This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS). An AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and related AWS services.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. The following diagram shows an example.
From the earliest days, Amazon has used ML for various use cases such as book recommendations, search, and fraud detection. Last year, AWS launched its AWS Trainium accelerators, which optimize performance per cost for developing and building next generation DL models.
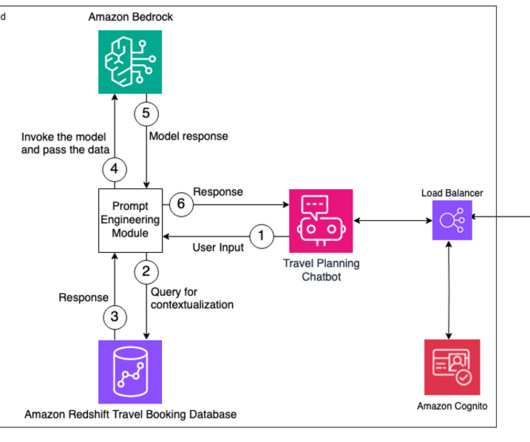
We build a personalized generative AI travel itinerary planner as part of this example and demonstrate how we can personalize a travel itinerary for a user based on their booking and user profile data stored in Amazon Redshift. An SSL certificate created and imported into AWS Certificate Manager (ACM).
Shared data allows occupants to make service requests and book rooms, right-size portfolios and increase the efficiency of lease administration, capital projects and more. In this blog post, we walk through the recommended options for running IBM TAS on Amazon Web Services (AWS).
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Integrating tensor parallelism to enable training on massive clusters This release of SMP also expands PyTorch FSDP’s capabilities to include tensor parallelism techniques.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity. Nitin Eusebius is a Sr.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others.
Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure. For SageMaker distributed training, the instances need to be in the same AWS Region and Availability Zone. days in AWS vs. 9 days on their legacy platform).
PII Detected tagged documents are fed into Logikcull’s search index cluster for their users to quickly identify documents that contain PII entities. The request is handled by Logikcull’s application servers hosted on Amazon EC2 and the servers communicates with the search index cluster to find the documents.
In this post, we walk through how to set up and configure an OpenSearch Service cluster as the knowledge base for your Amazon Lex QnAIntent. Prerequisites Before creating an OpenSearch Service cluster, you need to create an Amazon Lex V2 bot. In an enterprise environment, you typically launch your OpenSearch Service cluster in a VPC.
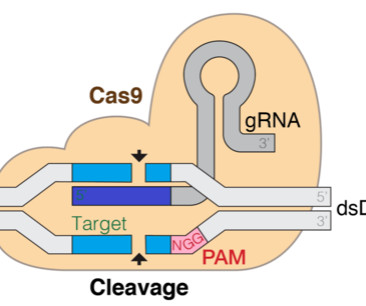
The clustered regularly interspaced short palindromic repeat (CRISPR) technology holds the promise to revolutionize gene editing technologies, which is transformative to the way we understand and treat diseases. We also provided code that can help you jumpstart your biology applications in AWS.
A touchscreen interface that's super laggy, or an appointment booking app that forces you to go in and out of possible dates and fill in all information before it tells you if it's available. The word cluster is an anachronism to an end-user in the cloud! We are, like what, 10 years into the cloud adoption?
The integration with Amazon Bedrock is achieved through the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interaction with Amazon Bedrock and the deployment of the classification model. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
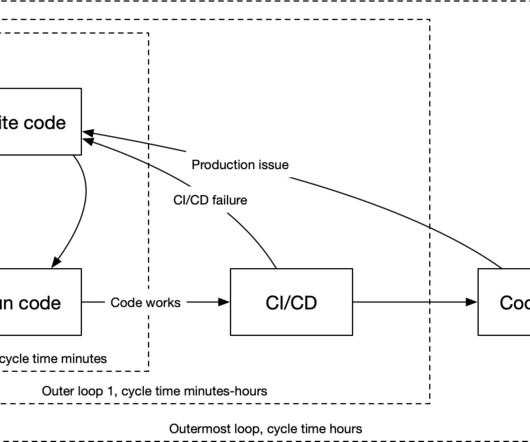
Adapted from the book Effective Data Science Infrastructure. Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch. Foundational Infrastructure Layers.
