This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
AWS), an Amazon.com, Inc. company (NASDAQ: AMZN), today announced the AWS Generative AI Innovation Center, a new program to help customers successfully build and deploy generative artificial intelligence (AI) solutions. Amazon Web Services, Inc.
After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. The solution integrates data in three tiers.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
The solution workflow consists of the following steps: The user accesses a smart search portal and lands on a web interface deployed on AWS Amplify. The API is integrated with AWS Lambda , which processes the user query and generates the answers based on available documents and user access using retrieval augmented generation (RAG).
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Growth Outlook: Companies like Google DeepMind, NASA’s Jet Propulsion Lab, and IBM Research actively seek research data scientists for their teams, with salaries typically ranging from $120,000 to $180,000. With the continuous growth in AI, demand for remote data science jobs is set to rise.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
Driven by significant advancements in computing technology, everything from mobile phones to smart appliances to mass transit systems generate and digest data, creating a bigdata landscape that forward-thinking enterprises can leverage to drive innovation. However, the bigdata landscape is just that.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
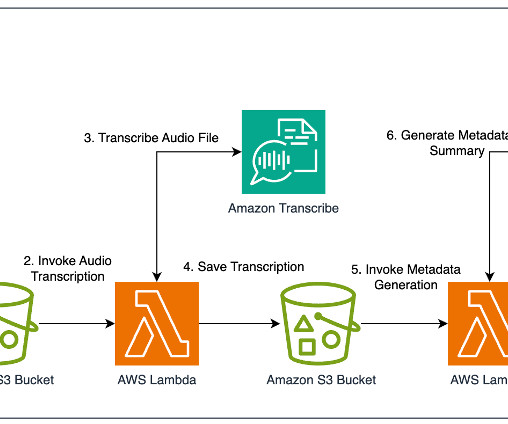
DPG Media chose Amazon Transcribe for its ease of transcription and low maintenance, with the added benefit of incremental improvements by AWS over the years. The flexibility to experiment with multiple models was appreciated, and there are plans to try out Anthropic Claude Opus when it becomes available in their desired AWS Region.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
Many organizations are implementing machine learning (ML) to enhance their business decision-making through automation and the use of large distributed datasets. With increased access to data, ML has the potential to provide unparalleled business insights and opportunities.
By using AWS services, our architecture provides real-time visibility into LLM behavior and enables teams to quickly identify and address any issues or anomalies. In this post, we demonstrate a few metrics for online LLM monitoring and their respective architecture for scale using AWS services such as Amazon CloudWatch and AWS Lambda.
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler.
In this post, we explain how we built an end-to-end product category prediction pipeline to help commercial teams by using Amazon SageMaker and AWS Batch , reducing model training duration by 90%. An important aspect of our strategy has been the use of SageMaker and AWS Batch to refine pre-trained BERT models for seven different languages.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
With the ability to analyze a vast amount of data in real-time, identify patterns, and detect anomalies, AI/ML-powered tools are enhancing the operational efficiency of businesses in the IT sector. Why does AI/ML deserve to be the future of the modern world? Let’s understand the crucial role of AI/ML in the tech industry.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. SageMaker Unied Studio is an integrated development environment (IDE) for data, analytics, and AI.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia. 2048 256 10.4
This post is part of an ongoing series on governing the machine learning (ML) lifecycle at scale. To start from the beginning, refer to Governing the ML lifecycle at scale, Part 1: A framework for architecting ML workloads using Amazon SageMaker.
This is a customer post jointly authored by ICL and AWS employees. To overcome this business challenge, ICL decided to develop in-house capabilities to use machine learning (ML) for computer vision (CV) to automatically monitor their mining machines.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. The example extracts and contextualizes the buildspec-1-10-2.yml
With this launch, you can now deploy NVIDIAs optimized reranking and embedding models to build, experiment, and responsibly scale your generative AI ideas on AWS. As part of NVIDIA AI Enterprise available in AWS Marketplace , NIM is a set of user-friendly microservices designed to streamline and accelerate the deployment of generative AI.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
You may check out additional reference notebooks on aws-samples for how to use Meta’s Llama models hosted on Amazon Bedrock. You can implement these steps either from the AWS Management Console or using the latest version of the AWS Command Line Interface (AWS CLI). Solutions Architect at AWS. Varun Mehta is a Sr.
Machine learning (ML) can help companies make better business decisions through advanced analytics. Companies across industries apply ML to use cases such as predicting customer churn, demand forecasting, credit scoring, predicting late shipments, and improving manufacturing quality. He is very passionate about data-driven AI.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. MongoDB vector data store MongoDB Atlas Vector Search is a new feature that allows you to store and search vector data in MongoDB.
Machine learning (ML) administrators play a critical role in maintaining the security and integrity of ML workloads. To address this challenge, AWS introduced Amazon SageMaker Role Manager in December 2022. Their primary focus is to ensure that users operate with the utmost security, adhering to the principle of least privilege.
ML for BigData with PySpark on AWS, Asynchronous Programming in Python, and the Top Industries for AI Harnessing Machine Learning on BigData with PySpark on AWS In this brief tutorial, you’ll learn some basics on how to use Spark on AWS for machine learning, MLlib, and more.
Summary: “Data Science in a Cloud World” highlights how cloud computing transforms Data Science by providing scalable, cost-effective solutions for bigdata, Machine Learning, and real-time analytics. This accessibility democratises Data Science, making it available to businesses of all sizes.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts.
As Artificial Intelligence (AI) and Machine Learning (ML) technologies have become mainstream, many enterprises have been successful in building critical business applications powered by ML models at scale in production.
The recently published IDC MarketScape: Asia/Pacific (Excluding Japan) AI Life-Cycle Software Tools and Platforms 2022 Vendor Assessment positions AWS in the Leaders category. The tools are typically used by data scientists and ML developers from experimentation to production deployment of AI and ML solutions.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Enterprises can use no-code ML solutions to streamline their operations and optimize their decision-making without extensive administrative overhead.
With Amazon SageMaker , you can manage the whole end-to-end machine learning (ML) lifecycle. It offers many native capabilities to help manage ML workflows aspects, such as experiment tracking, and model governance via the model registry. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content