This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. The solution integrates data in three tiers.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
Bigdata in the gaming industry has played a phenomenal role in the field. We have previously talked about the benefits of using bigdata by gaming providers that offer cash games, such as slots. However, more mainstream games use bigdata as well. BigData is the Lynchpin of the Fortnite Gaming Experience.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. It provides a scalable and fault-tolerant ecosystem for bigdata processing.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Create VPC.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. AWS Athena and S3.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdata pipeline.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). Solutions Architect at AWS. Varun Mehta is a Sr.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
How to Choose a Data Warehouse for Your BigData Choosing a data warehouse for bigdata storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. As always, AWS welcomes feedback. About the authors Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. Choose Build and after the build is successful, choose Test.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
Summary: Netflix’s sophisticated BigData infrastructure powers its content recommendation engine, personalization, and data-driven decision-making. As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account.
Bigdata analytics: Bigdata analytics is designed to handle massive volumes of data from various sources, including structured and unstructured data. Bigdata analytics is essential for organizations dealing with large-scale data, such as social media platforms, e-commerce giants, and scientific research.
Azure Synapse Analytics can be seen as a merge of Azure SQL Data Warehouse and Azure DataLake. Synapse allows one to use SQL to query petabytes of data, both relational and non-relational, with amazing speed. Those are the bigdata science announcements of the week. Azure Synapse.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Review the access policy to understand permissions granted.
Third, despite the larger adoption of centralized analytics solutions like datalakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources. Our solution aims to address those challenges using Amazon Bedrock and AWS Analytics Services.
sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Note we have two folders.
In this pattern, we use Retrieval Augmented Generation using vector embeddings stores, like Amazon Titan Embeddings or Cohere Embed , on Amazon Bedrock from a central data catalog, like AWS Glue Data Catalog , of databases within an organization. In entered the BigData space in 2013 and continues to explore that area.
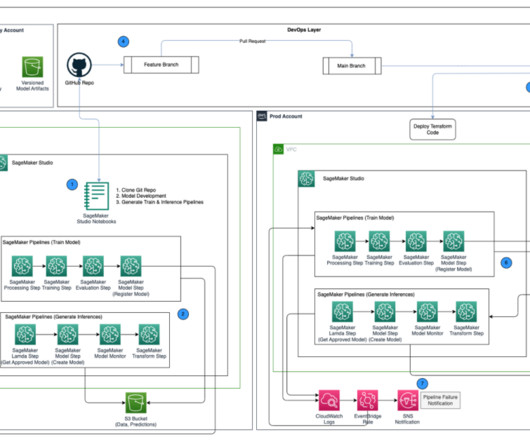
Central model registry – Amazon SageMaker Model Registry is set up in a separate AWS account to track model versions generated across the dev and prod environments. with administrative privileges installed on AWS Terraform version 1.5.5 After the key is provisioned, it should be visible on the AWS KMS console.
Solutions Architect at AWS. He works closely with enterprise customers building datalakes and analytical applications on the AWS platform. Polaris Jhandi is a Cloud Application Architect with AWS Professional Services. He has a background in AI/ML & bigdata.
BigData As datasets become larger and more complex, knowing how to work with them will be key. Bigdata isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed.
Data Mesh which is the latest addition to the stack is saving data teams from the hassle of producing qualitative data for all business types. Most recently, JP Morgan built a ‘Mesh’ on AWS and locked its scalability fortune on a decentralized architecture. Data Management before the ‘Mesh’.
The AWS Glue job calls Amazon Textract , an ML service that automatically extracts text, handwriting, layout elements, and data from scanned documents, to process the input PDF documents. After data is extracted, the job performs document chunking, data cleanup, and postprocessing.
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery.
This account manages templates for setting up new ML Dev Accounts, as well as SageMaker Projects templates for model development and deployment, in AWS Service Catalog. It also hosts a model registry to store ML models developed by data science teams, and provides a single location to approve models for deployment.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. When choosing a datalake, here’s something else to consider.
We demonstrate CDE using simple examples and provide a step-by-step guide for you to experience CDE in an Amazon Kendra index in your own AWS account. Marketing firms store vast amounts of digital data that needs to be centralized, easily searchable, and scalable enabled by data catalogs.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Organizations that can master the challenges of data integration, data quality, and context will be well positioned to identify opportunities and threats quickly, and then to take decisive action to gain competitive advantage. Mainframes have long been valued for those very same attributes.
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. On an ongoing basis, we calculate mean absolute percentage error (MAPE) ratios with product-based data, and optimize model and feature ingestion processes.
With this integration, customers can now harness the full power of Azure’s BigData offerings in a self-service manner to gain immediate value.”. This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and data governance.
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. Cloud Services: Google Cloud Platform, AWS, Azure.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content