This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
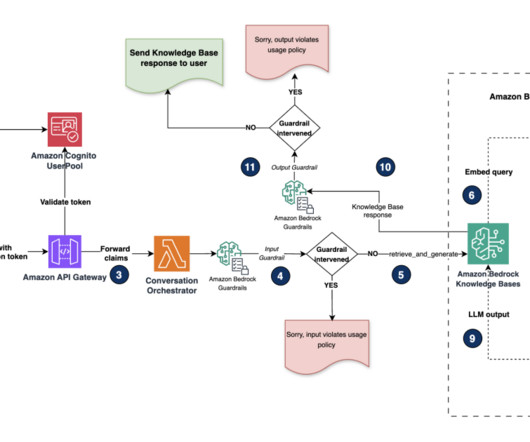
To assist in this effort, AWS provides a range of generative AI security strategies that you can use to create appropriate threat models. For all data stored in Amazon Bedrock, the AWS shared responsibility model applies. The following diagram illustrates how RBAC works with metadata filtering in the vector database.
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Let’s understand how these AWS services are integrated in detail.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on. AWS CloudFormation provides and configures those resources on your behalf, removing the risk of human error when deploying bots to new environments. Resources: # 1.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Navigate to the AWS Secrets Manager console and find the secret -api-keys.
Today, Mixbook is the #1 rated photo book service in the US with 26 thousand five-star reviews. Years ago, Mixbook undertook a strategic initiative to transition their operational workloads to Amazon Web Services (AWS) , a move that has continually yielded significant advantages.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. The framework for connecting Anthropic Claude 2 and CBRE’s sample database was implemented using LangChain.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! You marked your calendars, you booked your hotel, and you even purchased the airfare. are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. And last but not least (and always fun!)
Today at the AWS New York Summit, we announced a wide range of capabilities for customers to tailor generative AI to their needs and realize the benefits of generative AI faster. Each application can be immediately scaled to thousands of users and is secure and fully managed by AWS, eliminating the need for any operational expertise.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. Pre-built templates tailored to various use cases are included, significantly enhancing both employee and customer experiences.
Looking back to 2021, when Anthropic first started building on AWS, no one could have envisioned how transformative the Claude family of models would be. In addition, proprietary data is never exposed to the public internet, never leaves the AWS network, is securely transferred through VPC, and is encrypted in transit and at rest.
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. model in Amazon Bedrock.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
Generative AI with AWS The emergence of FMs is creating both opportunities and challenges for organizations looking to use these technologies. You can use AWS PrivateLink with Amazon Bedrock to establish private connectivity between your FMs and your VPC without exposing your traffic to the internet.
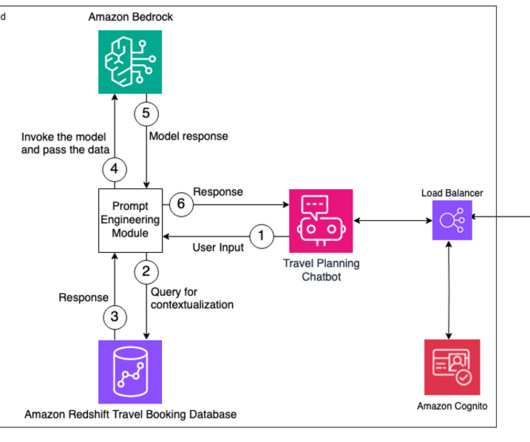
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. This solution contains two major components. This solution contains two major components.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. The solution’s scalability quickly accommodates growing data volumes and user queries thanks to AWS serverless offerings.
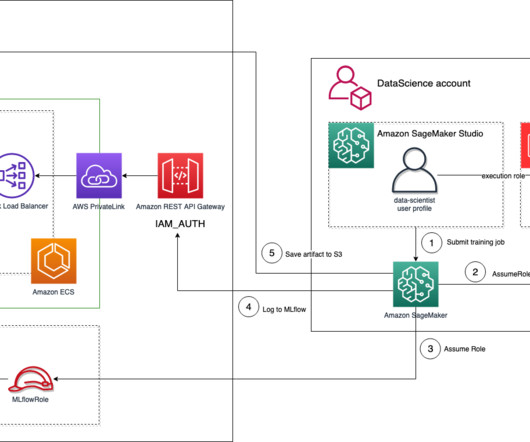
In a previous post , we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure. To automate the infrastructure deployment, we use the AWS Cloud Development Kit (AWS CDK).
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. Scott Fitzgerald.
Many of you asked for an electronic version of our new book, so after working out the kinks, we are finally excited to release the electronic version of “Building LLMs for Production.” We’ve heard many feedback from you guys wanting to have both the e-book and book for different occasions. We listened.
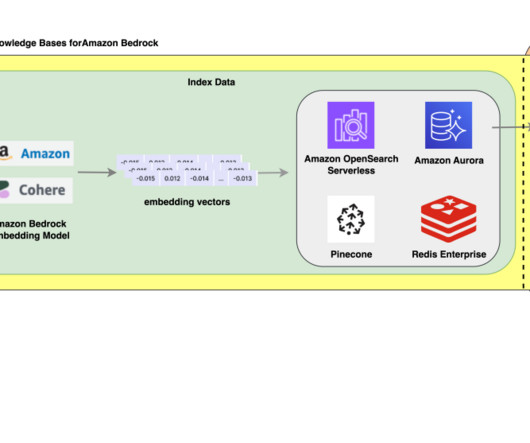
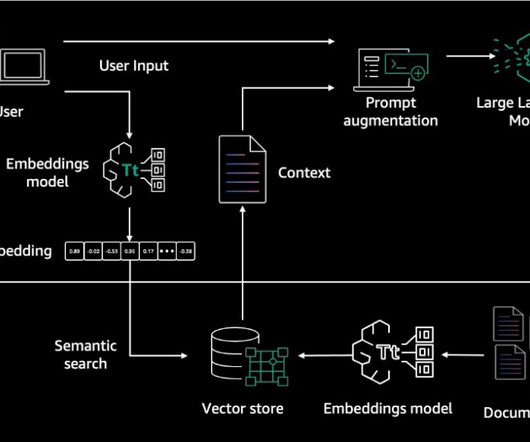
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. The document embeddings are split into chunks and stored as indexes in a vector database. We use the Amazon letters to shareholders dataset to develop this solution.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
In addition to semantic search, you can use embeddings to augment your prompts for more accurate results through Retrieval Augmented Generation (RAG)—but in order to use them, you’ll need to store them in a database with vector capabilities. You can use it via either the Amazon Bedrock REST API or the AWS SDK. Nitin Eusebius is a Sr.
