This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction to AWSAWS, or Amazon Web Services, is one of the world’s most widely used cloud service providers. AWS has many clusters of data centers in multiple countries across the globe. The post AWS Lambda Tutorial: Creating Your First Lambda Function appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). Choose Create database.
It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning. AWS SageMaker also has a CLI for model creation and management.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. Delete the MongoDB Atlas cluster. As always, AWS welcomes feedback.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. These include dbt pipelines, data gathering jobs, training, evaluation, and batch inference jobs for smaller models.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. SageMaker Studio runs inside an AWS managed virtual private cloud ( VPC ), with network access for SageMaker Studio domains, in this setup configured as VPC-only.
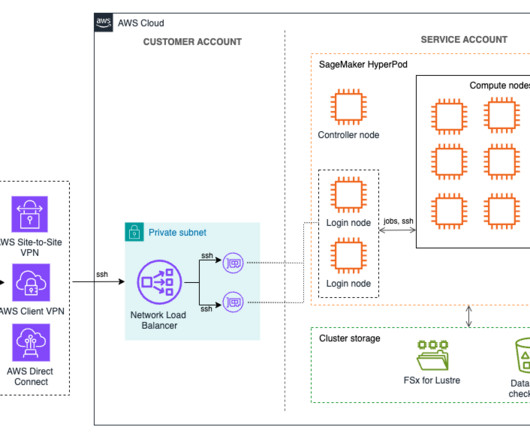
Multiple users such as ML researchers, software engineers, data scientists, and cluster administrators can work concurrently on the same cluster, each managing their own jobs and files without interfering with others. This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator.
In conjunction with tools like RStudio on SageMaker, users are analyzing, transforming, and preparing large amounts of data as part of the data science and ML workflow. Data scientists and dataengineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
However, working with data in the cloud can present challenges, such as the need to remove organizational data silos, maintain security and compliance, and reduce complexity by standardizing tooling. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. 1 Public subnet. 1 NAT gateway.
Prerequisites For this solution we use MongoDB Atlas to store time series data, Amazon SageMaker Canvas to train a model and produce forecasts, and Amazon S3 to store data extracted from MongoDB Atlas. sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas.
As the demand for the data solutions increased, cloud companies like AWS also jumped in and began providing managed data lake solutions with AWS Athena and S3. AWS Athena and S3. AWS Athena and S3 are separate services. AWS Athena and S3 are separate services. Athena is serverless and managed by AWS.
Aggregating and preparing large amounts of data is a critical part of ML workflow. Data scientists and dataengineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. For each option, we deploy a unique stack of AWS CloudFormation templates.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) data lake.
SageMaker Processing enables the flexible scaling of compute clusters to accommodate tasks of varying sizes, from processing a single city block to managing planetary-scale workloads. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
For the first time ever, the DataEngineering Summit will be in person! Co-located with the leading Data Science and AI Training Conference, ODSC East, this summit will gather the leading minds in DataEngineering in Boston on April 23rd and 24th. NET, and AWS. We’re currently hard at work on the lineup.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
You want to gather insights on this data and build an ML model to predict how new restaurants will be rated, but find it challenging to perform analytics on unstructured data. You encounter bottlenecks because you need to rely on dataengineering and data science teams to accomplish these goals.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
Augmenting the training data using techniques like cropping, rotating, and flipping images helped improve the model training data and model accuracy. Model training was accelerated by 50% through the use of the SMDDP library, which includes optimized communication algorithms designed specifically for AWS infrastructure.
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. When the preprocessing batch was complete, the training/test data needed for training was partitioned based on runtime and stored in Amazon S3.
PII Detected tagged documents are fed into Logikcull’s search index cluster for their users to quickly identify documents that contain PII entities. The request is handled by Logikcull’s application servers hosted on Amazon EC2 and the servers communicates with the search index cluster to find the documents.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. These models may include regression, classification, clustering, and more.
Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering. AWS customer Vericast is a marketing solutions company that makes data-driven decisions to boost marketing ROIs for its clients.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
We use an example of an illustrative ServiceNow platform to discuss technical topics related to AWS services. When preparing to connect Amazon Q Business applications to AWS IAM Identity Center , you need to enable ACL indexing and identity crawling and re-synchronize your connector. John has access to all ServiceNow document types.
Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data. You need dataengineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Solutions Architect at AWS. He has a background in AI/ML & big data.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. ML Governance: A Lean Approach Ryan Dawson | Principal DataEngineer | Thoughtworks Meissane Chami | Senior ML Engineer | Thoughtworks During this session, you’ll discuss the day-to-day realities of ML Governance.
Overview By harnessing the power of the Snowflake-Spark connector, you’ll learn how to transfer your data efficiently while ensuring compatibility and reliability. Whether you’re a dataengineer, analyst, or hobbyist, this blog will equip you with the knowledge and tools to confidently make this migration.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
It lets engineers provide simple data transformation functions, then handles running them at scale on Spark and managing the underlying infrastructure. This enables data scientists and dataengineers to focus on the feature engineering logic rather than implementation details. SageMaker Studio set up.
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. On an ongoing basis, we calculate mean absolute percentage error (MAPE) ratios with product-based data, and optimize model and feature ingestion processes.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. The DJL continues to grow in its ability to support different hardware, models, and engines. The architecture of DJL is engine agnostic.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. The first insert statement loads data having c_custkey between 30001 and 40000 – INSERT INTO ib_customers2 SELECT *, '11111111111111' AS HASHKEY FROM snowflake_sample_data.tpch_sf1.customer
This account manages templates for setting up new ML Dev Accounts, as well as SageMaker Projects templates for model development and deployment, in AWS Service Catalog. It also hosts a model registry to store ML models developed by data science teams, and provides a single location to approve models for deployment.
Build Classification and Regression Models with Spark on AWS Suman Debnath | Principal Developer Advocate, DataEngineering | Amazon Web Services This immersive session will cover optimizing PySpark and best practices for Spark MLlib.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content