This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. Understanding the ETL Process. Before you understand what is ETL tool , you need to understand the ETL Process first. Types of ETL Tools.
In this post, we explore how you can use Amazon Q Business , the AWS generative AI-powered assistant, to build a centralized knowledge base for your organization, unifying structured and unstructured datasets from different sources to accelerate decision-making and drive productivity. Choose Create database. aligned identity provider (IdP).
It provides a large cluster of clusters on a single machine. SageMaker boosts machine learning model development with the power of AWS, including scalable computing, storage, networking, and pricing. AWS SageMaker provides managed services, including model management and lifecycle management using a centralized, debugged model.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. Amazon’s AWS Glue is one such tool that allows you to consume data from Apache Kafka and Amazon-managed streaming for Apache Kafka (MSK).
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. It supports various data types and offers advanced features like data sharing and multi-cluster warehouses.
Data is frequently kept in data lakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure. Account A is the data lake account that houses all the ML-ready data obtained through extract, transform, and load (ETL) processes.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
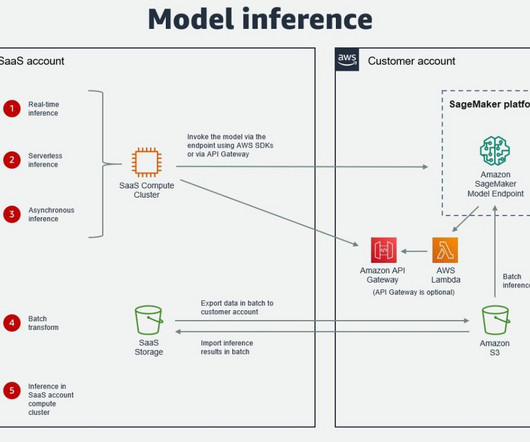
A number of AWS independent software vendor (ISV) partners have already built integrations for users of their software as a service (SaaS) platforms to utilize SageMaker and its various features, including training, deployment, and the model registry. In some cases, an ISV may deploy their software in the customer AWS account.
IAM role – SageMaker requires an AWS Identity and Access Management (IAM) role to be assigned to a SageMaker Studio domain or user profile to manage permissions effectively. Create database connections The built-in SQL browsing and execution capabilities of SageMaker Studio are enhanced by AWS Glue connections. or later image versions.
Decide between cloud-based solutions, such as AWS Redshift or Google BigQuery, and on-premises options, while considering scalability and whether a hybrid approach might be beneficial. Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools.
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificial intelligence (AI) models envisioned. Step-by-step solution Step 1 A client makes a request to the AWS API Gateway endpoint.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Examples include: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). Horizontal scaling increases the quantity of computational resources dedicated to a workload; the equivalent of adding more servers or clusters. Certain CSPs are even equipped to automatically scale compute resources, based on demand.
But, it does not give you all the information about the different functionalities and services, like Data Factory/Linked Services/Analytics Synapse(how to combine and manage databases, ETL), Cognitive Services/Form Recognizer/ (how to do image, text, audio processing), IoT, Deployment, GitHub Actions (running Azure scripts from GitHub).
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. These models may include regression, classification, clustering, and more. ETL Tools: Apache NiFi, Talend, etc. Cloud Platforms: AWS, Azure, Google Cloud, etc. Read more to know.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. Multimodal embeddings help combine unstructured data from various sources in data warehouses and ETL pipelines. The features extracted in the ETL process would then be inputted into the ML models.
Some of the popular cloud-based vendors are: Hevo Data Equalum AWS DMS On the other hand, there are vendors offering on-premise data pipeline solutions and are mostly preferred by organizations dealing with highly sensitive data. Server update locks the entire cluster. User-friendly interface with live dashboards and debugging.
Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. Cloud-agnostic and can run on any Kubernetes cluster. Integration: It can work alongside other workflow orchestration tools (Airflow cluster or AWS SageMaker Pipelines, etc.)
Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. Data Warehousing and ETL Processes What is a data warehouse, and why is it important? Explain the Extract, Transform, Load (ETL) process. What approach would you take?
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. You can use familiar AWS services for model development, generative AI, data processing, and analyticsall within a single, governed environment.
Apache Hadoop Apache Hadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers. is similar to the traditional Extract, Transform, Load (ETL) process. Tooling : Apache Tika , ElasticSearch , Databricks , and AWS Glue for metadata extraction and management.
Modern low-code/no-code ETL tools allow data engineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
For governance, it uses AWS Glue Data Catalog as the central technical catalog and AWS Lake Formation as the permission store for enforcing fine-grained access controls. The Data Engineer has an IAM ETL role and runs the extract, transform, and load (ETL) pipeline using Spark to populate the Lakehouse catalog on RMS.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linked data and also enable a scalable search paradigm that integrates metadata that evolves over time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content