This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations are collecting data at an alarming pace to analyze and derive insights for business enhancements. The abundant requirement for data collection made clouddata storage an unavoidable option concerning the […]. The post AWS Storage: Cost Optimization Principles appeared first on Analytics Vidhya.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? appeared first on Data Science Blog.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
Spark ist direkt auf mehreren Cloud-Plattformen verfügbar, darunter AWS, Azure und Google Cloud Platform.Apacke Spark ist jedoch mehr als nur ein Tool, es ist die Grundbasis für die meisten anderen Tools. Databricks: Databricks ist eine Cloud-basierte Datenverarbeitungs- und Analyseplattform, die auf Apache Spark aufbaut.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
The creation of this data model requires the data connection to the source system (e.g. SAP ERP), the extraction of the data and, above all, the data modeling for the event log. DATANOMIQ Data Mesh Cloud Architecture – This image is animated! Click to enlarge!
Length of Interview: 30 – 45 minutes Interview 2: Leadership In this interview, you will meet with the Director of the Solutions Engineering team. The discussion points in this interview will include a review of your current experience as it relates to clouddataengineering and solution engineering.
This is where the AWS suite of low-code and no-code ML services becomes an essential tool. As a strategic systems integrator with deep ML experience, Deloitte utilizes the no-code and low-code ML tools from AWS to efficiently build and deploy ML models for Deloitte’s clients and for internal assets.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Data integrations and pipelines can also impact latency.
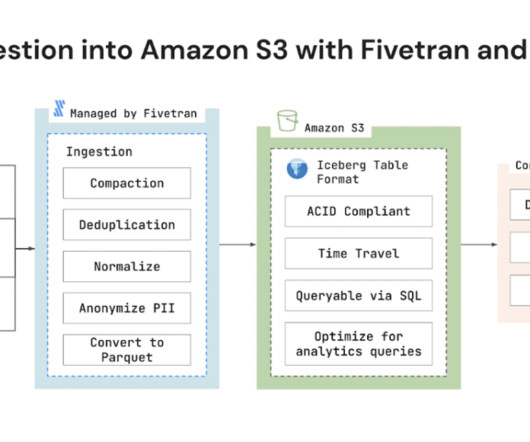
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
There are several styles of data integration. Dataengineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
Reduzierte Personalkosten , sind oft dann gegeben, wenn interne DataEngineers verfügbar sind, die die Datenmodelle intern entwickeln. Höhere Data Readiness , denn für eine zentrale Datenplattform lohn es sich eher, Daten aus weniger genutzten Quellen anzuschließen. Müssen Rohdatentabellen in die Analyse-Tools wie z.
Matillion Matillion is a complete ETL tool that integrates with an extensive list of pre-built data source connectors, loads data into clouddata environments such as Snowflake, and then performs transformations to make data consumable by analytics tools such as Tableau and PowerBI.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
In recent years, dataengineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg data lake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Accenture calls it the Intelligent Data Foundation (IDF), and it’s used by dozens of enterprises with very complex data landscapes and analytic requirements. Simply put, IDF standardizes dataengineering processes. IDF works natively on cloud platforms like AWS. Take a look at figure 1 below.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. Before delving into the technical details, let’s review some fundamental concepts.
Modern business operations rely heavily on dataengineering and transformation processes to turn raw data into valuable insights. Matillion, a robust ELT (Extract, Load, Transform) platform, simplifies data integration and transformation complexities with a no-code or high-code experience. What is a Matillion Job?
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. Gateways are being used as another layer of security between Snowflake or clouddata source and Power BI users.
While data fabric takes a product-and-tech-centric approach, data mesh takes a completely different perspective. Data mesh inverts the common model of having a centralized team (such as a dataengineering team), who manage and transform data for wider consumption. But why is such an inversion needed?
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account.
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. Matillion ETL for Snowflake is an ELT/ETL tool that allows for the ingestion, transformation, and building of analytics for data in the Snowflake AI DataCloud.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Azure’s strong focus on security, compliance, and global presence, along with hybrid cloud capabilities and cost management tools, make it an ideal choice for industrial firms seeking to modernize, innovate, and improve efficiency.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
AWS can play a key role in enabling fast implementation of these decentralized clinical trials. By exploring these AWS powered alternatives, we aim to demonstrate how organizations can drive progress towards more environmentally friendly clinical research practices.
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery data warehouse. Athena uses the Athena Google BigQuery connector , which uses a pre-built AWS Lambda function to enable Athena federated query capabilities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content