This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and datascience team’s bandwidth and data preparation activities.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Welcome to the first beta edition of Cloud DataScience News. This will cover major announcements and news for doing datascience in the cloud. Azure Synapse Analytics This is the future of data warehousing. If you are at a University or non-profit, you can ask for cash and/or AWS credits. Microsoft Azure.
It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning. AWS SageMaker also has a CLI for model creation and management.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Datascience is a growing profession. Standards and expectations are rapidly changing, especially in regards to the types of technology used to create datascience projects. Most data scientists are using some form of DevOps interface these days. Benefits of Kubernetes for DataScience.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Health Insurance Portability and Accountability Act (HIPAA) eligibility and General Data Protection Regulation (GDPR) compliance.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
This article was published as a part of the DataScience Blogathon. Introduction In machine learning, the data is an essential part of the training of machine learning algorithms. The amount of data and the data quality highly affect the results from the machine learning algorithms.
They fine-tuned this model using their proprietary dataset and in-house datascience expertise. Integration with existing systems on AWS: Lumi seamlessly integrated SageMaker Asynchronous Inference endpoints with their existing loan processing pipeline. The pipeline leverages several AWS services familiar to Lumis team.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
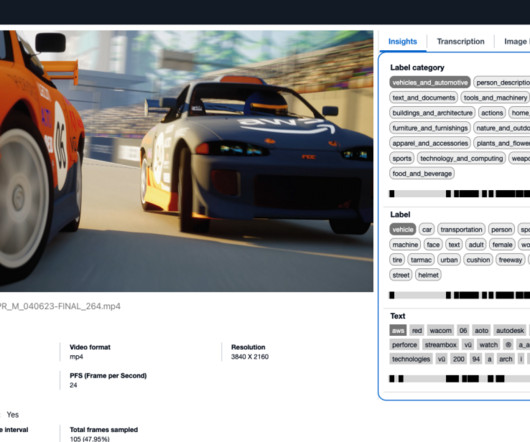
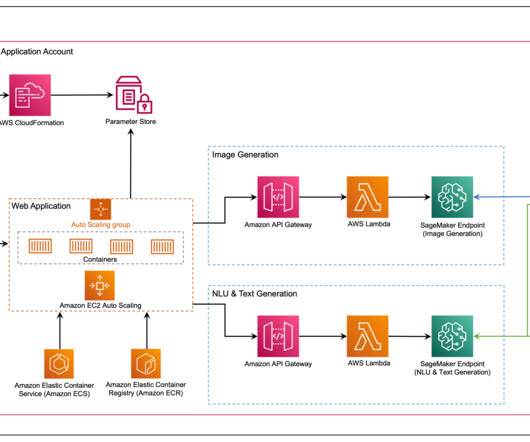
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs.
This article was published as a part of the DataScience Blogathon. Introduction on Amazon Elasticsearch Service Amazon Elasticsearch Service is a powerful tool that allows you to perform a number of functions. Let us examine how this powerful tool works behind the scenes.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
In April 2023, AWS unveiled Amazon Bedrock , which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs , Anthropic , and Stability AI. Amazon Bedrock also offers access to Titan foundation models, a family of models trained in-house by AWS. Deploy the AWS CDK application.
The need for federated learning in healthcare Healthcare relies heavily on distributed data sources to make accurate predictions and assessments about patient care. Limiting the available data sources to protect privacy negatively affects result accuracy and, ultimately, the quality of patient care.
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
By using the Livy REST APIs , SageMaker Studio users can also extend their interactive analytics workflows beyond just notebook-based scenarios, enabling a more comprehensive and streamlined datascience experience within the Amazon SageMaker ecosystem. This same interface is also used for provisioning EMR clusters.
