This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. At the time, I knew little about AI or machine learning (ML). seconds, securing the 2018 AWS DeepRacer grand champion title!
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
AWS AI chips, Trainium and Inferentia, enable you to build and deploy generative AI models at higher performance and lower cost. Datadog, an observability and security platform, provides real-time monitoring for cloud infrastructure and ML operations. To get started, see AWS Inferentia and AWS Trainium Monitoring.
Recognizing this need, we have developed a Chrome extension that harnesses the power of AWS AI and generative AI services, including Amazon Bedrock , an AWS managed service to build and scale generative AI applications with foundation models (FMs). The user signs in by entering a user name and a password.
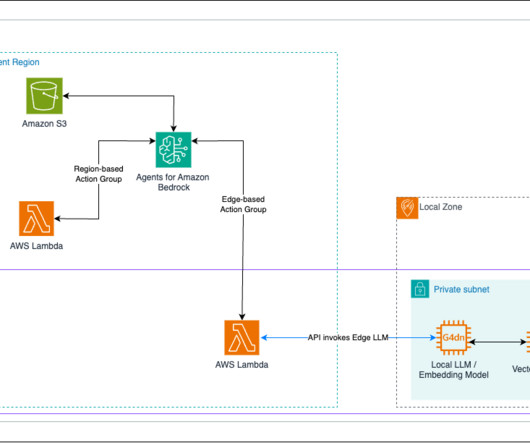
In this post, we show how to extend Amazon Bedrock Agents to hybrid and edge services such as AWS Outposts and AWS Local Zones to build distributed Retrieval Augmented Generation (RAG) applications with on-premises data for improved model outcomes.
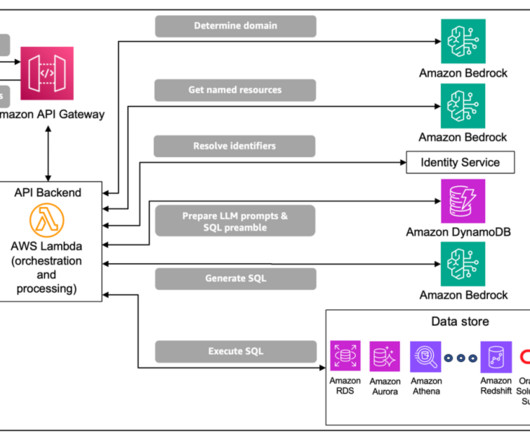
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. You can use AWS services such as Application Load Balancer to implement this approach. API Gateway also provides a WebSocket API. These components are illustrated in the following diagram.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
InterVision Systems, LLC (InterVision), an AWS Premier Tier Services Partner and Amazon Connect Service Delivery Partner, has been at the forefront of this transformation, with their contact center solution designed specifically for city and county services called ConnectIV CX for Community Engagement.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
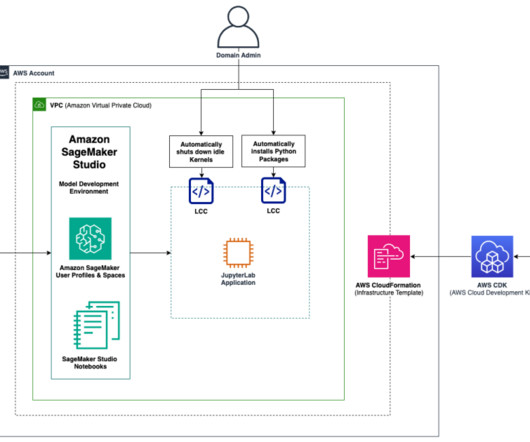
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machine learning (ML) development. These automations can greatly decrease overhead related to ML project setup, facilitate technical consistency, and save costs related to running idle instances.
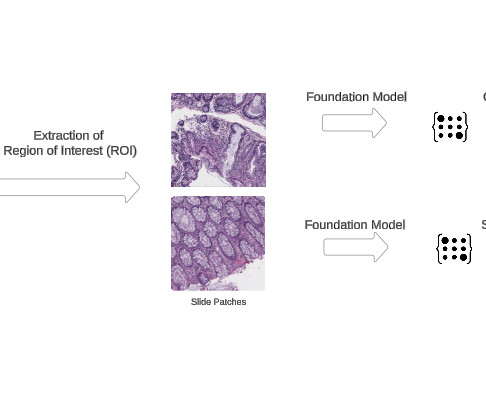
Solution overview Our solution uses the AWS integrated ecosystem to create an efficient scalable pipeline for digital pathology AI workflows. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
Enhancing AWS Support Engineering efficiency The AWS Support Engineering team faced the daunting task of manually sifting through numerous tools, internal sources, and AWS public documentation to find solutions for customer inquiries. Then we introduce the solution deployment using three AWS CloudFormation templates.
With the QnABot on AWS (QnABot), integrated with Microsoft Azure Entra ID access controls, Principal launched an intelligent self-service solution rooted in generative AI. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. By using a combination of AWS services, you can implement this feature effectively, overcoming the current limitations within SageMaker.
The company developed an automated solution called Call Quality (CQ) using AI services from Amazon Web Services (AWS). In this post, we demonstrate how the CQ solution used Amazon Transcribe and other AWS services to improve critical KPIs with AI-powered contact center call auditing and analytics.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. Admins and users can also overwrite the defaults using the SDK defaults configuration file.
These experiences are made possible by our machine learning (ML) backend engine, with ML models built for video understanding, search, recommendation, advertising, and novel visual effects. By using sophisticated ML algorithms, the platform efficiently scans billions of videos each day.
