This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
What businesses need from cloudcomputing is the power to work on their data without having to transport it around between different clouds, different databases and different repositories, different integrations to third-party applications, different datapipelines and different compute engines.
Summary: “Data Science in a Cloud World” highlights how cloudcomputing transforms Data Science by providing scalable, cost-effective solutions for big data, Machine Learning, and real-time analytics. Advancements in data processing, storage, and analysis technologies power this transformation.
Spark is well suited to applications that involve large volumes of data, real-time computing, model optimization, and deployment. Read about Apache Zeppelin: Magnum Opus of MLOps in detail AWS SageMaker AWS SageMaker is an AI service that allows developers to build, train and manage AI models.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
In an era where cloud technology is not just an option but a necessity for competitive business operations, the collaboration between Precisely and Amazon Web Services (AWS) has set a new benchmark for mainframe and IBM i modernization.
But keep in mind one thing which is you have to either replicate the topics in your cloud cluster or you will have to develop a custom connector to read and copy back and forth from the cloud to the application. It will enable you to quickly transform and load the data results into Amazon S3 data lakes or JDBC data stores.
Computer science, math, statistics, programming, and software development are all skills required in NLP projects. CloudComputing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Google Cloud is starting to make a name for itself as well.
Yet mainframes weren’t designed to integrate easily with modern distributed computing platforms. Cloudcomputing, object-oriented programming, open source software, and microservices came about long after mainframes had established themselves as a mature and highly dependable platform for business applications.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Yet mainframes weren’t initially designed to integrate easily with modern distributed computing platforms. Cloudcomputing, object-oriented programming, open source software, and microservices came about long after mainframes had established themselves as a mature and highly dependable platform for business applications.
In this post, we will be particularly interested in the impact that cloudcomputing left on the modern data warehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Serverless, or serverless computing, is an approach to software development that empowers developers to build and run application code without having to worry about maintenance tasks like installing software updates, security, monitoring and more. Despite its name, a serverless framework doesn’t mean computing without servers.
The inherent cost of cloudcomputing : To illustrate the point, Argentina’s minimum wage is currently around 200 dollars per month. 2 To teach them how to use the stack considered best for them (mostly focusing on fundamentals of MLOps and AWS Sagemaker / Sagemaker Studio).
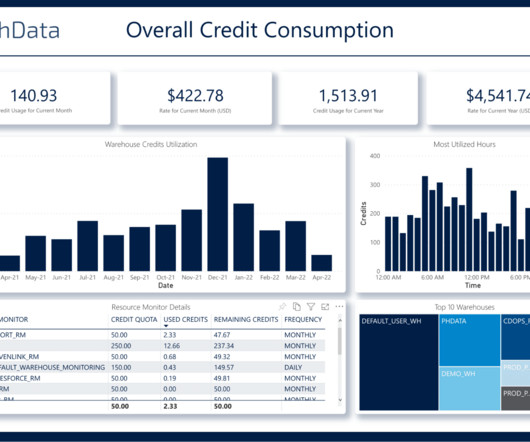
Snowflake is a cloudcomputing–based datacloud company that provides data warehousing services that are far more scalable and flexible than traditional data warehousing products. Table of Contents Why Discuss Snowflake & Power BI?
Understanding the Cost of Snowflake Like any other cloudcomputing tool, costs can quickly add up if not kept in check. The total cost of using Snowflake is the aggregate of the cost of using data transfer, storage, and computing resources. Luckily, there are several tools in place to monitor these costs in Snowflake.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content