This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. The post Using AWS Athena and QuickSight for Data Analysis appeared first on Analytics Vidhya. Introduction Ever wondered how to query and analyze raw data? Also, have you ever tried doing this with Athena and QuickSight?
AWS AI chips, Trainium and Inferentia, enable you to build and deploy generative AI models at higher performance and lower cost. The Datadog dashboard offers a detailed view of your AWS AI chip (Trainium or Inferentia) performance, such as the number of instances, availability, and AWS Region.
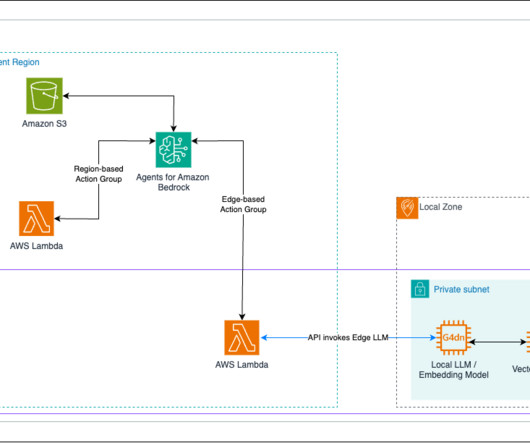
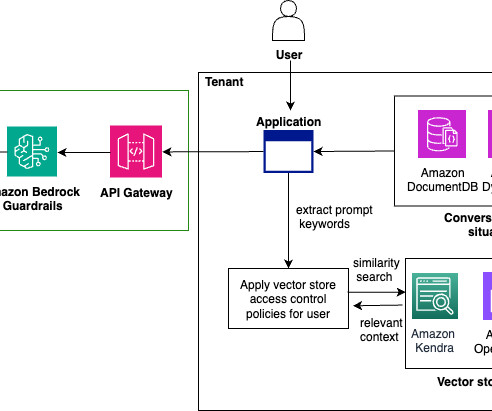
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
Introduction Discover the ultimate guide to building a powerful data pipeline on AWS! With AWS, you can unleash the full potential of your data. In today’s data-driven world, organizations need efficient pipelines to collect, process, and leverage valuable data.
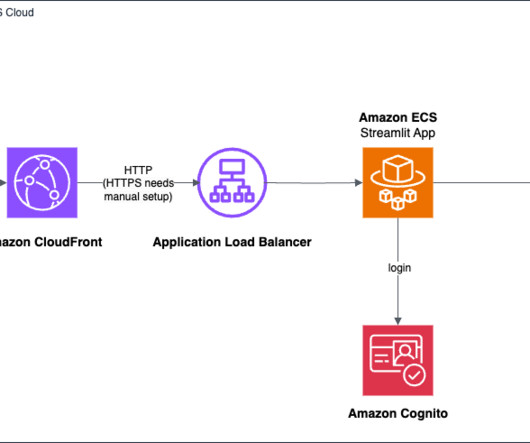
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The user signs in by entering a user name and a password.
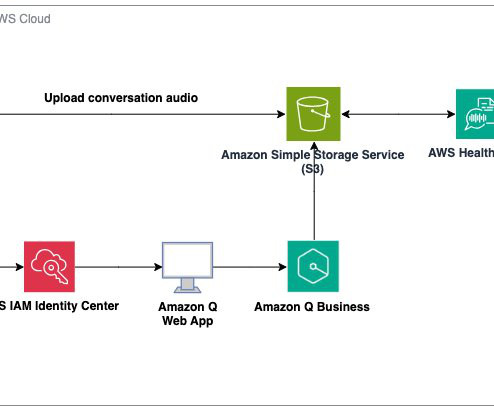
During re:Invent 2023, we launched AWS HealthScribe , a HIPAA eligible service that empowers healthcare software vendors to build their clinical applications to use speech recognition and generative AI to automatically create preliminary clinician documentation. AWS HealthScribe will then output two files which are also stored on Amazon S3.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
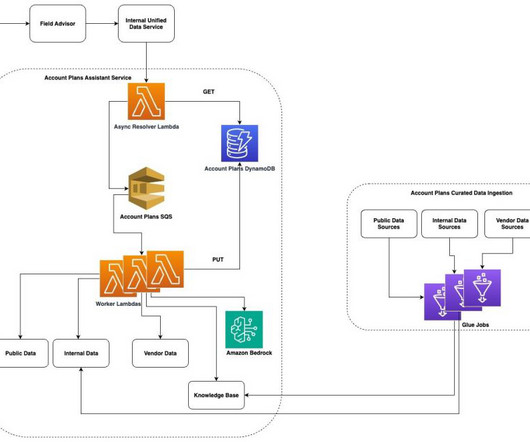
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
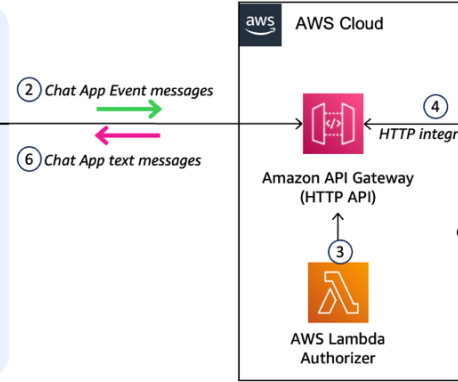
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. On AWS, you can use the fully managed Amazon Bedrock Agents or tools of your choice such as LangChain agents or LlamaIndex agents.
