This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The datasets range in size from a few 100 megabytes to a petabyte. […].
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. For this post we’ll use a provisioned Amazon Redshift cluster. Database name : Enter dev.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. The user query is used to retrieve relevant additional context from the vector database. The user receives a more accurate response based on their query.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Solution overview The following diagram provides a high-level overview of AWS services and features through a sample use case.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
One of the best known options is Amazon Web Services (AWS). What is Amazon Web Services (AWS)? AWS is a collection of remote computing services (or web services). AWS Cloud is a suite of hosting products used by such services as Dropbox, Reddit, and others. AWS is a cloud computing service. AWS Lambda.
At AWS, we have played a key role in democratizing ML and making it accessible to anyone who wants to use it, including more than 100,000 customers of all sizes and industries. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. The framework for connecting Anthropic Claude 2 and CBRE’s sample database was implemented using LangChain.
In this journey, we are seeing an increased interest in migrating and deploying MAS on AWS Cloud. The growing need for Maximo migration to AWS Cloud Migrating to cloud helps organizations to drive the operational resiliency and reliability, at the same time keeping software up to date with minimal upgrade effort and infrastructure constraint.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. The implementation included a provisioned three-node sharded OpenSearch Service cluster.
In this post, we describe the scale of our AI offerings, the challenges with diverse AI workloads, and how we optimized mixed AI workload inference performance with AWS Graviton3 based c7g instances and achieved 20% throughput improvement, 30% latency reduction, and reduced our cost by 25–30%.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. Pre-built templates tailored to various use cases are included, significantly enhancing both employee and customer experiences.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. IAM roles : Assign appropriate AWS Identity and Access Management (IAM) roles to the tasks for accessing other AWS resources securely.
To aid in building more sustainable IT estates, IBM has partnered up with Amazon Web Services (AWS) to facilitate sustainable cloud modernization journeys. To read about other key scenarios and entry points of IBM Consulting® Custom Lens for Sustainability, check out the blog post: Sustainable App Modernization Using AWS Cloud.
As described in the AWS Well-Architected Framework , separating workloads across accounts enables your organization to set common guardrails while isolating environments. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts. Select VPC Only , then choose Next.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. You can use the provided AWS CloudFormation stack to set up the architectural components for this solution.
Elasticsearch acts a lot like a database and a distributed system […]. Introduction on Amazon Elasticsearch Service Amazon Elasticsearch Service is a powerful tool that allows you to perform a number of functions. Let us examine how this powerful tool works behind the scenes.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. To retrieve data from database, you can use foundation models (FMs) offered by Amazon Bedrock, converting text into SQL queries with specified constraints. Virginia) AWS Region.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. SageMaker Studio runs inside an AWS managed virtual private cloud ( VPC ), with network access for SageMaker Studio domains, in this setup configured as VPC-only.
The listing indexer AWS Lambda function continuously polls the queue and processes incoming listing updates. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems. For data handling, 24 data nodes (r6gd.2xlarge.search
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. In this pattern, the recipe text is converted into embedding vectors using an embedding model, and stored in a vector database.
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. I acknowledge that AWS CloudFormation might create IAM resources with custom names.
Key AWS services used include: Amazon Bedrock Including Anthropics Claude 3.5 Additionally, if a user tells the assistant something that should be remembered, we store this piece of information in a database and add it to the context every time the user initiates a request.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the first post , we described FL concepts and the FedML framework.
Java is 1000 times faster than today’s database systems. While programming languages like Java offer microsecond processing speeds, external database servers that have been utilized for data processing over the past 40 years, are 1000 times slower with millisecond processing speeds.
MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Make sure you have the following prerequisites: Create an S3 bucket Configure MongoDB Atlas cluster Create a free MongoDB Atlas cluster by following the instructions in Create a Cluster.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Finally, select your read preference.
For example, you can visually explore data sources like databases, tables, and schemas directly from your JupyterLab ecosystem. After you have set up connections (illustrated in the next section), you can list data connections, browse databases and tables, and inspect schemas. This new feature enables you to perform various functions.
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. An SSL certificate created and imported into AWS Certificate Manager (ACM). Open an SSH client.
Webex works with the world’s leading business and productivity apps—including AWS. The following diagram illustrates the WxAI architecture on AWS. Its solutions are underpinned with security and privacy by design.
Using RStudio on SageMaker and Amazon EMR together, you can continue to use the RStudio IDE for analysis and development, while using Amazon EMR managed clusters for larger data processing. In this post, we demonstrate how you can connect your RStudio on SageMaker domain with an EMR cluster. Choose Create stack.
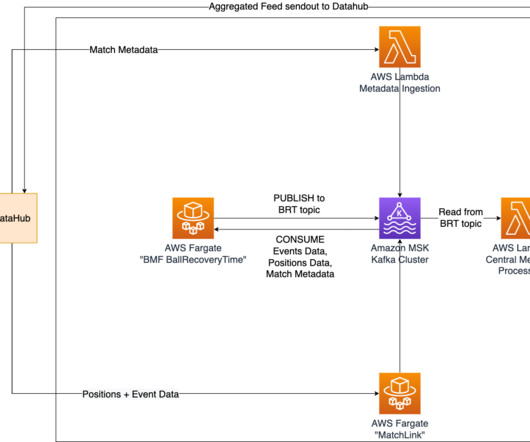
Metadata of the match is processed within the AWS Lambda function MetaDataIngestion , while positional data is ingested using the AWS Fargate container called MatchLink. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. As the demand for the data solutions increased, cloud companies like AWS also jumped in and began providing managed data lake solutions with AWS Athena and S3. AWS Athena and S3. Indexing capabilities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content