The platform enables you to create managed agents for complex business tasks without the need for coding, such as booking travel, processing insurance claims, creating ad campaigns, and managing inventory. This solution is available in the AWS Solutions Library. AWS Lambda – AWS Lambda provides serverless compute for processing.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
At AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. Context is retrieved from the vector database based on the user query. For example, consider the following query: What is the cost of the book " " on ? pdf" } }, "score": 0.6389407 }, { "content": { "text": ".amortization
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. In our recent webcast , IBM, AWS, customers and partners came together for an interactive session.
In this post, we demonstrate how you can build chatbots with QnAIntent that connects to a knowledge base in Amazon Bedrock (powered by Amazon OpenSearch Serverless as a vector database ) and build rich, self-service, conversational experiences for your customers. Keep the data source location as the same AWS account and choose Browse S3.
Knowledge Bases for Amazon Bedrock allows you to build performant and customized Retrieval Augmented Generation (RAG) applications on top of AWS and third-party vector stores using both AWS and third-party models. RAG is a popular technique that combines the use of private data with large language models (LLMs). txt) Markdown (.md)
needed to address some of these challenges in one of their many AI use cases built on AWS. During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. Based on the initial tests, this method showed great results.
Agents for Amazon Bedrock In July, AWS announced the preview of agents for Amazon Bedrock , a new capability for developers to create fully managed agents in a few clicks. We provide an AWS CloudFormation template to provision the resources needed for building this solution. Our code is backed by an in-memory SQLite database.
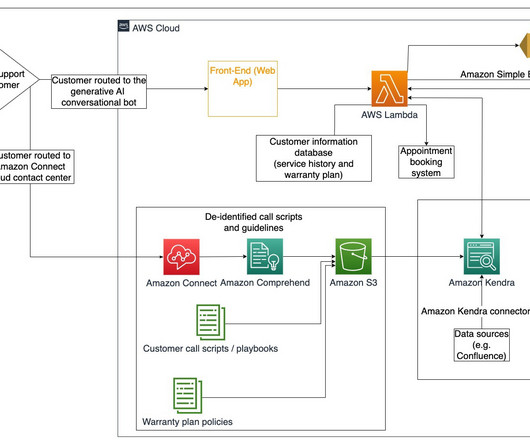
This post takes you through the most common challenges that customers face when searching internal documents, and gives you concrete guidance on how AWS services can be used to create a generative AI conversational bot that makes internal information more useful. The web application front-end is hosted on AWS Amplify.
This represents a major opportunity for businesses to optimize this workflow, save time and money, and improve accuracy by modernizing antiquated manual document handling with intelligent document processing (IDP) on AWS. The transformed data is then tailored to match the formats required by their downstream databases.
Customers are applying generative AI to new use cases; for example, Lonely Planet, a premier travel media company, worked with our Generative AI Innovation Center to introduce a scalable AI platform that organizes book content in minutes to deliver cohesive, highly accurate travel recommendations, reducing itinerary generation costs by nearly 80%.
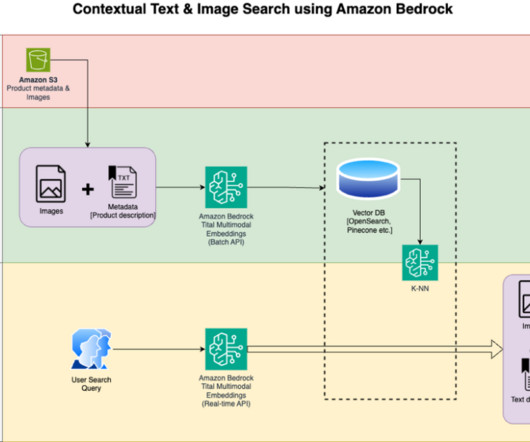
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. Virginia) and US West (Oregon) AWS Regions.
We used FSx for Lustre and Amazon Relational Database Service (Amazon RDS) for fast parallel data access. Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure. days in AWS vs. 9 days on their legacy platform).
It includes sensor devices to capture vibration and temperature data, a gateway device to securely transfer data to the AWS Cloud, the Amazon Monitron service that analyzes the data for anomalies with ML, and a companion mobile app to track potential failures in your machinery. The following diagram illustrates the solution architecture.
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. The AWS P5 EC2 instance type range is based on the NVIDIA H100 chip, which uses the Hopper architecture. In November 2023, AWS announced the next generation Trainium2 chip.
A touchscreen interface that's super laggy, or an appointment booking app that forces you to go in and out of possible dates and fill in all information before it tells you if it's available. If I make a change in the AWS console, or if I add a new pod to Kubernetes, or whatever, I want that to happen in seconds.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. An AWS account with permissions to create AWS Identity and Access Management (IAM) policies and roles.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content