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python. For collection_name , use the OpenSearch Serverless collection name.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. AWS CodeArtifact , which provides a private PyPI repository so that SageMaker can use it to download necessary packages.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
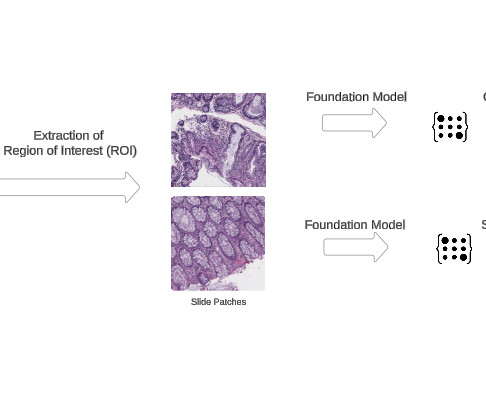
Solution overview Our solution uses the AWS integrated ecosystem to create an efficient scalable pipeline for digital pathology AI workflows. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
Last week, I saw an astonishing 197 new service launches from AWS. This means we are getting closer to AWS re:Invent 2024! Our News Blog team is also …
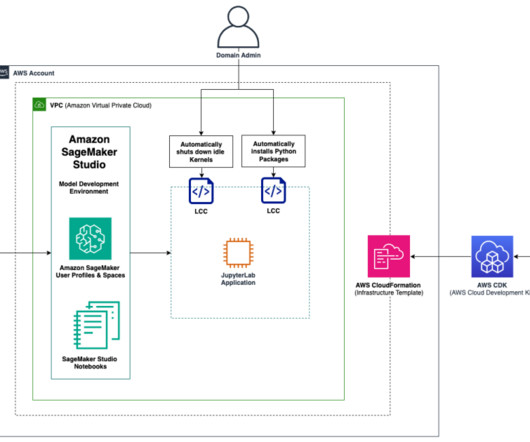
Solution overview The solution constitutes a best-practice Amazon SageMaker domain setup with a configurable list of domain user profiles and a shared SageMaker Studio space using the AWS Cloud Development Kit (AWS CDK). The AWS CDK is a framework for defining cloud infrastructure as code. The AWS CDK installed.
This post discusses how to use AWS Step Functions to efficiently coordinate multi-step generative AI workflows, such as parallelizing API calls to Amazon Bedrock to quickly gather answers to lists of submitted questions. sync) pattern, which automatically waits for the completion of asynchronous jobs.
We're excited to announce the general availability of Databricks Fleet clusters on AWS. What are Fleet clusters? Databricks Fleet clusters unlock the potential.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
In this blog post, we will learn how to build a travel planner application using React Native. With the announcement of the Amplify AI kit, we learned how to build custom UI components, conversation history and add external data to the conversation flow.
This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI. Some of these tools included AWS Cloud based solutions, such as AWS Lambda and AWS Step Functions.
We spoke with Dr. Swami Sivasubramanian, Vice President of Data and AI, shortly after AWS re:Invent 2024 to hear his impressionsand to get insights on how the latest AWS innovations help meet the real-world needs of customers as they build and scale transformative generative AI applications. Canva uses AWS to power 1.2
This blog post will make you less likely to run into issues in this 15+ step process. JupyterHub is a multi-user, container-friendly version of the Jupyter Notebook. However, it can be difficult to setup.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). In this post, we demonstrate how the CQ solution used Amazon Transcribe and other AWS services to improve critical KPIs with AI-powered contact center call auditing and analytics.
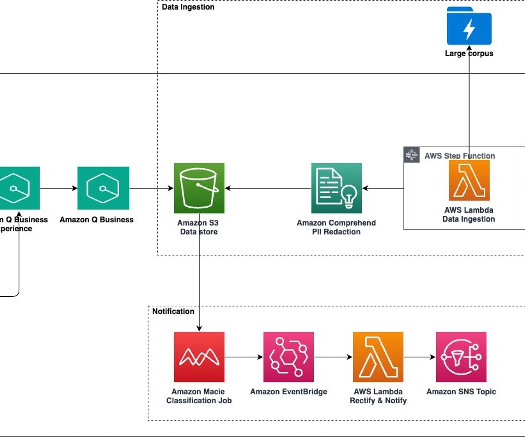
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
We are excited to announce that PrivateLink and using customer-managed keys (CMK) for encryption are now Generally Available (GA) for Databricks on AWS.
About the Authors Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area working with GENAI Model providers and helping customer optimize their GENAI workloads on AWS.
Having spent the last years studying the art of AWS DeepRacer in the physical world, the author went to AWS re:Invent 2024. In AWS DeepRacer: How to master physical racing? , I wrote in detail about some aspects relevant to racing AWS DeepRacer in the physical world. How did it go?
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
At ByteDance, we collaborated with Amazon Web Services (AWS) to deploy multimodal large language models (LLMs) for video understanding using AWS Inferentia2 across multiple AWS Regions around the world. Solution overview Weve collaborated with AWS since the first generation of Inferentia chips.
Building upon a previous Machine Learning Blog post to create personalized avatars by fine-tuning and hosting the Stable Diffusion 2.1 We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads.
read()) print(json.dumps(response_body, indent=2)) response = requests.get("[link] blog = response.text chat_with_document(blog, "What is the blog writing about?") For the subsequent request, we can ask a different question: chat_with_document(blog, "what are the use cases?") Specifically, it:nn1.
To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS). An AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and related AWS services.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content