This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
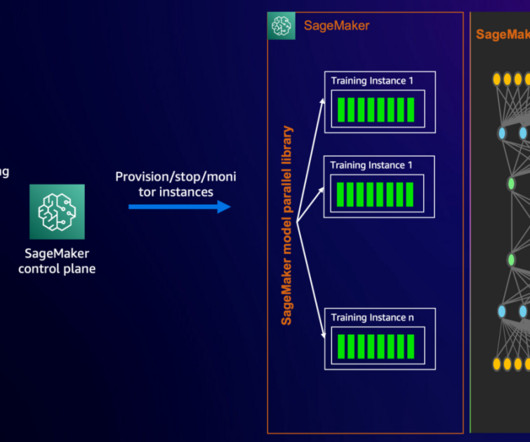
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
Prerequisites To implement the proposed solution, make sure that you have the following: An AWS account and a working knowledge of FMs, Amazon Bedrock , Amazon SageMaker , Amazon OpenSearch Service , Amazon S3 , and AWS Identity and Access Management (IAM). Amazon Titan Multimodal Embeddings model access in Amazon Bedrock.
Prerequisites Before you begin, make sure you have the following prerequisites in place: An AWS account and role with the AWS Identity and Access Management (IAM) privileges to deploy the following resources: IAM roles. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain. Database name : Enter dev.
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. These batches are then evenly distributed across the machines in a cluster. format("/".join(tile_prefix),
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. Choose Create database. aligned identity provider (IdP).
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Additionally, you can securely integrate and easily deploy your generative AI applications using the AWS tools you are already familiar with.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
In this post, we describe the scale of our AI offerings, the challenges with diverse AI workloads, and how we optimized mixed AI workload inference performance with AWS Graviton3 based c7g instances and achieved 20% throughput improvement, 30% latency reduction, and reduced our cost by 25–30%.
In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium —a purpose-built machine learning (ML) accelerator optimized to provide a high-performance, cost-effective, and massively scalable platform for training deep learning models in the cloud. 32xlarge instances.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and data integrity in the secure AWS environment. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
Therefore, ML creates challenges for AWS customers who need to ensure privacy and security across distributed entities without compromising patient outcomes. Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. You can also download these models from the website.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. The following diagram shows an example.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
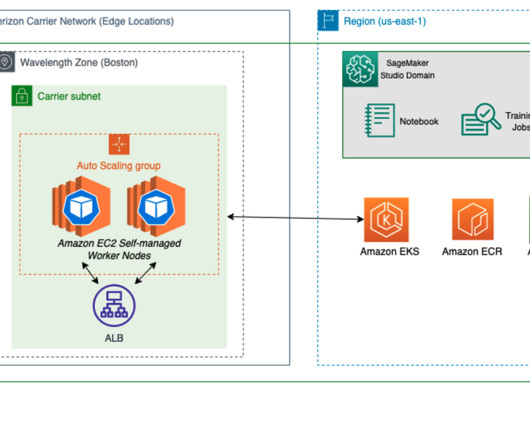
To reduce the barrier to entry of ML at the edge, we wanted to demonstrate an example of deploying a pre-trained model from Amazon SageMaker to AWS Wavelength , all in less than 100 lines of code. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
Distributed model training requires a cluster of worker nodes that can scale. In this blog post, AWS collaborates with Meta’s PyTorch team to discuss how to use the PyTorch FSDP library to achieve linear scaling of deep learning models on AWS seamlessly using Amazon EKS and AWS Deep Learning Containers (DLCs).
As described in the AWS Well-Architected Framework , separating workloads across accounts enables your organization to set common guardrails while isolating environments. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts.
Since then, this feature has been integrated into many of our managed Amazon Machine Images (AMIs), such as the Deep Learning AMI and the AWS ParallelCluster AMI. Prerequisites To simplify reproducing the entire stack from this post, we use a container that has all the required tooling (aws cli, eksctl, helm, etc.) already installed.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
In 2021, we launched AWS Support Proactive Services as part of the AWS Enterprise Support plan. SageMaker supports various data sources and access patterns, distributed training including heterogenous clusters, as well as experiment management features and automatic model tuning.
It’s straightforward to deploy in your AWS account. Prerequisites You need to have an AWS account and an AWS Identity and Access Management (IAM) role and user with permissions to create and manage the necessary resources and components for this application. Everything you need is provided as open source in our GitHub repo.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. Create database connections The built-in SQL browsing and execution capabilities of SageMaker Studio are enhanced by AWS Glue connections. or later image versions.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload.
Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. billion-parameter model using the wikicorpus-en dataset. Pre-training of a 1.5-billion-parameter
Prerequisites To implement this solution, complete the following prerequisites: Have AWS Cloud admin access with an AWS Identity and Access Management (IAM) user with permissions required to complete the integration. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Choose Add connection.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Solution overview Amazon Transcribe is the go-to service for speaker diarization in AWS. Make sure the AWS account has a service quota for hosting a SageMaker endpoint for an ml.g5.2xlarge instance.
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Using SageMaker in conjunction with various AWS services has given us many advantages in developing and operating our services.
We used AWS services including Amazon Bedrock , Amazon SageMaker , and Amazon OpenSearch Serverless in this solution. In this series, we use the slide deck Train and deploy Stable Diffusion using AWS Trainium & AWS Inferentia from the AWS Summit in Toronto, June 2023 to demonstrate the solution.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. These models are released under different licenses designated by their respective sources.
Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention. We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. Background. Prerequisites.
When it comes to ML, this restricts data scientists from downloading any package from public repositories like PyPI , Anaconda , or Conda-Forge. The high-level steps to implement the solution are as follows Set up a virtual private cloud (VPC) with no internet access using an AWS CloudFormation template.
The model weights are available to download, inspect and deploy anywhere. SageMaker Training provisions compute clusters with user-defined hardware configuration and code. TII used transient clusters provided by the SageMaker Training API to train the Falcon LLM, up to 48 ml.p4d.24xlarge
The high-level steps are as follows: Set up an Amazon SageMaker Studio environment with the necessary AWS Identity and Access Management (IAM) policies. The process involves the following steps: Download the training and validation data, which consists of PDFs from Uber and Lyft 10K documents. Open SageMaker Studio.
We use a combination of different AWS services, open-source foundation models ( FLAN-T5 XXL for text generation and GPT-j-6B for embeddings) and packages such as LangChain for interfacing with all the components and Streamlit for building the bot frontend. AWS Identity and Access Management roles and policies for access management.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content