This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
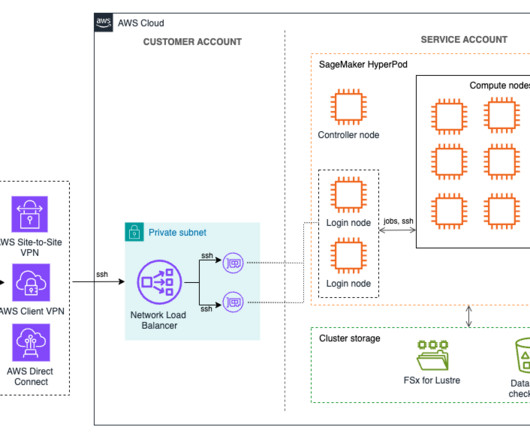
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
Standards and expectations are rapidly changing, especially in regards to the types of technology used to create data science projects. Most datascientists are using some form of DevOps interface these days. There are a lot of important nuances for datascientists using Kubernetes. Why Serverless in Kubernetes?
Despite the availability of advanced distributed training libraries, it’s common for training and inference jobs to need hundreds of accelerators (GPUs or purpose-built ML chips such as AWS Trainium and AWS Inferentia ), and therefore tens or hundreds of instances. or later NPM version 10.0.0
It allows datascientists and machine learning engineers to interact with their data and models and to visualize and share their work with others with just a few clicks. SageMaker Canvas has also integrated with Data Wrangler , which helps with creating data flows and preparing and analyzing your data.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
SageMaker HyperPod recipes help datascientists and developers of all skill sets to get started training and fine-tuning popular publicly available generative AI models in minutes with state-of-the-art training performance. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
It allows datascientists to build models that can automate specific tasks. It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning.
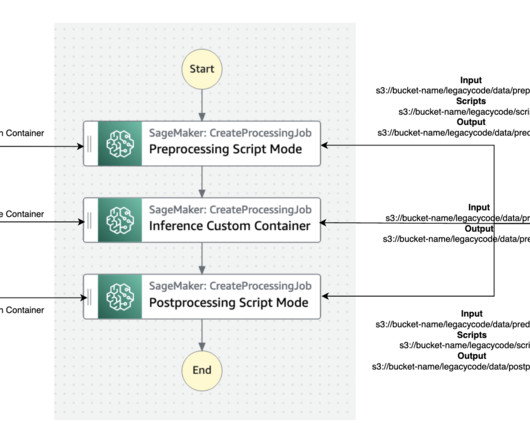
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. We demonstrate how two different personas, a datascientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
This is a guest post co-authored with Ville Tuulos (Co-founder and CEO) and Eddie Mattia (DataScientist) of Outerbounds. For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time.
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. Surya Kari is a Senior Generative AI DataScientist at AWS.
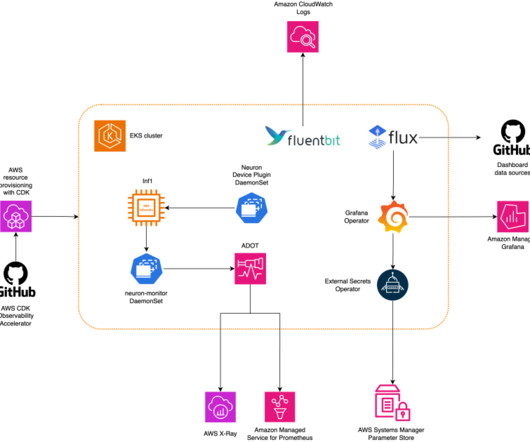
A challenge for DevOps engineers is the additional complexity that comes from using Kubernetes to manage the deployment stage while resorting to other tools (such as the AWS SDK or AWS CloudFormation ) to manage the model building pipeline. kubectl for working with Kubernetes clusters. eksctl for working with EKS clusters.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Seamless integration with SageMaker – As a built-in feature of the SageMaker platform, the EMR Serverless integration provides a unified and intuitive experience for datascientists and engineers. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Multiple users such as ML researchers, software engineers, datascientists, and cluster administrators can work concurrently on the same cluster, each managing their own jobs and files without interfering with others. This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator.