Because the models are hosted and deployed on AWS, your data, whether used for evaluating the model or using it at scale, is never shared with third parties. In the AWS Management Console for SageMaker Studio, go to SageMaker JumpStart under Prebuilt and automated solutions. Assistant: Certainly!
nn[”yes”, ”no”] yes question answering Answer based on context:nn The newest and most innovative Kindle yet lets you take notes on millions of books and documents, write lists and journals, and more. He works with Machine Learning Startups to build and deploy AI/ML applications on AWS.
Deployment Server Tools: Kubernetes, Docker Swarm, AWS CodeDeploy Purpose: Automates the deployment of applications to staging or production environments. Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. Download the code!
Case Study Book in Progress! After completed these case studies and participating in the recent rapid advancement of Data Science technologies, especially learning how to do Data Science on many cloud platforms (Azure, AWS, GCP, a little IBM). Happy Practicing! ? ? D onate | ? GitHub | ?
Tesla, for instance, relies on a cluster of NVIDIA A100 GPUs to train their vision-based autonomous driving algorithms. But, if you're looking to deploy your computer vision projects in the cloud, some of the cloud services tailored for computer vision projects are Google Cloud Vision AI and AWS Rekognition. How Do You Measure Success?
For example, you can use BigQuery , AWS , or Azure. It can be a cluster run by Kubernetes or maybe something else. How awful are they?” In terms of the interaction, ideally, the data scientists shouldn’t have to be setting up infrastructure like a Spark cluster. They’re terrible people.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
Click here to open the AWS console and follow along. The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. To use one of these models, AWS offers the fully managed service Amazon Bedrock.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
This capability allows for the seamless addition of SageMaker HyperPod managed compute to EKS clusters, using automated node and job resiliency features for foundation model (FM) development. FMs are typically trained on large-scale compute clusters with hundreds or thousands of accelerators.
Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. Solutions Architect at AWS. He works closely with enterprise customers building data lakes and analytical applications on the AWS platform. Peter Chung is a Solutions Architect serving enterprise customers at AWS.
AWS, in its dedication to help customers achieve the highest saving, has continuously innovated not only in pricing options and cost-optimization proactive services , but also in launching cost savings features like multi-model endpoints (MMEs). Outside of work, he enjoys reading books, fiddling with the guitar, and making pizza.
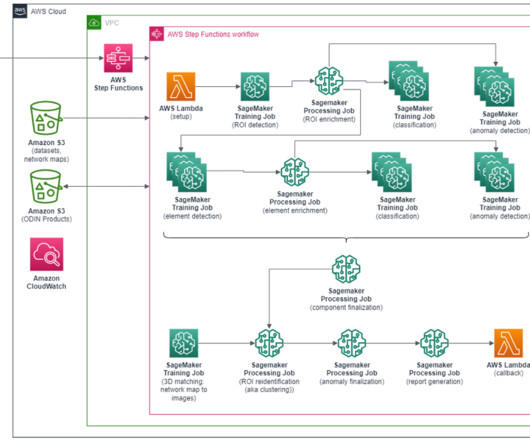
This allows the clustering of ROIs referring to the same pole. During his spare time he likes playing golf with friends and travelling abroad with only fly and drive bookings. He has worked on projects in different domains, including MLOps, Computer Vision, NLP, and involving a broad set of AWS services.
They can engage users in natural dialogue, provide customer support, answer FAQs, and assist with booking or shopping decisions. Whether you are opting to fine-tune on a local machine or the cloud, predominant factors related to cost will be fine-tuning time, GPU clusters, and storage.
Powered by generative AI services on AWS and large language models (LLMs) multi-modal capabilities, HCLTechs AutoWise Companion provides a seamless and impactful experience. Technical architecture The overall solution is implemented using AWS services and LangChain. AWS Glue AWS Glue is used for data cataloging.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS. To further enrich the dataset, Fastweb generated synthetic Italian data using LLMs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content