This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It takes unstructured data from multiple sources as input and stores it […]. The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP.
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as BigData , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. databases), semi-structured data (e.g.,
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. It provides a scalable and fault-tolerant ecosystem for bigdata processing.
The rise of bigdata technologies and the need for data governance further enhance the growth prospects in this field. Machine Learning Engineer Description Machine Learning Engineers are responsible for designing, building, and deploying machine learning models that enable organizations to make data-driven decisions.
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdata pipeline.
Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. As always, AWS welcomes feedback. About the authors Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. Choose Build and after the build is successful, choose Test.
Summary: Map Reduce Architecture splits bigdata into manageable tasks, enabling parallel processing across distributed nodes. This design ensures scalability, fault tolerance, faster insights, and maximum performance for modern high-volume data challenges. billion in 2023 and will likely expand at a CAGR of 14.9%
Extract : In this step, data is extracted from a vast array of sources present in different formats such as Flat Files, Hadoop Files, XML, JSON, etc. The extracted data is then stored in a staging area where further transformations are carried out. Therefore, the data is thoroughly checked before loading onto a Data Warehouse.
Summary: BigData and Cloud Computing are essential for modern businesses. BigData analyses massive datasets for insights, while Cloud Computing provides scalable storage and computing power. Thats where bigdata and cloud computing come in. This massive collection of data is what we call BigData.
Spark ist direkt auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.Apacke Spark ist jedoch mehr als nur ein Tool, es ist die Grundbasis für die meisten anderen Tools. Delta Lake baut auf Apache Spark auf und ist auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.
Bigdata has led to some huge changes in the way we live. John Deighton is a leading expert on bigdata technology. His research focuses on the importance of data in the online world. Innovations in the early 20th century changed how data could be used. Deighton studies how this evolution came to be.
Bigdata is fundamental to the future of software development. A growing number of developers are finding ways to utilize data analytics to streamline technology rollouts. Data-driven solutions are particularly important for SaaS technology. BigData Technology is Pivotal to SaaS Deployments.
Java is also widely used in bigdata technologies, supported by powerful Java-based tools like Apache Hadoop and Spark, which are essential for data processing in AI. Skills in cloud platforms like AWS, Azure, and Google Cloud are crucial for deploying scalable and accessible AI solutions.
Augmenting the training data using techniques like cropping, rotating, and flipping images helped improve the model training data and model accuracy. Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure.
sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Note we have two folders.
The Biggest Data Science Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
From this stage, GoldenGate runs a merge statement to replicate data into Snowflake. Once an extract and distribution path is configured, follow these steps to ingest data into Snowflake. Once an extract and distribution path is configured, follow these steps to ingest data into Snowflake. share/hadoop/common/*:hadoop-3.2.1/share/hadoop/common/lib/*:hadoop-3.2.1/share/hadoop/hdfs/*:hadoop-3.2.1/share/hadoop/hdfs/lib/*:hadoop-3.2.1/etc/hadoop/:hadoop-3.2.1/share
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? The post Data Science Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
Programming languages like Python and R are commonly used for data manipulation, visualization, and statistical modeling. Machine learning algorithms play a central role in building predictive models and enabling systems to learn from data. Bigdata platforms such as Apache Hadoop and Spark help handle massive datasets efficiently.
BigData Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
For instance, partition pruning, data skipping, and columnar storage formats (like Parquet and ORC) allow efficient data retrieval, reducing scan times and query costs. This is invaluable in bigdata environments, where unnecessary scans can significantly drain resources.
Data Mesh which is the latest addition to the stack is saving data teams from the hassle of producing qualitative data for all business types. Most recently, JP Morgan built a ‘Mesh’ on AWS and locked its scalability fortune on a decentralized architecture.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Organizations that can master the challenges of data integration, data quality, and context will be well positioned to identify opportunities and threats quickly, and then to take decisive action to gain competitive advantage. Mainframes have long been valued for those very same attributes.
Check out this course to build your skillset in Seaborn — [link] BigData Technologies Familiarity with bigdata technologies like Apache Hadoop, Apache Spark, or distributed computing frameworks is becoming increasingly important as the volume and complexity of data continue to grow.
From Sale Marketing Business 7 Powerful Python ML For Data Science And Machine Learning need to be use. The data-driven world will be in full swing. With the growth of bigdata and artificial intelligence, it is important that you have the right tools to help you achieve your goals. To perform data analysis 6.
Data professionals are in high demand all over the globe due to the rise in bigdata. The roles of data scientists and data analysts cannot be over-emphasized as they are needed to support decision-making. This article will serve as an ultimate guide to choosing between Data Science and Data Analytics.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Key Skills Experience with cloud platforms (AWS, Azure). They ensure that data is accessible for analysis by data scientists and analysts. Experience with bigdata technologies (e.g., Data Management and Processing Develop skills in data cleaning, organisation, and preparation.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. million by 2028.
Unify Data Sources Collect data from multiple systems into one cohesive dataset. To confirm seamless integration, you can use tools like Apache Hadoop, Microsoft Power BI, or Snowflake to process structured data and Elasticsearch or AWS for unstructured data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























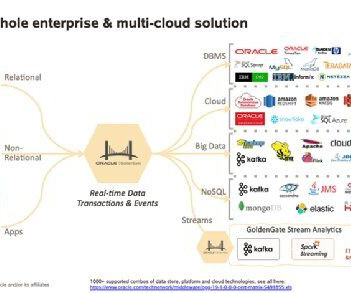





















Let's personalize your content