This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
By using dbt Cloud for data transformation, data teams can focus on writing business rules to drive insights from their transaction data to respond effectively to critical, time sensitive events. Solution overview Let’s consider TICKIT , a fictional website where users buy and sell tickets online for sporting events, shows, and concerts.
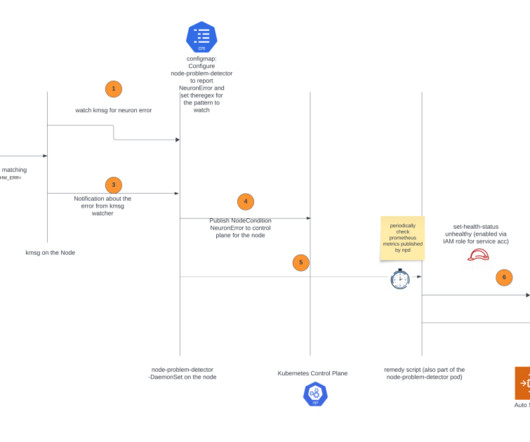
In the post, we introduce the AWS Neuron node problem detector and recovery DaemonSet for AWS Trainium and AWS Inferentia on Amazon Elastic Kubernetes Service (Amazon EKS). Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. install.sh install.sh
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink. Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances.
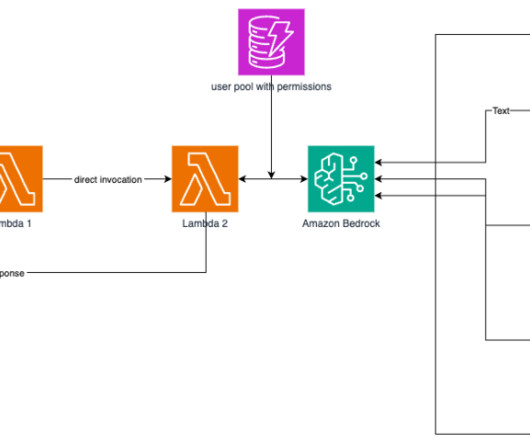
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
Therefore, ML creates challenges for AWS customers who need to ensure privacy and security across distributed entities without compromising patient outcomes. Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. As always, AWS welcomes your feedback.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
The implementation uses Slacks event subscription API to process incoming messages and Slacks Web API to send responses. Key AWS services used include: Amazon Bedrock Including Anthropics Claude 3.5 By keeping all data within the AWS ecosystem, weve eliminated dependencies on third-party AI tools and mitigated associated risks.
To aid in building more sustainable IT estates, IBM has partnered up with Amazon Web Services (AWS) to facilitate sustainable cloud modernization journeys. To read about other key scenarios and entry points of IBM Consulting® Custom Lens for Sustainability, check out the blog post: Sustainable App Modernization Using AWS Cloud.
As described in the AWS Well-Architected Framework , separating workloads across accounts enables your organization to set common guardrails while isolating environments. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts.
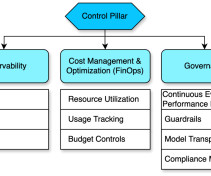
In this post, we share AWS guidance that we have learned and developed as part of real-world projects into practical guides oriented towards the AWS Well-Architected Framework , which is used to build production infrastructure and applications on AWS. We focus on the operational excellence pillar in this post.
This capability allows for the seamless addition of SageMaker HyperPod managed compute to EKS clusters, using automated node and job resiliency features for foundation model (FM) development. FMs are typically trained on large-scale compute clusters with hundreds or thousands of accelerators.
Perhaps you need to discover what’s happening in your business and respond quickly to events. In the rest of this paper, we will explore how Cloud Pak for Integration, deployed on Red Hat OpenShift is the best way to provide integrations deploying in AWS. ROSA is jointly engineered and supported by AWS and Red Hat.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
It can represent a geographical area as a whole or it can represent an event associated with a geographical area. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to. The listing indexer AWS Lambda function continuously polls the queue and processes incoming listing updates.
