This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
Introduction The cloud trend has gained tremendous importance in the technology industry and the field of science in recent years. The most important aspect of cloudcomputing is the on-demand application delivery paradigm from the cloud customer’s perspective. As a result, cloud services […].
Introduction There are several reasons organizations should use cloudcomputing in the modern world. Businesses of all sizes are switching to the cloud to manage risks, improve data security, streamline processes and decrease costs, or other reasons. Many services are available from top cloud […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction AWS S3 is one of the object storage services offered by Amazon Web Services or AWS. The post Using AWS S3 with Python boto3 appeared first on Analytics Vidhya.
Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems. Traditionally, ETL processes are […].
Introduction to AWSAWS, or Amazon Web Services, is one of the world’s most widely used cloud service providers. It is a cloud platform that provides a wide variety of services that can be used together to create highly scalable applications. These […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction Amazon Web Services (AWS) is a cloudcomputing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machine learning, etc.
The post AWS Elastic BeanStalk Processing and its Components appeared first on Analytics Vidhya. Introduction If you are a beginner or have little time, configuring the environment for your application may be too complicated and time-consuming. You need to consider monitoring, logs, security groups, VMs, backups, etc.
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
The post Introduction to Amazon API Gateway using AWS Lambda appeared first on Analytics Vidhya. If you want to make noodles, you just take the ingredients out of the cupboard, fire up the stove, and make it yourself. This […].
It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it […]. The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Click here to open the AWS console and follow along. The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary.
In the contemporary age of Big Data, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. The post Why using Infrastructure as Code for developing Cloud-based Data Warehouse Systems?
During the last 18 months, we’ve launched more than twice as many machine learning (ML) and generative AI features into general availability than the other major cloud providers combined. Each application can be immediately scaled to thousands of users and is secure and fully managed by AWS, eliminating the need for any operational expertise.
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Data science and dataengineering are incredibly resource intensive. By using cloudcomputing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
The creation of this data model requires the data connection to the source system (e.g. SAP ERP), the extraction of the data and, above all, the data modeling for the event log. DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Click to enlarge!
Amazon SageMaker offers several ways to run distributed data processing jobs with Apache Spark, a popular distributed computing framework for big data processing. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
Cloud-Based infrastructure with process mining? Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloudcomputing resources. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses.
Computer science, math, statistics, programming, and software development are all skills required in NLP projects. CloudComputing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Google Cloud is starting to make a name for itself as well.
The Biggest Data Science Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The Data Science Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
Hey, are you the data science geek who spends hours coding, learning a new language, or just exploring new avenues of data science? The post Data Science Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
This article was published as a part of the Data Science Blogathon. In this article, we shall discuss the upcoming innovations in the field of artificial intelligence, big data, machine learning and overall, Data Science Trends in 2022. Deep learning, natural language processing, and computer vision are examples […].
This article was published as a part of the Data Science Blogathon. Introduction Data sharing has become so easy today, and we can share the details with just a few clicks. The post How to Encrypt and Decrypt the Data in PySpark? These details can get leaked if the […].
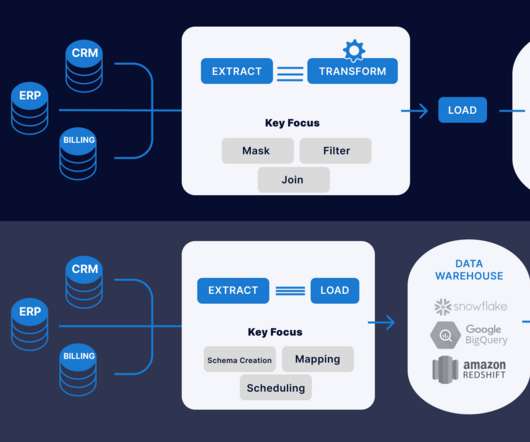
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
This article was published as a part of the Data Science Blogathon. Introduction Are you a Data Science enthusiast or already a Data Scientist who is trying to make his or her portfolio strong by adding a good amount of hands-on projects to your resume? But have no clue where to get the datasets from so […].
In this post, we will be particularly interested in the impact that cloudcomputing left on the modern data warehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization.
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Key Skills Experience with cloud platforms (AWS, Azure). Robotics Engineer Robotics Engineers develop robotic systems that can perform tasks autonomously or semi-autonomously. Proficiency in Data Analysis tools for market research. They ensure that data is accessible for analysis by data scientists and analysts.
Strategies for Overcoming Challenges Now that we understand the hurdles, let’s explore strategies to overcome them and successfully scale Data Science projects. Familiarize yourself with their services for data storage, processing, and model deployment.
There is no one size fits all approach to data strategy cost. An online business involves the use of cloudcomputing and storage platforms. That’s where most of your budget goes when implementing your data strategy. Cloud Storage Platforms There are multiple cloud storage platforms available for your business.
There is no one size fits all approach to data strategy cost. An online business involves the use of cloudcomputing and storage platforms. That’s where most of your budget goes when implementing your data strategy. Cloud Storage Platforms There are multiple cloud storage platforms available for your business.
The inherent cost of cloudcomputing : To illustrate the point, Argentina’s minimum wage is currently around 200 dollars per month. 2 To teach them how to use the stack considered best for them (mostly focusing on fundamentals of MLOps and AWS Sagemaker / Sagemaker Studio). The bad Let’s start with the not-so-cool first.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Snowflake is a cloudcomputing–based datacloud company that provides data warehousing services that are far more scalable and flexible than traditional data warehousing products. Table of Contents Why Discuss Snowflake & Power BI?
We also discuss common security concerns that can undermine trust in AI, as identified by the Open Worldwide Application Security Project (OWASP) Top 10 for LLM Applications , and show ways you can use AWS to increase your security posture and confidence while innovating with generative AI.
Entirely new paradigms rise quickly: cloudcomputing, dataengineering, machine learning engineering, mobile development, and large language models. To further complicate things, topics like cloudcomputing, software operations, and even AI don’t fit nicely within a university IT department.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content