This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWSDeepLearning AMIs) and Neuron DLCs (AWSDeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS Systems Manager Parameter Store support Neuron 2.18
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and Request a Service Quota for 1x p4d.24xlarge
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. Therefore, we have two different options. Amazon Linux 2) ????????'
Prime Air (our drones) and the computer vision technology in Amazon Go (our physical retail experience that lets consumers select items off a shelf and leave the store without having to formally check out) use deeplearning. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS). The Container Insights dashboard also shows cluster status and alarms.
In this post, we describe how we built our cutting-edge productivity agent NinjaLLM, the backbone of MyNinja.ai, using AWS Trainium chips. For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. The following diagram shows an example.
In this post, we describe the scale of our AI offerings, the challenges with diverse AI workloads, and how we optimized mixed AI workload inference performance with AWS Graviton3 based c7g instances and achieved 20% throughput improvement, 30% latency reduction, and reduced our cost by 25–30%.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. Zeta’s AI innovation is powered by a proprietary machine learning operations (MLOps) system, developed in-house.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
Libraries such as DeepSpeed (an open-source deeplearning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training. Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. Pre-training of a 1.5-billion-parameter
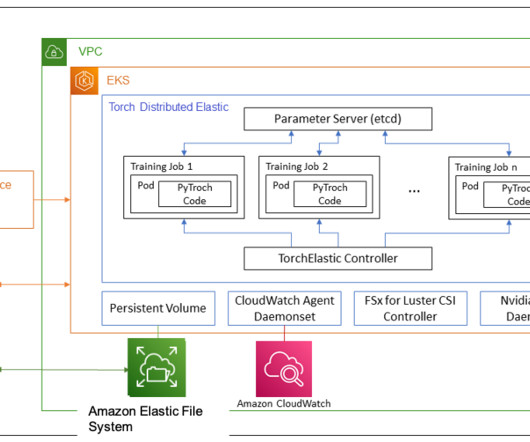
Since then, this feature has been integrated into many of our managed Amazon Machine Images (AMIs), such as the DeepLearning AMI and the AWS ParallelCluster AMI. Prerequisites To simplify reproducing the entire stack from this post, we use a container that has all the required tooling (aws cli, eksctl, helm, etc.)
Similar to the rest of the industry, the advancements of accelerated hardware have allowed Amazon teams to pursue model architectures using neural networks and deeplearning (DL). Last year, AWS launched its AWS Trainium accelerators, which optimize performance per cost for developing and building next generation DL models.
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. The following diagram illustrates the solution architecture.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Integrating tensor parallelism to enable training on massive clusters This release of SMP also expands PyTorch FSDP’s capabilities to include tensor parallelism techniques.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machine learning (ML) model from distributed health data held locally at different sites. Request a VPC peering connection.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities.
In this post, we review the technical requirements and application design considerations for fine-tuning and serving hyper-personalized AI models at scale on AWS. Second, SageMaker supports unique GPU-enabled hosting options for deploying deeplearning models at scale.
To add to our guidance for optimizing deeplearning workloads for sustainability on AWS , this post provides recommendations that are specific to generative AI workloads. Adopt an efficient inference infrastructure – You can deploy your models on an AWS Inferentia2 accelerator.
AWS published Guidance for Optimizing MLOps for Sustainability on AWS to help customers maximize utilization and minimize waste in their ML workloads. In this blog post, you will learn how to optimize MLOps for sustainability. Start with the AWS Region you choose for your workload.
Webex’s focus on delivering inclusive collaboration experiences fuels their innovation, which uses artificial intelligence (AI) and machine learning (ML), to remove the barriers of geography, language, personality, and familiarity with technology. Webex works with the world’s leading business and productivity apps—including AWS.
Hyperparameter optimization is highly computationally demanding for deeplearning models. In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. The code can be found on the GitHub repo.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload.
We are excited to announce a new version of the Amazon SageMaker Operators for Kubernetes using the AWS Controllers for Kubernetes (ACK). ACK is a framework for building Kubernetes custom controllers, where each controller communicates with an AWS service API. They are also supported by AWS CloudFormation. Release v1.2.9
In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework , which is used to build production infrastructure and applications on AWS. We focus on the operational excellence pillar in this post.
Walkthrough AWS-optimized AllGather AWS-optimized AllGather uses the following techniques to achieve better performance on AWS infrastructure compared to NCCL: We move data between instances via Elastic Fabric Adapter (EFA) network with an all-to-all communication pattern. 24xlarge nodes (512 NVIDIA A100 GPUs) PyTorch FSDP 97.89
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod , an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale. So, for example, a 6.6B
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content