This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. A provisioned or serverless Amazon Redshift data warehouse. A SageMaker domain. Database name : Enter dev.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can view and create EMR clusters directly through the SageMaker notebook.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses.
It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning. AWS SageMaker also has a CLI for model creation and management.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. The listing indexer AWS Lambda function continuously polls the queue and processes incoming listing updates. For data handling, 24 data nodes (r6gd.2xlarge.search
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). Control plane and data plane implementation SnapLogic’s Agent Creator platform follows a decoupled architecture, separating the control plane and data plane for enhanced security and scalability.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. It is because you usually see Kafka producers publish data or push it towards a Kafka topic so that the application can consume the data.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
Solution workflow In this section, we discuss how the different components work together, from data acquisition to spatial modeling and forecasting, serving as the core of the UHI solution. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. In the following sections, we dive into each pipeline in more detail.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. The full code can be found on the aws-samples-for-ray GitHub repository. It integrates smoothly with other data processing libraries like Spark, Pandas, NumPy, and more, as well as ML frameworks like TensorFlow and PyTorch.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
PII Detected tagged documents are fed into Logikcull’s search index cluster for their users to quickly identify documents that contain PII entities. The request is handled by Logikcull’s application servers hosted on Amazon EC2 and the servers communicates with the search index cluster to find the documents.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
How to Choose a Data Warehouse for Your Big Data Choosing a data warehouse for big data storage necessitates a thorough assessment of your unique requirements. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. It also includes support for new hardware like ARM (both in servers like AWS Graviton and laptops with Apple M1 ) and AWS Inferentia.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
The Cloud represents an iteration beyond the on-prem data warehouse, where computing resources are delivered over the Internet and are managed by a third-party provider. Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Read More: Advanced SQL Tips and Tricks for Data Analysts.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
When building your Processing Docker image, don't place any data required by your container in these directories. The sample bash script will take care of all the AWS-related authentication, create a repository named sm-semantic-similarity, tag it and finally push it to the Amazon ECR repository. docker build -t ${algorithm_name}.
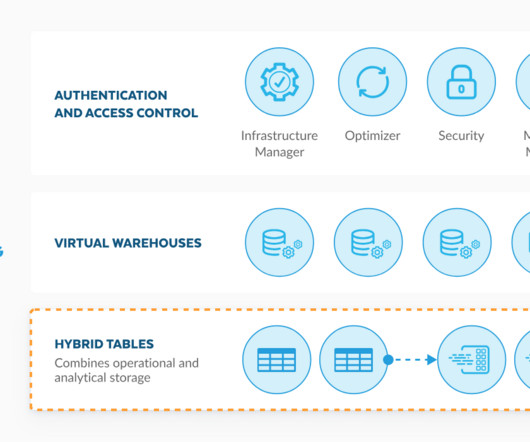
However, it is now available in public preview in specific AWS regions, excluding trial accounts. The real benefit of utilizing Hybrid tables is that they bring transactional and analytical data together in a single platform. Hybrid tables can streamline datapipelines, reduce costs, and unlock deeper insights from data.
The system’s architecture ensures the data flows through the different systems effectively. First, the data lake is fed from a number of data sources. These include conversational data, ATS Data and more. Sense onboarded Iguazio as an MLOps solution for the ML training and serving component of the pipeline.
The system’s architecture ensures the data flows through the different systems effectively. First, the data lake is fed from a number of data sources. These include conversational data, ATS data, and more. Sense onboarded Iguazio as an MLOps platform for the ML training and serving component of the pipeline.
Kafka helps simplify the communication between customers and businesses, using its datapipeline to accurately record events and keep records of orders and cancellations—alerting all relevant parties in real-time. Developers using Apache can speed app development with support for whatever requirements their organization has.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Snowflake stores and manages data in the cloud using a shared disk approach, which simplifies data management. The shared-nothing architecture ensures that users don’t have to worry about distributing data across multiple cluster nodes. The data can then be processed using Snowflake’s SQL capabilities.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Environments Data science environments encompass the tools and platforms where professionals perform their work. From development environments like Jupyter Notebooks to robust cloud-hosted solutions such as AWS SageMaker, proficiency in these systems is critical.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more. Apache Airflow Apache Airflow is an open-source workflow orchestration tool that can manage complex workflows and datapipelines.
Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on. Along with the schedulers, they are integral to managing the regular workflows your data scientists run and how the tasks in those workflows communicate with the ML platform.
Data and workflow orchestration: Ensuring efficient datapipeline management and scalable workflows for LLM performance. Combine this with the serverless BentoCloud or an auto-scaling group on a cloud platform like AWS to ensure your resources match the demand.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content