Refer to Supported Regions and models for batch inference for current supporting AWS Regions and models. To address this consideration and enhance your use of batch inference, we’ve developed a scalable solution using AWS Lambda and Amazon DynamoDB. Amazon S3 invokes the {stack_name}-create-batch-queue-{AWS-Region} Lambda function.
Building upon a previous Machine Learning Blog post to create personalized avatars by fine-tuning and hosting the Stable Diffusion 2.1 We show how to then prepare the fine-tuned model to run on AWS Inferentia2 powered Amazon EC2 Inf2 instances , unlocking superior price performance for your inference workloads.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. SageMaker Processing provisions cluster resources for you to run city-, country-, or continent-scale geospatial ML workloads.
This post explores how OMRON Europe is using Amazon Web Services (AWS) to build its advanced ODAP and its progress toward harnessing the power of generative AI. Some of these tools included AWS Cloud based solutions, such as AWS Lambda and AWS Step Functions.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping provide data security.
This new cutting-edge image generation model, which was trained on Amazon SageMaker HyperPod , empowers AWS customers to generate high-quality images from text descriptions with unprecedented ease, flexibility, and creative potential. Large model is available today in the following AWS Regions: US East (N. By adding Stable Diffusion 3.5
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
The seeds of a machine learning (ML) paradigm shift have existed for decades, but with the ready availability of scalable compute capacity, a massive proliferation of data, and the rapid advancement of ML technologies, customers across industries are transforming their businesses.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
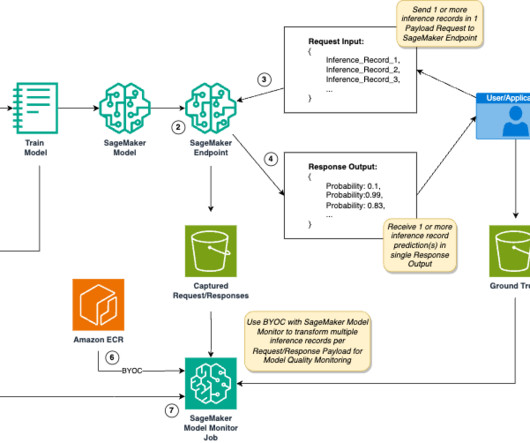
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
This blog post is co-written with Renuka Kumar and Thomas Matthew from Cisco. This post describes a pattern that AWS and Cisco teams have developed and deployed that is viable at scale and addresses a broad set of challenging enterprise use cases. Shweta Keshavanarayana is a Senior Customer Solutions Manager at AWS.
read()) print(json.dumps(response_body, indent=2)) response = requests.get("[link] blog = response.text chat_with_document(blog, "What is the blog writing about?") For the subsequent request, we can ask a different question: chat_with_document(blog, "what are the use cases?") Specifically, it:nn1.
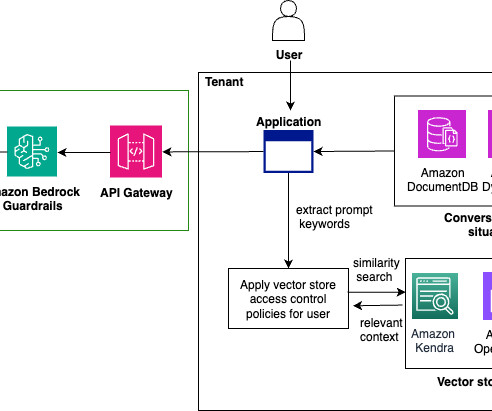
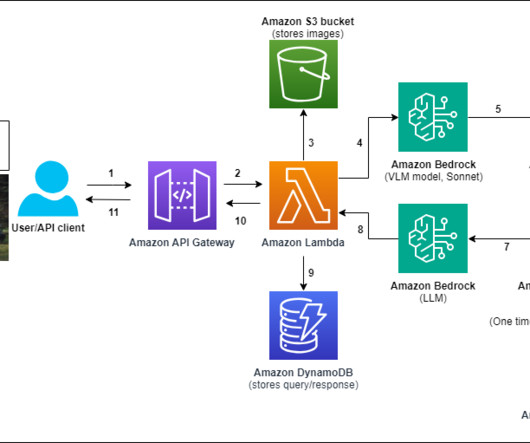
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents. For this post, we recommend activating these models in the us-east-1 or us-west-2 AWS Region.
At Data Reply and AWS, we are committed to helping organizations embrace the transformative opportunities generative AI presents, while fostering the safe, responsible, and trustworthy development of AI systems. Post-authentication, users access the UI Layer, a gateway to the Red Teaming Playground built on AWS Amplify and React.
Today, we are introducing three key advancements that further expand our AI inference capabilities: NVIDIA NIM microservices are now available in AWS Marketplace for SageMaker Inference deployments , providing customers with easy access to state-of-the-art generative AI models. or Mixtral.
Getting started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. About the authors Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale.
The AWS DeepRacer League is the world’s first autonomous racing league, open to everyone and powered by machine learning (ML). AWS DeepRacer brings builders together from around the world, creating a community where you learn ML hands-on through friendly autonomous racing competitions.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. Organizations typically can’t predict their call patterns, so the solution relies on AWS serverless services to scale during busy times.
To find the URL, open the AWS Management Console for SageMaker and choose Ground Truth and then Labeling workforces in the navigation pane. If you encounter a permissions error when running npm install -g aws-cdk , you can adjust the global npm directory to avoid using sudo by following the instructions in this documentation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content