This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
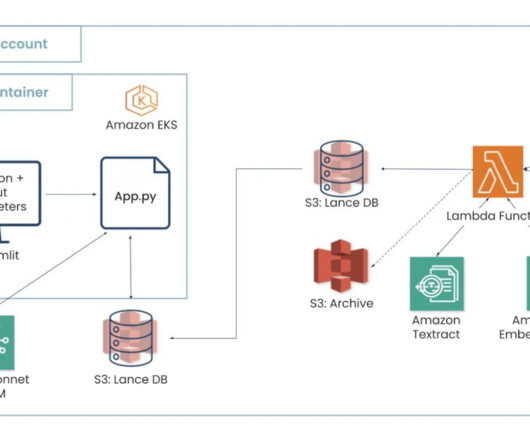
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. A provisioned or serverless Amazon Redshift data warehouse. Choose Create stack. Sohaib Katariwala is a Sr.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. This ensures flexibility and interoperability while using the unique capabilities of each cloud provider.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
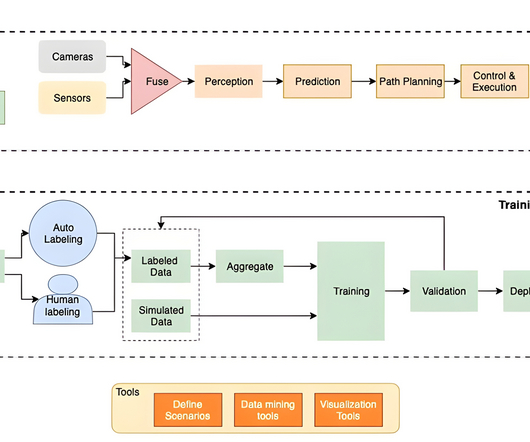
For more information about distributed training with SageMaker, refer to the AWS re:Invent 2020 video Fast training and near-linear scaling with DataParallel in Amazon SageMaker and The science behind Amazon SageMaker’s distributed-training engines. In a later post, we will do a deep dive into the DNNs used by ADAS systems.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
Each platform offers unique capabilities tailored to varying needs, making the platform a critical decision for any Data Science project. Major Cloud Platforms for Data Science Amazon Web Services ( AWS ), Microsoft Azure, and Google Cloud Platform (GCP) dominate the cloud market with their comprehensive offerings.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
which play a crucial role in building end-to-end datapipelines, to be included in your CI/CD pipelines. End-To-End DataPipeline Use Case & Flyway Configuration Let’s consider a scenario where you have the requirement to ingest and process inventory data on an hourly basis.
In this post, we describe how AWS Partner Airis Solutions used Amazon Lookout for Equipment , AWS Internet of Things (IoT) services, and CloudRail sensor technologies to provide a state-of-the-art solution to address these challenges. It’s an easy way to run analytics on IoT data to gain accurate insights.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Data integrations and pipelines can also impact latency.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Cloud Computing Many appreciate cloud computing because of its scalability, elasticity, and ability to offer easy access to users across the globe. With the emergence of cloud hyperscalers like AWS, Google, and Microsoft, the shift to the cloud has accelerated significantly.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddata warehouse like Snowflake.
Modernize in Place (Instead of Rip and Replace) Many appreciate cloud computing because of its scalability, elasticity, and ability to offer easy access to users across the globe. With the emergence of cloud hyperscalers like AWS, Google, and Microsoft, the shift to the cloud has accelerated significantly.
First, private cloud infrastructure providers like Amazon (AWS), Microsoft (Azure), and Google (GCP) began by offering more cost-effective and elastic resources for fast access to infrastructure. Instead of moving customer data to the processing engine, we move the processing engine to the data.
Integration : Can it connect with existing systems like AWS, Azure, or Google Cloud? Integration capabilities are crucial for leveraging cloud services. Airflow is particularly useful for organizations that require flexibility and scalability in their datapipelines.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination.
As enterprise technology landscapes grow more complex, the role of data integration is more critical than ever before. Whether it’s a clouddata warehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs. What data governance controls do your solutions have in place? #9.
Talend Talend is a leading open-source ETL platform that offers comprehensive solutions for data integration, data quality , and clouddata management. It supports both batch and real-time data processing , making it highly versatile. It is well known for its data provenance and seamless data routing capabilities.
This open-source streaming platform enables the handling of high-throughput data feeds, ensuring that datapipelines are efficient, reliable, and capable of handling massive volumes of data in real-time. Prefect’s design is particularly suited for modern cloud-based data environments.
Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Having been built completely for and in the cloud, the Snowflake DataCloud has become an industry leader in clouddata platforms.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
.” Das Kamhout, VP and Senior Principal Engineer of the Cloud and Enterprise Solutions Group at Intel Watsonx.data supports our customers’ increasing needs around hybrid cloud deployments and is available on premises and across multiple cloud providers, including IBM Cloud and Amazon Web Services (AWS).
They created each capability as modules, which can either be used independently or together to build automated datapipelines. IDF works natively on cloud platforms like AWS. In essence, Alation is acting as a foundational data fabric that Gartner describes as being required for DataOps.
To help, phData designed and implemented AI-powered datapipelines built on the Snowflake AI DataCloud , Fivetran, and Azure to automate invoice processing. Migrations from legacy on-prem systems to clouddata platforms like Snowflake and Redshift. This is where AI truly shines.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. But good data—and actionable insights—are hard to get. What is Salesforce DataCloud for Tableau?
In this blog post, we’ll dive into the amazing advantages of using Fivetran , a powerful data integration platform that will revolutionize the way you handle your datapipelines. They established an Information Architecture for Snowflake DataCloud , enabling automated database and role creation.
In this blog post, we’ll dive into the amazing advantages of using Fivetran , a powerful data integration platform that will revolutionize the way you handle your datapipelines. They established an Information Architecture for Snowflake DataCloud , enabling automated database and role creation.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Use with caution, and test before committing to using them.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. Gateways are being used as another layer of security between Snowflake or clouddata source and Power BI users.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. In this example, the secret is an API key, which will be used later on in the pipeline.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content