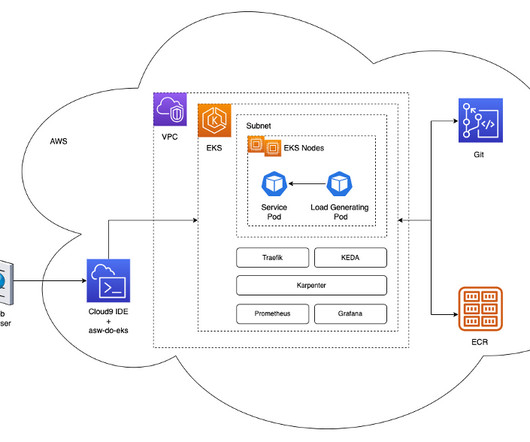
The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. The Kubernetes Event Driven Autoscaler ( KEDA ) is configured to automatically scale the number of service pods, based on the custom metrics available in Prometheus. The service is exposed behind a reverse-proxy using Traefik.
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. The subsequent role of EventBridge was to dispatch events, instigated by the alteration of the buildspec.yml file, leading to running CodeBuild.
Webex by Cisco is a leading provider of cloud-based collaboration solutions, including video meetings, calling, messaging, events, polling, asynchronous video, and customer experience solutions like contact center and purpose-built collaboration devices. Webex works with the world’s leading business and productivity apps—including AWS.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). To address customers’ requirements about data privacy and sovereignty, SnapLogic deploys the data plane within the customer’s VPC on AWS.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed data silos, lack of sufficient data at a single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
It’s straightforward to deploy in your AWS account. Prerequisites You need to have an AWS account and an AWS Identity and Access Management (IAM) role and user with permissions to create and manage the necessary resources and components for this application. Everything you need is provided as open source in our GitHub repo.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. Amazon’s AWS Glue is one such tool that allows you to consume data from Apache Kafka and Amazon-managed streaming for Apache Kafka (MSK).
Virginia) AWS Region. The diagram details a comprehensive AWS Cloud-based setup within a specific Region, using multiple AWS services. The primary interface for the chatbot is a Streamlit application hosted on an Amazon Elastic Container Service (Amazon ECS) cluster, with accessibility managed by an Application Load Balancer.
Make sure you have the following prerequisites: Create an S3 bucket Configure MongoDB Atlas cluster Create a free MongoDB Atlas cluster by following the instructions in Create a Cluster. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Note we have two folders.
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod , an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale. So, for example, a 6.6B
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload.
This process comprises two key components: event data and optical tracking data. Event data collection entails gathering the fundamental building blocks of the game. For the precision needed in shot speed calculations, we must ensure that the ball’s position aligns precisely with the moment of the event.
Geobox enables city departments to do the following: Improved climate adaptation planning – Informed decisions reduce the impact of extreme heat events. SageMaker Processing enables the flexible scaling of compute clusters to accommodate tasks of varying sizes, from processing a single city block to managing planetary-scale workloads.
AWS customer Vericast is a marketing solutions company that makes data-driven decisions to boost marketing ROIs for its clients. Dynamic scaling of feature engineering jobs – A combination of various AWS services is used for this, but most notably SageMaker Processing.
Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes. Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS).
Each environment has a dedicated AWS account with its own cluster and ArgoCD installation. Potential Solutions At the outset, two potential solutions were proposed: ECR Cross Account Replication: AWS’s ECR natively supports replicating images between two accounts. Source: Image by the author. hook: PreSync argocd.argoproj.io/hook-delete-policy:
Prerequisites To implement this solution, complete the following prerequisites: Have AWS Cloud admin access with an AWS Identity and Access Management (IAM) user with permissions required to complete the integration. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Choose Add connection.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others.
Logs Logs include discrete events recorded every time something occurs in the system, such as status or error messages, or transaction details. Autoscaling When traffic spikes, Kubernetes can automatically spin up new clusters to handle the additional workload. Kubernetes logs can be written in both structured and unstructured text.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. Given the highly parallel needs, we chose Lambda to process our images.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Solution overview Amazon Transcribe is the go-to service for speaker diarization in AWS. Make sure the AWS account has a service quota for hosting a SageMaker endpoint for an ml.g5.2xlarge instance.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. The full code can be found on the aws-samples-for-ray GitHub repository. Prepare the source data for the feature store by adding an event time and record ID for each row of data. You can specify resource requirements in actors too.
Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention. We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. Background. That’s an out-of-catalog search experience!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content