This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Das Format Business Talk am Kudamm in Berlin führte ein Interview mit Benjamin Aunkofer zum Thema “BusinessIntelligence und Process Mining nachhaltig umsetzen”. Für Data Science ja sowieso. 3 – Bei der Nutzung von Daten fallen oft die Begriffe „Process Mining“ und „BusinessIntelligence“.
Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Amazon Redshift allows data engineers to analyze large datasets quickly using massively parallel processing (MPP) architecture. Looker: Looker is a businessintelligence and data visualization platform.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels. Solution requirements Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
Such infrastructure should not only address these issues but also scale according to the demands of AI workloads, thereby enhancing business outcomes. Native integrations with IBM’s data fabric architecture on AWS establish a trusted data foundation, facilitating the acceleration and scaling of AI across the hybrid cloud.
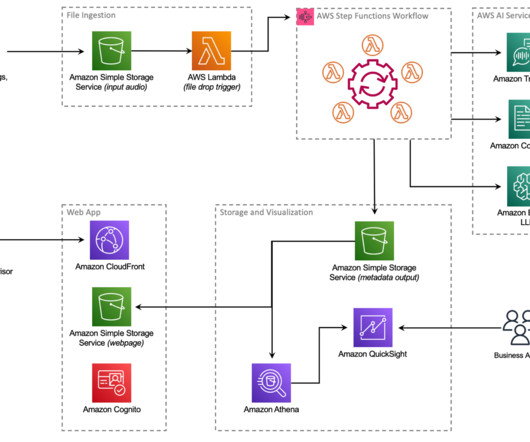
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
To create and share customer feedback analysis without the need to manage underlying infrastructure, Amazon QuickSight provides a straightforward way to build visualizations, perform one-time analysis, and quickly gain business insights from customer feedback, anytime and on any device. The Step Functions workflow starts.
Data models help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for businessintelligence. Ensure that data is clean, consistent, and up-to-date.
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment , AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges. It’s an easy way to run analytics on IoT data to gain accurate insights.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements.
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
Inconsistent or unstructured data can lead to faulty insights, so transformation helps standardise data, ensuring it aligns with the requirements of Analytics, Machine Learning , or BusinessIntelligence tools. This makes drawing actionable insights, spotting patterns, and making data-driven decisions easier.
Cut costs by consolidating data warehouse investments. Think of Tableau as your data visualization and businessintelligence layer on top of Genie—allowing you to see, understand, and act on your live customer data. Built-in connectors bring in data from every single channel. Bring your own AI with AWS.
Cut costs by consolidating data warehouse investments. Think of Tableau as your data visualization and businessintelligence layer on top of Genie—allowing you to see, understand, and act on your live customer data. Built-in connectors bring in data from every single channel. Bring your own AI with AWS.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access. AMC Networks is excited by the opportunity to capitalize on the value of all of their data to improve viewer experiences.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a cloud data warehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance.
In today’s world, data warehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as businessintelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
Powered by the industry’s broadest and deepest connectivity, the Alation Data Catalog supports dataintelligence use cases across an organization’s de facto hybrid cloud environments. Alation Cloud Service is available on AWS. Three core capabilities of a data catalog. Not all data catalogs are created equal.
These processes are essential in AI-based big data analytics and decision-making. DataLakesDatalakes are crucial in effectively handling unstructured data for AI applications. They serve as centralized repositories where raw data, whether structured or unstructured, can be stored in its native format.
Think of Tableau as your data visualization and businessintelligence layer on top of Data Cloud—allowing you to see, understand, and act on your live customer data. These features cover functionality for enterprise customer data in five key categories: Connect, Harmonize, Unify, Analyze and Predict, and Act.
A data pipeline is created with the focus of transferring data from a variety of sources into a data warehouse. Further processes or workflows can then easily utilize this data to create businessintelligence and analytics solutions. This involves looking at the data structure, relationships, and content.
So as you take inventory of your existing skill set, you’ll want to start to identify the areas where you need to focus on to become a data engineer. These areas may include SQL, database design, data warehousing, distributed systems, cloud platforms (AWS, Azure, GCP), and data pipelines. Learn more about the cloud.
It has taken a global pandemic for organizations to finally realize that the old way of doing businesses – and the legacy technologies and processes that came with it – are no longer going to cut it. The post The Move to Public Cloud and an IntelligentData Strategy appeared first on DATAVERSITY. As […].
Having been in business for over 50 years, ARC had accumulated a massive amount of data that was stored in siloed, on-premises servers across its 7 business domains. Using Alation, ARC automated the data curation and cataloging process. “So
The use of separate data warehouses and lakes has created data silos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
Other users Some other users you may encounter include: Data engineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party businessintelligence tools and the data platform, is not separate.
Airlines Reporting Corporation (ARC) used self-service data access as a way to accelerate time-to-market for new products. It also sells businessintelligence and other data products to travel industry customers, and with over 50 years’ worth of data, they have a lot of insights to offer.
For a multi-account environment, you can track costs at an AWS account level to associate expenses. A combination of an AWS account and tags provides the best results. Implement a tagging strategy A tag is a label you assign to an AWS resource. The AWS reserved prefix aws: tags provide additional metadata tracked by AWS.
It uses Amazon Bedrock , AWS Health , AWS Step Functions , and other AWS services. Some examples of AWS-sourced operational events include: AWS Health events — Notifications related to AWS service availability, operational issues, or scheduled maintenance that might affect your AWS resources.
Although generative AI is fueling transformative innovations, enterprises may still experience sharply divided data silos when it comes to enterprise knowledge, in particular between unstructured content (such as PDFs, Word documents, and HTML pages), and structured data (real-time data and reports stored in databases or datalakes).
Amazon EMR (Elastic MapReduce) Amazon EMR is a cloud-native Big Data platform that simplifies running Big Data frameworks such as Apache Hadoop and Apache Spark on AWS. Statistics : According to AWS reports, EMR reduces the time required for Big Data processing tasks by up to 90% compared to traditional methods.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content