Our unstructured data comes from the Amazon EC2 User Guide for Linux Instances and Amazon EC2 Instance Types documentation, and the structured data is derived from the EC2 Instance On-Demand Pricing for the US East (N. Virginia) AWS Region. file for deploying the solution using the AWS CDK. xlarge instance to $24.78
However, working with data in the cloud can present challenges, such as the need to remove organizational data silos, maintain security and compliance, and reduce complexity by standardizing tooling. AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. 1 Public subnet. 1 NAT gateway.
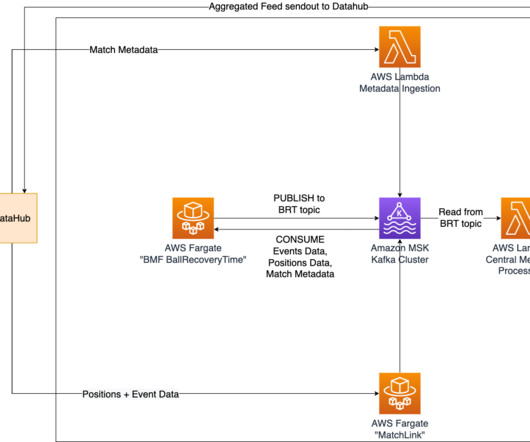
The match-related data is collected and ingested using DFL’s DataHub. Metadata of the match is processed within the AWS Lambda function MetaDataIngestion , while positional data is ingested using the AWS Fargate container called MatchLink. Tareq Haschemi is a consultant within AWS Professional Services.
In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework , which is used to build production infrastructure and applications on AWS. To learn more, see Log Amazon Bedrock API calls using AWS CloudTrail.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge. sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas. Note we have two folders.
The listing indexer AWS Lambda function continuously polls the queue and processes incoming listing updates. With Amazon OpenSearch Service, you get a fully managed solution that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. For data handling, 24 data nodes (r6gd.2xlarge.search
During the iterative research and development phase, datascientists and researchers need to run multiple experiments with different versions of algorithms and scale to larger models. However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise.
SageMaker geospatial capabilities make it straightforward for datascientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
In conjunction with tools like RStudio on SageMaker, users are analyzing, transforming, and preparing large amounts of data as part of the data science and ML workflow. Datascientists and data engineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
There are two main purposes for building this pipeline: support the datascientists for late-stage model development, and surface model predictions in the product by serving models in high volume and in real-time production traffic. Amazon SNS is fully managed pub/sub service for A2A and A2P messaging.
Because they’re in a highly regulated domain, HCLS partners and customers seek privacy-preserving mechanisms to manage and analyze large-scale, distributed, and sensitive data. To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data.
Infrastructure and development challenges Veriff’s backend architecture is based on a microservices pattern, with services running on different Kubernetes clusters hosted on AWS infrastructure. These APIs required production-grade code, which made it challenging for datascientists to productionize models.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge. Data Science Layers. Software Development Layers.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
Aggregating and preparing large amounts of data is a critical part of ML workflow. Datascientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. For each option, we deploy a unique stack of AWS CloudFormation templates.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Solution overview Amazon Transcribe is the go-to service for speaker diarization in AWS. Make sure the AWS account has a service quota for hosting a SageMaker endpoint for an ml.g5.2xlarge instance.
Many AWS media and entertainment customers license IMDb data through AWSData Exchange to improve content discovery and increase customer engagement and retention. In Part 1 , we discussed the applications of GNNs and how to transform and prepare our IMDb data into a knowledge graph (KG). Background. Prerequisites.
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. We also deep dive into the most common architectures and AWS resources to facilitate these integrations. In some cases, an ISV may deploy their software in the customer AWS account.
One of the several challenges faced was adapting the existing on-premises pipeline solution for use on AWS. The solution involved two key components: Modifying and extending existing code – The first part of our solution involved the modification and extension of our existing code to make it compatible with AWS infrastructure.
Given that, what would you say is the job of a datascientist (or ML engineer, or any other such title)? A common task for a datascientist is to build a predictive model. You know the drill: pull some data, carve it up into features, feed it into one of scikit-learn’s various algorithms. Building Models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content