This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python. For collection_name , use the OpenSearch Serverless collection name.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. To promote the success of this migration, we collaborated with the AWS team to create automated and intelligent digital experiences that demonstrated Rockets understanding of its clients and kept them connected.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. In this post, we use IAM Identity Center as the SAML 2.0-aligned
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. AWS also helps data science and DevOps teams to collaborate and streamlines the overall model lifecycle process. Wipro is an AWS Premier Tier Services Partner and Managed Service Provider (MSP).
This brings reliability to data ETL (Extract, Transform, Load) processes, query performances, and other critical data operations. AWS CloudFormation is a service offered by Amazon Web Services (AWS) that allows you to define cloud infrastructure in JSON or YAML templates. appeared first on Data Science Blog.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing. AWS SageMaker also has a CLI for model creation and management.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
Discover your data and put it to work using familiar AWS tools to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI app building, and more, in a single governed environment. Youre redirected to the AWS CloudFormation console to deploy a stack to configure VPC resources.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes.
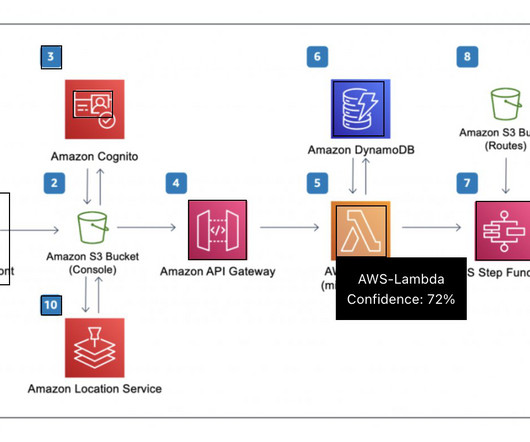
The customer review analysis workflow consists of the following steps: A user uploads a file to dedicated data repository within your Amazon Simple Storage Service (Amazon S3) data lake, invoking the processing using AWS Step Functions. In the first step, an AWS Lambda function reads and validates the file, and extracts the raw data.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
The solution presented in this post is orchestrated using an AWS Step Functions state machine that is triggered when you upload a recording to the designated Amazon Simple Storage Service (Amazon S3) bucket. Step Functions lets you create serverless workflows to orchestrate and connect components across AWS services.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. One popular route is leveraging third-party ETL tools like Fivetran to ensure a smooth and successful migration.
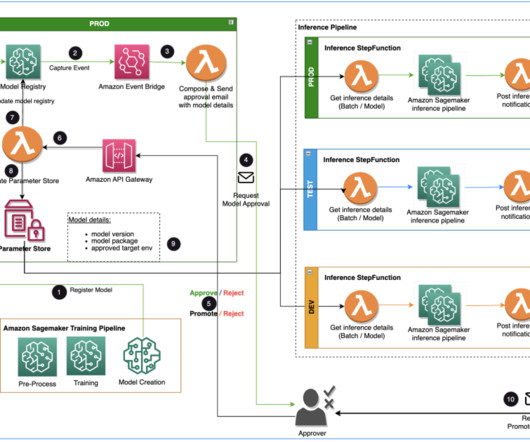
In this post, we discuss how the AWS AI/ML team collaborated with the Merck Human Health IT MLOps team to build a solution that uses an automated workflow for ML model approval and promotion with human intervention in the middle. A model developer typically starts to work in an individual ML development environment within Amazon SageMaker.
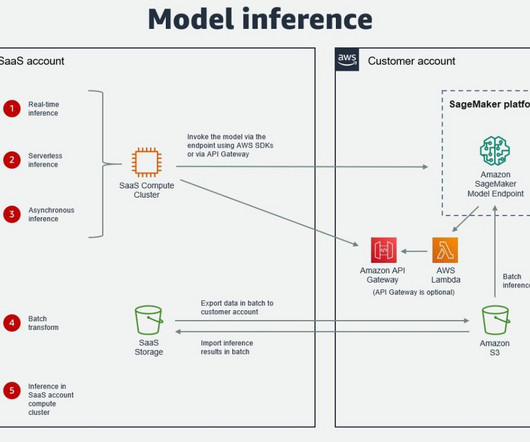
A number of AWS independent software vendor (ISV) partners have already built integrations for users of their software as a service (SaaS) platforms to utilize SageMaker and its various features, including training, deployment, and the model registry. In some cases, an ISV may deploy their software in the customer AWS account.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. Create database connections The built-in SQL browsing and execution capabilities of SageMaker Studio are enhanced by AWS Glue connections. or later image versions.
The AWS Glue job calls Amazon Textract , an ML service that automatically extracts text, handwriting, layout elements, and data from scanned documents, to process the input PDF documents. Manager, Solutions Architecture at AWS for Energy and Utilities. Outside of work, he is a travel enthusiast. Guillermo Menéndez Corral is a Sr.
TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting. TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations.
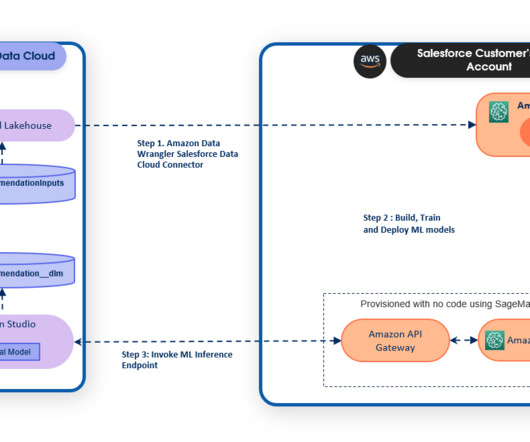
It eliminates tedious, costly, and error-prone ETL (extract, transform, and load) jobs. AWS and Salesforce are excited to partner together to deliver this experience to our joint customers to help them drive business processes using the power of ML and artificial intelligence. Ife has over 10 years of experience in technology.
The following diagram illustrates the architecture of a news recommender application powered by Amazon Personalize and supporting AWS services. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. Happy building!
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Cloud platforms, such as Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), provide scalable and flexible infrastructure options. What makes the difference is a smart ETL design capturing the nature of process mining data. The post How to reduce costs for Process Mining appeared first on Data Science Blog.
AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. AWS Sagemeaker is in fact a great tool for machine learning operations (MLOps) to automate and standardize processes across the ML lifecycle. S3 buckets.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake. The workflow well reference throughout this blog was built using customer data from TrellisMart, a fictional retail company.
In this blog, we will cover the best practices for developing jobs in Matillion, an ETL/ELT tool built specifically for cloud database platforms. The blog will be divided into three broad sections: Design, SDLC, and Security, each with its best practices. What Are Matillion Jobs and Why Do They Matter?
In this blog, we will cover what Fivetran and dbt are, but first, to understand why tools like Fivetran and dbt have brought such value to the data ecosystem, we need to go back to the reason for their existence – the emergence of the ELT pattern. ETL systems just couldn’t handle the massive flows of raw data.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. In Part 1, we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. In this series of posts, we share lessons learned about optimizing costs in Amazon SageMaker.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. What do Data Science Bootcamps Offer?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content