This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Discover the ultimate guide to building a powerful datapipeline on AWS! In today’s data-driven world, organizations need efficient pipelines to collect, process, and leverage valuable data. With AWS, you can unleash the full potential of your data.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
AWS AI chips, Trainium and Inferentia, enable you to build and deploy generative AI models at higher performance and lower cost. The Datadog dashboard offers a detailed view of your AWS AI chip (Trainium or Inferentia) performance, such as the number of instances, availability, and AWS Region.
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. It can help collect more data on the value of LLMs for your content translation use cases. For collection_name , use the OpenSearch Serverless collection name.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. Technical architecture The overall solution is implemented using AWS services and LangChain. AWS Glue AWS Glue is used for data cataloging.
Scaling and load balancing The gateway can handle load balancing across different servers, model instances, or AWS Regions so that applications remain responsive. The AWS Solutions Library offers solution guidance to set up a multi-provider generative AI gateway.
To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager , enabling auditing and monitoring of generative AI applications. Figure 1 depicts the systems functionalities and AWS services. Select AWS Generative AI Best Practices Framework for assessment. Choose Create assessment.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
To make this possible, Chronos converts continuous time series data into a discrete vocabulary through a two-step process of scaling the time series by its absolute mean and then quantizing the scaled time series into a fixed number of equally spaced bins. Click here to open the AWS console and follow along.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. A provisioned or serverless Amazon Redshift data warehouse. Choose Create stack. Sohaib Katariwala is a Sr.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can also find Tecton at AWS re:Invent.
Amazon Bedrock Agents is instrumental in customization and tailoring apps to help meet specific project requirements while protecting private data and securing their applications. These agents work with AWS managed infrastructure capabilities and Amazon Bedrock , reducing infrastructure management overhead.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
For more information about distributed training with SageMaker, refer to the AWS re:Invent 2020 video Fast training and near-linear scaling with DataParallel in Amazon SageMaker and The science behind Amazon SageMaker’s distributed-training engines.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing. AWS SageMaker also has a CLI for model creation and management.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). Control plane and data plane implementation SnapLogic’s Agent Creator platform follows a decoupled architecture, separating the control plane and data plane for enhanced security and scalability.
Consider the following picture, which is an AWS view of the a16z emerging application stack for large language models (LLMs). This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service.
Advancements in data processing, storage, and analysis technologies power this transformation. In Data Science in a Cloud World, we explore how cloud computing has revolutionised Data Science. Each platform offers unique capabilities tailored to varying needs, making the platform a critical decision for any Data Science project.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine. Conclusion.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Furthermore, the democratization of AI and ML through AWS and AWS Partner solutions is accelerating its adoption across all industries. For example, a health-tech company may be looking to improve patient care by predicting the probability that an elderly patient may become hospitalized by analyzing both clinical and non-clinical data.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. Subscribe an AWS Lambda function to the SQS queue.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. We use DAG (Directed Acyclic Graph) in Airflow, DAGs describe how to run a workflow by defining the pipeline in Python, that is configuration as code.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. In the following sections, we dive into each pipeline in more detail.
In this post we highlight how the AWS Generative AI Innovation Center collaborated with the AWS Professional Services and PGA TOUR to develop a prototype virtual assistant using Amazon Bedrock that could enable fans to extract information about any event, player, hole or shot level details in a seamless interactive manner.
To unlock the potential of generative AI technologies, however, there’s a key prerequisite: your data needs to be appropriately prepared. In this post, we describe how use generative AI to update and scale your datapipeline using Amazon SageMaker Canvas for data prep.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient datapipelines.
If prompted, set up a user profile for SageMaker Studio by providing a user name and specifying AWS Identity and Access Management (IAM) permissions. AWS SDKs and authentication Verify that your AWS credentials (usually from the SageMaker role) have Amazon Bedrock access. Open a SageMaker Studio notebook: Choose JupyterLab.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machine learning pipelines with AWS Step Functions and deploy them using Infrastructure as Code. This article is for data and ML Ops engineers who would want to deploy and update ML pipelines using CloudFormation templates.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















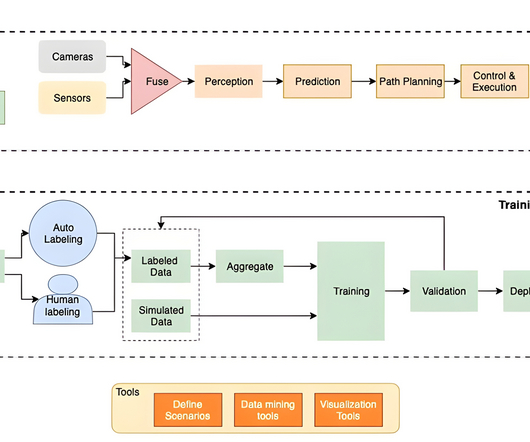






























Let's personalize your content