Because embeddings are an important source of data for NLP models in general and generative AI solutions in particular, we need a way to measure whether our embeddings are changing over time (drifting). Then we use K-Means to identify a set of cluster centers.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
The SageMaker Python SDK automatically translates your existing workspace environment, and any associated data processing code and datasets, into an SageMaker training job that runs on the training platform. For details, refer to Creating an AWS account. In this post, we use Amazon SageMaker Studio with the DataScience 3.0
Our unstructured data comes from the Amazon EC2 User Guide for Linux Instances and Amazon EC2 Instance Types documentation, and the structured data is derived from the EC2 Instance On-Demand Pricing for the US East (N. Virginia) AWS Region. file for deploying the solution using the AWS CDK. xlarge instance to $24.78
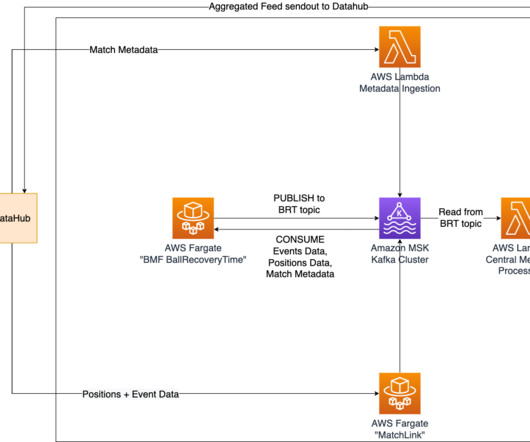
The match-related data is collected and ingested using DFL’s DataHub. Metadata of the match is processed within the AWS Lambda function MetaDataIngestion , while positional data is ingested using the AWS Fargate container called MatchLink. Tareq Haschemi is a consultant within AWS Professional Services.
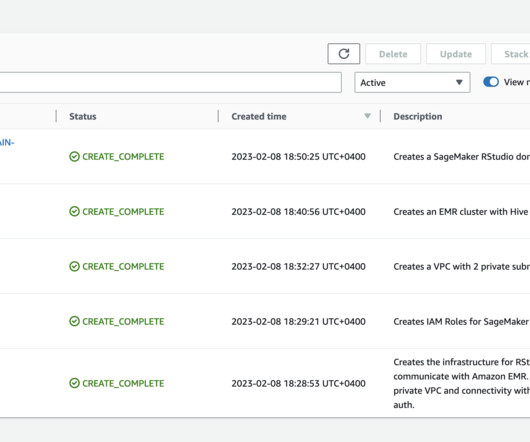
However, working with data in the cloud can present challenges, such as the need to remove organizational data silos, maintain security and compliance, and reduce complexity by standardizing tooling. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. 1 Public subnet. 1 NAT gateway.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
In conjunction with tools like RStudio on SageMaker, users are analyzing, transforming, and preparing large amounts of data as part of the datascience and ML workflow. Data scientists and data engineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework , which is used to build production infrastructure and applications on AWS. To learn more, see Log Amazon Bedrock API calls using AWS CloudTrail.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
While specific requirements may vary depending on the organization and the role, here are the key skills and educational background that are required for entry-level data scientists — Skillset Mathematical and Statistical Foundation Datascience heavily relies on mathematical and statistical concepts.
Because they’re in a highly regulated domain, HCLS partners and customers seek privacy-preserving mechanisms to manage and analyze large-scale, distributed, and sensitive data. To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data.
The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know datascience and in turn, NLP.
Each node is capable of processing and storing data independently. Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes.
It supports various data types and offers advanced features like data sharing and multi-cluster warehouses. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). It is known for its high performance and cost-effectiveness.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. It is hosted on Amazon Elastic Container Service (Amazon ECS) with AWS Fargate , and it is accessed using an Application Load Balancer. It serves as the data source to the knowledge base.
We used AWS services including Amazon Bedrock , Amazon SageMaker , and Amazon OpenSearch Serverless in this solution. The data is sent to the Amazon Titan Text Embeddings model to generate embeddings. Use AWS CloudFormation to create the solution stack You can use AWS CloudFormation to create the solution stack.
When the ML lifecycle is not properly streamlined with MLOps, organizations face issues such as inconsistent results due to varying data quality, slower deployment as manual processes become bottlenecks, and difficulty maintaining and updating models rapidly enough to react to changing business conditions.
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. Originally posted on OpenDataScience.com Read more datascience articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels!
You want to gather insights on this data and build an ML model to predict how new restaurants will be rated, but find it challenging to perform analytics on unstructured data. You encounter bottlenecks because you need to rely on data engineering and datascience teams to accomplish these goals.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content