
Introducing Databricks Fleet Clusters for AWS
databricks
MAY 10, 2023
We're excited to announce the general availability of Databricks Fleet clusters on AWS. What are Fleet clusters? Databricks Fleet clusters unlock the potential.

databricks
MAY 10, 2023
We're excited to announce the general availability of Databricks Fleet clusters on AWS. What are Fleet clusters? Databricks Fleet clusters unlock the potential.

Analytics Vidhya
JANUARY 15, 2023
Introduction to AWS AWS, or Amazon Web Services, is one of the world’s most widely used cloud service providers. AWS has many clusters of data centers in multiple countries across the globe. The post AWS Lambda Tutorial: Creating Your First Lambda Function appeared first on Analytics Vidhya.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Machine Learning Blog
DECEMBER 24, 2024
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.

Analytics Vidhya
APRIL 25, 2022
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: Cloud Data Warehouse Service appeared first on Analytics Vidhya. The datasets range in size from a few 100 megabytes to a petabyte. […].

AWS Machine Learning Blog
NOVEMBER 26, 2024
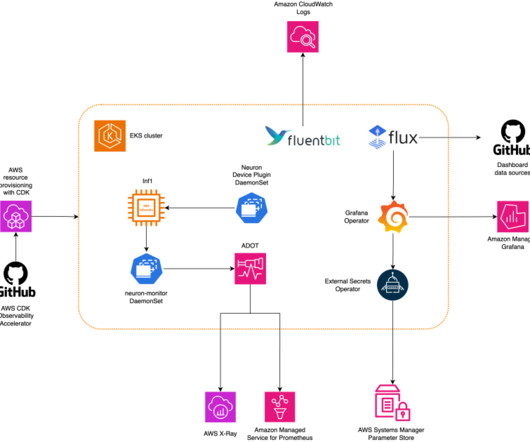
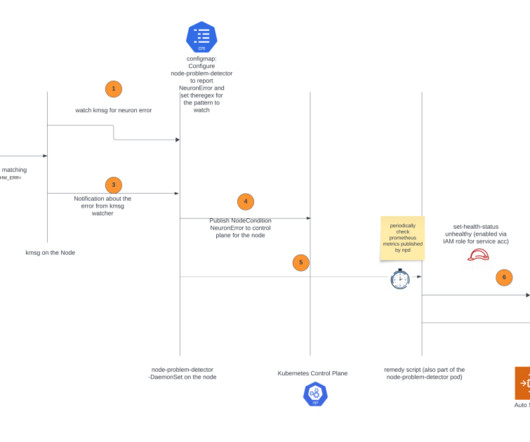
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Solution overview The steps to implement the solution are as follows: Create the EKS cluster.

Analytics Vidhya
AUGUST 3, 2021
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.

AWS Machine Learning Blog
NOVEMBER 19, 2024
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.

Expert insights. Personalized for you.







































Let's personalize your content