This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
dbt helps manage data transformation by enabling teams to deploy analytics code following software engineering best practices such as modularity, continuous integration and continuous deployment (CI/CD), and embedded documentation. Choose the us-east-1 AWS Region in which to create the stack. Create dbt models in dbt Cloud.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
Despite the availability of advanced distributed training libraries, it’s common for training and inference jobs to need hundreds of accelerators (GPUs or purpose-built ML chips such as AWS Trainium and AWS Inferentia ), and therefore tens or hundreds of instances. or later NPM version 10.0.0
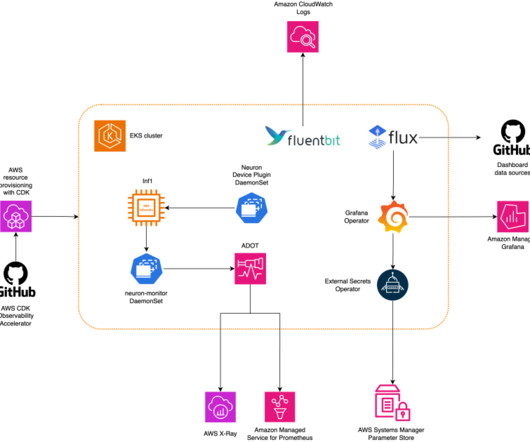
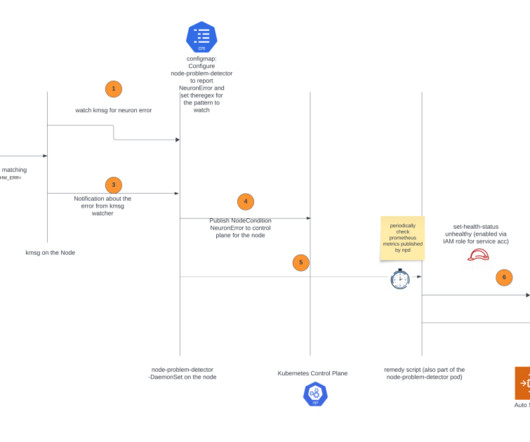
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). eks-5e0fdde Install the required AWS Identity and Access Management (IAM) role for the service account and the node problem detector plugin.
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). Choose Create database.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. SageMaker Studio runs inside an AWS managed virtual private cloud ( VPC ), with network access for SageMaker Studio domains, in this setup configured as VPC-only.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
These longer sequence lengths allow models to better understand long-range dependencies in text, generate more globally coherent outputs, and handle tasks requiring analysis of lengthy documents. After they’re initiated, SageMaker training jobs spin up the cluster, provisioning the specified number and type of compute instances.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster.
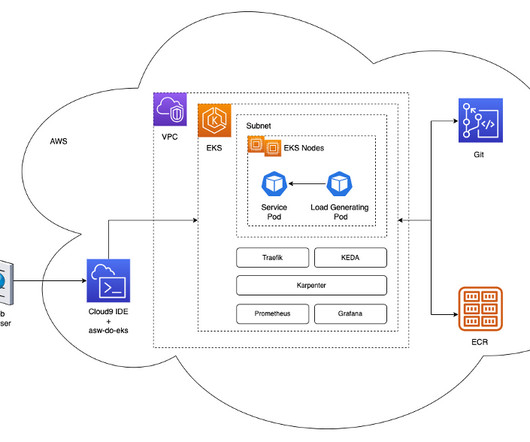
A challenge for DevOps engineers is the additional complexity that comes from using Kubernetes to manage the deployment stage while resorting to other tools (such as the AWS SDK or AWS CloudFormation ) to manage the model building pipeline. kubectl for working with Kubernetes clusters. eksctl for working with EKS clusters.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium —a purpose-built machine learning (ML) accelerator optimized to provide a high-performance, cost-effective, and massively scalable platform for training deep learning models in the cloud. 32xlarge instances.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
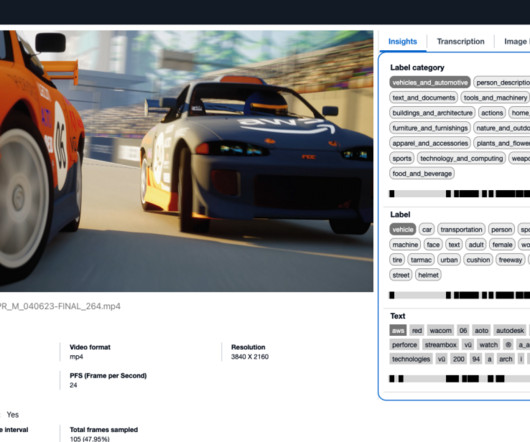
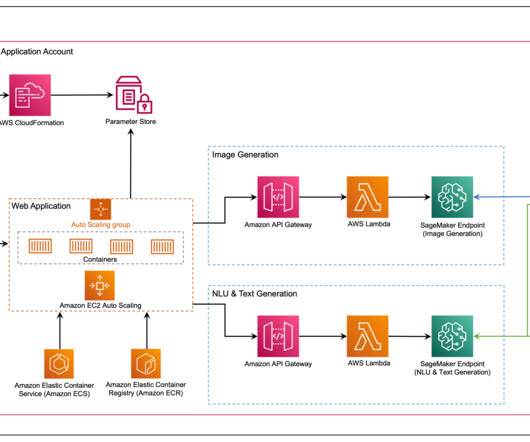
In this post, we introduce the Media Analysis and Policy Evaluation solution, which uses AWS AI and generative AI services to provide a framework to streamline video extraction and evaluation processes. This solution, powered by AWS AI and generative AI services, meets these needs. This sample includes a basic inline policy.
