is AWS EMR? From log analysis to financial modeling, the need for scalable and flexible solutions has never been greater.
Traditionally, building frontend and backend applications has required knowledge of web development frameworks and infrastructure management, which can be daunting for those with expertise primarily in data science and machine learning. Choose the us-east-1 AWS Region from the top right corner. Choose Manage model access.
It takes unstructured data from multiple sources as input and stores it […]. The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP.
AWS), an Amazon.com, Inc. company (NASDAQ: AMZN), today announced the AWS Generative AI Innovation Center, a new program to help customers successfully build and deploy generative artificial intelligence (AI) solutions. Amazon Web Services, Inc.
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as BigData , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. databases), semi-structured data (e.g.,
GTC—Amazon Web Services (AWS), an Amazon.com company (NASDAQ: AMZN), and NVIDIA (NASDAQ: NVDA) today announced that the new NVIDIA Blackwell GPU platform—unveiled by NVIDIA at GTC 2024—is coming to AWS.
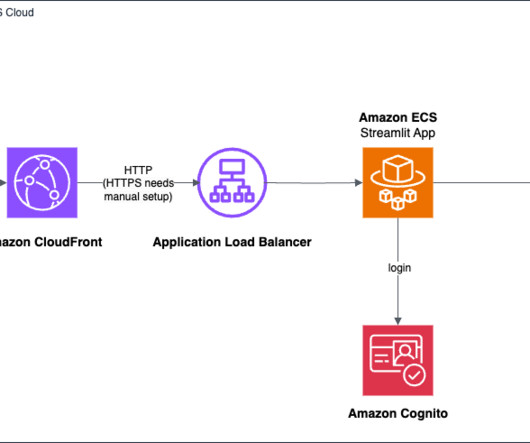
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Summary: BigData refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Amazon Web Services (AWS) announced the general availability of Amazon DataZone, a data management service that enables customers to catalog, discover, govern, share, and analyze data at scale across organizational boundaries.
Amazon Kinesis is a platform to build pipelines for streaming data at the scale of terabytes per hour. The post Amazon Kinesis vs. Apache Kafka For BigData Analysis appeared first on Dataconomy. Parts of the Kinesis platform are.
A growing number of companies are discovering the benefits of investing in bigdata technology. Companies around the world spent over $160 billion on bigdata technology last year and that figure is projected to grow 11% a year for the foreseeable future. Unfortunately, bigdata technology is not without its challenges.
Solution overview The following diagram illustrates the ML platform reference architecture using various AWS services. The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , Amazon SageMaker , AWS DevOps services, and a data lake.
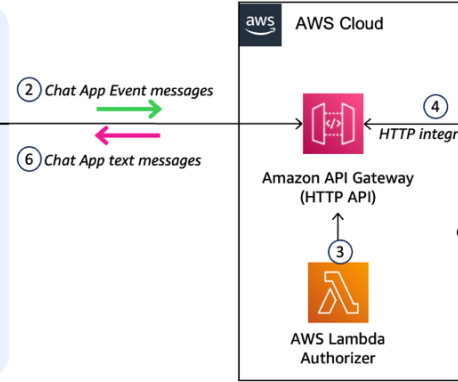
The solution workflow consists of the following steps: The user accesses a smart search portal and lands on a web interface deployed on AWS Amplify. The API is integrated with AWS Lambda , which processes the user query and generates the answers based on available documents and user access using retrieval augmented generation (RAG).
To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS). An AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and related AWS services.
DataOps.live, The Data Products Company™, announced the immediate availability of its new range of AIOps capabilities, a groundbreaking set of features that provides end-to-end lifecycle management of AI workloads from development to production.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. The solution integrates data in three tiers.
Introduction The field of data science is evolving rapidly, and staying ahead of the curve requires leveraging the latest and most powerful tools available. In 2024, data scientists have a plethora of options to choose from, catering to various aspects of their work, including programming, bigdata, AI, visualization, and more.
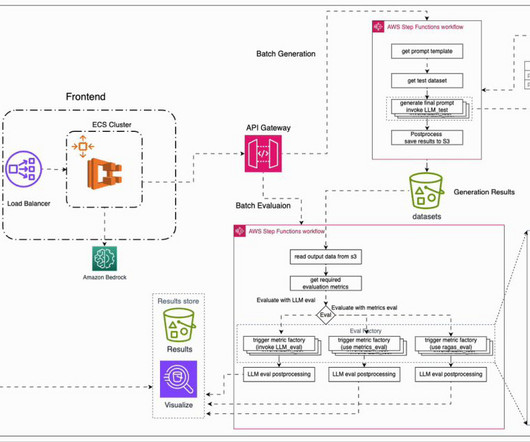
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. The UI service can be run locally in a Docker container or deployed to AWS Fargate.
This article was published as a part of the Data Science Blogathon. In this article, we shall discuss the upcoming innovations in the field of artificial intelligence, bigdata, machine learning and overall, Data Science Trends in 2022. Times change, technology improves and our lives get better.
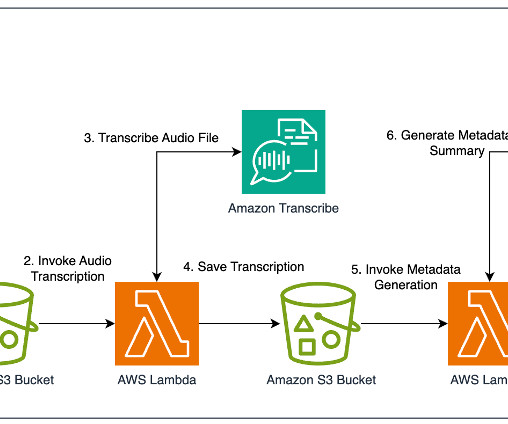
DPG Media chose Amazon Transcribe for its ease of transcription and low maintenance, with the added benefit of incremental improvements by AWS over the years. The flexibility to experiment with multiple models was appreciated, and there are plans to try out Anthropic Claude Opus when it becomes available in their desired AWS Region.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
The AWS Social Responsibility & Impact (SRI) team recognized an opportunity to augment this function using generative AI. Historically, AWS Health Equity Initiative applications were reviewed manually by a review committee. It took 14 or more days each cycle for all applications to be fully reviewed.
By using AWS services, our architecture provides real-time visibility into LLM behavior and enables teams to quickly identify and address any issues or anomalies. In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda.
Leaders Amazon Web Services (AWS) and Microsoft Azure also continue to control majority of the public cloud market. The post Cloud adoption on the rise for marketing and sales companies as AWS and Azure dominate appeared first on Dataconomy. Organizations are also looking to benefit from increased cloud adoption.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
Introduction In the fast changing world of bigdata processing and analytics, the potential management of extensive datasets serves as a foundational pillar for companies for making informed decisions. It helps them to extract useful insights from their data.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). aligned identity provider (IdP).
The need for federated learning in healthcare Healthcare relies heavily on distributed data sources to make accurate predictions and assessments about patient care. Limiting the available data sources to protect privacy negatively affects result accuracy and, ultimately, the quality of patient care.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
Expand to generative AI use cases with your existing AWS and Tecton architecture After you’ve developed ML features using the Tecton and AWS architecture, you can extend your ML work to generative AI use cases. You can also find Tecton at AWS re:Invent. This process is shown in the following diagram.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content