This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. This same interface is also used for provisioning EMR clusters.
AWS published Guidance for Optimizing MLOps for Sustainability on AWS to help customers maximize utilization and minimize waste in their ML workloads. The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. This leads to substantial resource consumption.
Data scientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. This blog post will go through how data professionals may use SageMaker Data Wrangler’s visual interface to locate and connect to existing Amazon EMR clusters with Hive endpoints.
You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. These features can find temporal patterns in the data that can influence the baseFare.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. The full code can be found on the aws-samples-for-ray GitHub repository.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. Moreover, they require a pre-determined number of topics, which was hard to determine in our data set. The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS. The solution involved two key components: Modifying and extending existing code – The first part of our solution involved the modification and extension of our existing code to make it compatible with AWS infrastructure.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. Prerequisites For this walkthrough, you should have the following prerequisites: An AWS account set up.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. In this section, we cover how to discover these models in SageMaker Studio.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. An execution role update may be required to bring in data browsing and the SQL run feature. You need to create AWS Glue connections with specific connection types.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art natural language processing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers. The recommendation system has driven an 8.6%
Many ML algorithms train over large datasets, generalizing patterns it finds in the data and inferring results from those patterns as new unseen records are processed. With SageMaker, data scientists and developers can quickly build and train ML models, and then deploy them into a production-ready hosted environment.
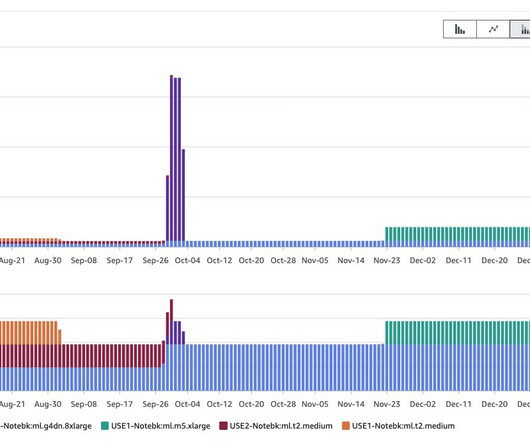
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support offering. In Part 1 , we showed how to get started using AWS Cost Explorer to identify cost optimization opportunities in SageMaker. You can build custom queries to look up AWS CUR data using standard SQL.
0, 1, 2 Reference architecture In this post, we use Amazon SageMaker Data Wrangler to ask a uniform set of visual questions for thousands of photos in the dataset. SageMaker Data Wrangler is purpose-built to simplify the process of datapreparation and feature engineering. in Data Science. Charles holds a M.S.
An AutoML tool applies a combination of different algorithms and various preprocessing techniques to your data. For example, it can scale the data, perform univariate feature selection, conduct PCA at different variance threshold levels, and apply clustering. This solution will incur costs in your AWS account.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. Finally, launching clusters can introduce operational overhead due to longer starting time.
DataPreparation for AI Projects Datapreparation is critical in any AI project, laying the foundation for accurate and reliable model outcomes. This section explores the essential steps in preparingdata for AI applications, emphasising data quality’s active role in achieving successful AI models.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
Table of Contents Introduction to PyCaret Benefits of PyCaret Installation and Setup DataPreparation Model Training and Selection Hyperparameter Tuning Model Evaluation and Analysis Model Deployment and MLOps Working with Time Series Data Conclusion 1. or higher and a stable internet connection for the installation process.
The two most common types of unsupervised learning are clustering , where the algorithm groups similar data points together, and dimensionality reduction , where the algorithm reduces the number of features in the data. It is highly configurable and can integrate with other tools like Git, Docker, and AWS.
Unsupervised Learning Unsupervised learning involves training models on data without labels, where the system tries to find hidden patterns or structures. This type of learning is used when labelled data is scarce or unavailable. Data Transformation Transforming dataprepares it for Machine Learning models.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. UnSupervised Learning Unlike Supervised Learning, unSupervised Learning works with unlabeled data. The algorithm tries to find hidden patterns or groupings in the data.
By implementing efficient data pipelines , organisations can enhance their data processing capabilities, reduce time spent on datapreparation, and improve overall data accessibility. Data Storage Solutions Data storage solutions are critical in determining how data is organised, accessed, and managed.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. You may be expected to use other cloud platforms like AWS, GCP, and others, so don’t neglect them and at least be vaguely familiar with how they work.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems. Environments are the actual data infrastructure behind a project.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
Data Management Costs Data Collection : Involves sourcing diverse datasets, including multilingual and domain-specific corpora, from various digital sources, essential for developing a robust LLM. While the use of pre-trained models is free, fine-tuning them for specific tasks can lead to costs related to computing and data handling.
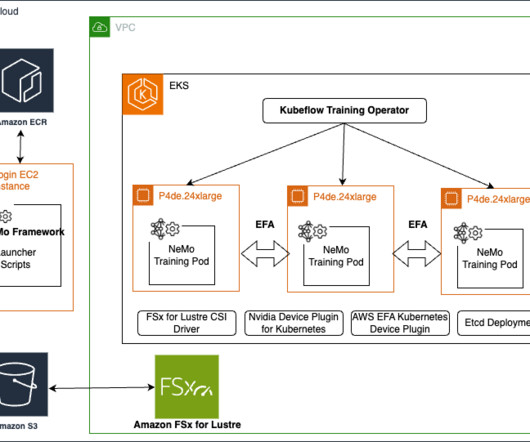
In this post, we present a step-by-step guide to run distributed training workloads on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from datapreparation to training and deployment.
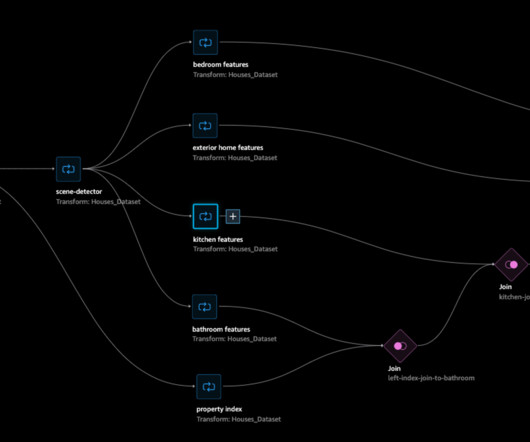
3 Quickly build and deploy an end-to-end ML pipeline with Kubeflow Pipelines on AWS. Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Pre-requisites In this demo, you will use MiniKF to set up Kubeflow on AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content