Original content production, code generation, customer service enhancement, and document summarization are typical use cases of generative AI. In April 2023, AWS unveiled Amazon Bedrock , which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs , Anthropic , and Stability AI.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. The following diagram shows an example.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption. This speeds up the PII detection process and also reduces the overall cost.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts. These stages are applicable to both use case and model stages.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
Therefore, ML creates challenges for AWS customers who need to ensure privacy and security across distributed entities without compromising patient outcomes. Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. As always, AWS welcomes your feedback.
To ease this transition for customers unfamiliar with running containers in production, Amazon Web Services (AWS) has partnered with IBM and Red Hat to develop an IBM MAS on Red Hat OpenShift Service for AWS (ROSA) reference architecture. Why ROSA for Maximo in AWS? There are several advantages of IBM MAS SaaS on AWS.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. For example, imagine a consulting firm that manages documentation for multiple healthcare providerseach customers sensitive patient records and operational documents must remain strictly separated.
OpenAI launched GPT-4o in May 2024, and Amazon introduced Amazon Nova models at AWS re:Invent in December 2024. One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data.
For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information. These PDFs will serve as the source for generating document chunks. Open SageMaker Studio. Test the deployed model.
Companies across various industries create, scan, and store large volumes of PDF documents. There’s a need to find a scalable, reliable, and cost-effective solution to translate documents while retaining the original document formatting. It also uses the open-source Java library Apache PDFBox to create PDF documents.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. An AWS Identity and Access Management (IAM) role to access SageMaker.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. To learn more about the SageMaker model parallel library, refer to SageMaker model parallelism library v2 documentation. You can also refer to our example notebooks to get started.
The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. Karpenter monitors for any pending pods that can’t run due to lack of sufficient resources in the cluster. If such pods are detected, Karpenter adds more nodes to the cluster to provide the necessary resources.
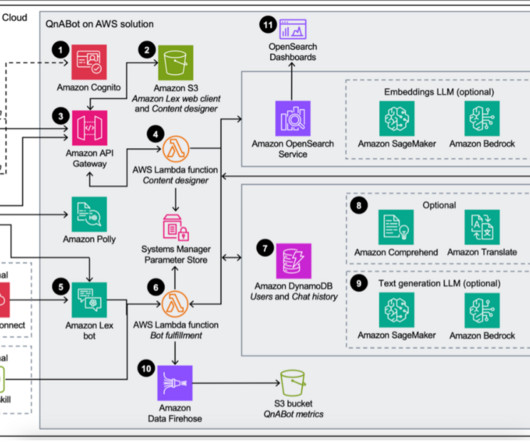
QnABot on AWS (an AWS Solution) now provides access to Amazon Bedrock foundational models (FMs) and Knowledge Bases for Amazon Bedrock , a fully managed end-to-end Retrieval Augmented Generation (RAG) workflow. Deploying the QnABot solution builds the following environment in the AWS Cloud.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities.
As described in the AWS Well-Architected Framework , separating workloads across accounts enables your organization to set common guardrails while isolating environments. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts. Select VPC Only , then choose Next.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. Amazon’s AWS Glue is one such tool that allows you to consume data from Apache Kafka and Amazon-managed streaming for Apache Kafka (MSK).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content