This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
AWS Trainium and AWS Inferentia based instances, combined with Amazon Elastic Kubernetes Service (Amazon EKS), provide a performant and low cost framework to run LLMs efficiently in a containerized environment. Solution overview The steps to implement the solution are as follows: Create the EKS cluster.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. The AWS Command Line Interface (AWS CLI) installed on your machine to upload the dataset to Amazon S3. For more information on managing credentials securely, see the AWS Boto3 documentation.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. For sales representatives, it empowers them with deeper insights, enabling more informed recommendations.
Analysts can use this information to provide incentives to buyers and sellers who frequently use the site, to attract new users, and to drive advertising and promotions. To implement this solution, complete the following steps: Set up Zero-ETL integration from the AWS Management Console for Amazon Relational Database Service (Amazon RDS).
ByteDance is a technology company that operates a range of content platforms to inform, educate, entertain, and inspire people across languages, cultures, and geographies. Cross-modal attention mechanisms facilitate information exchange between modalities, and fusion layers combine representations from different modalities.
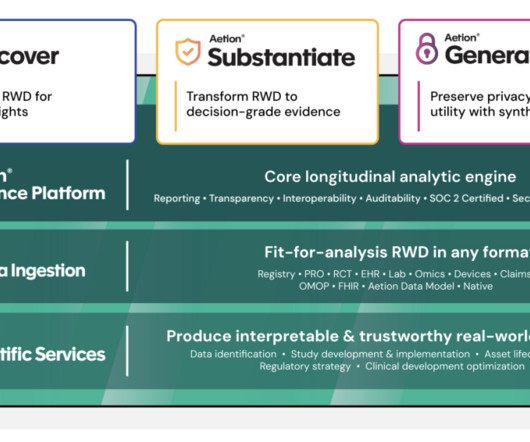
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
By analyzing a wide range of data points, were able to quickly and accurately assess the risk associated with a loan, enabling us to make more informed lending decisions and get our clients the financing they need. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. Complete the following steps: Choose an AWS Region Amazon Q supports (for this post, we use the us-east-1 Region). Choose Create database.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Our e-commerce recommendations engine is driven by ML; the paths that optimize robotic picking routes in our fulfillment centers are driven by ML; and our supply chain, forecasting, and capacity planning are informed by ML. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
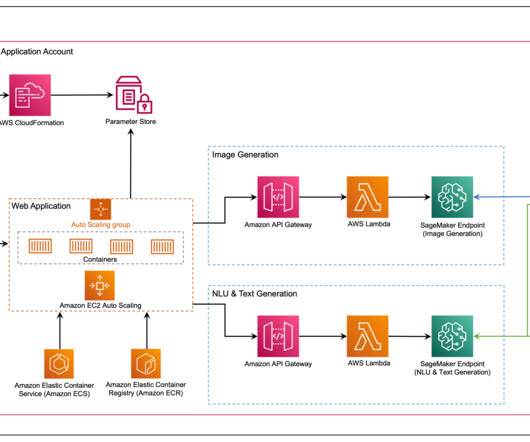
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificial intelligence (AI) technologies by companies and organizations across the globe. Let’s dive in and explore how these organizations are transforming what’s possible with generative AI on AWS.
You can now use DeepSeek-R1 to build, experiment, and responsibly scale your generative AI ideas on AWS. The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. 48xlarge instance in the AWS Region you are deploying.
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
A challenge for DevOps engineers is the additional complexity that comes from using Kubernetes to manage the deployment stage while resorting to other tools (such as the AWS SDK or AWS CloudFormation ) to manage the model building pipeline. kubectl for working with Kubernetes clusters. eksctl for working with EKS clusters.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise.
Despite their wealth of general knowledge, state-of-the-art LLMs only have access to the information they were trained on. This can lead to factual inaccuracies (hallucinations) when the LLM is prompted to generate text based on information they didn’t see during their training.
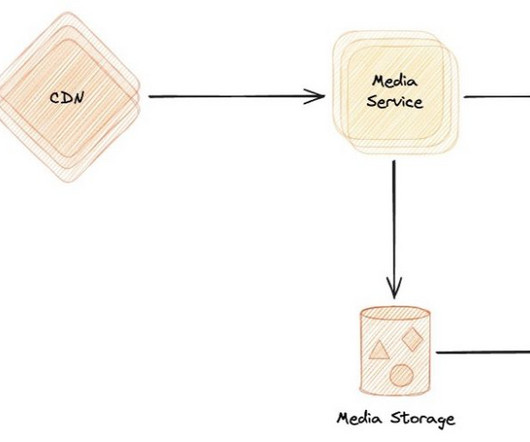
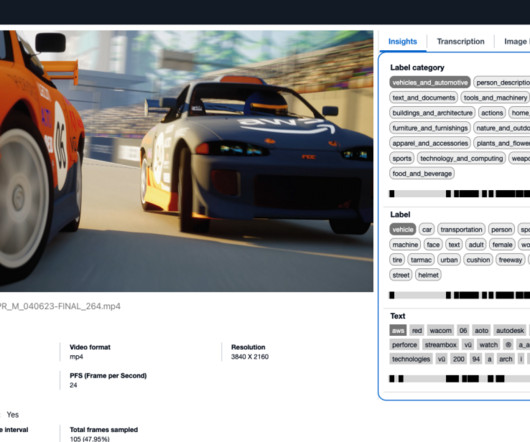
Organizations across media and entertainment, advertising, social media, education, and other sectors require efficient solutions to extract information from videos and apply flexible evaluations based on their policies. This solution, powered by AWS AI and generative AI services, meets these needs.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and data integrity in the secure AWS environment. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Without proper data segregation, companies risk exposing sensitive information between customers or creating complex, hard-to-maintain systems.
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS). The Container Insights dashboard also shows cluster status and alarms.
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
In this journey, we are seeing an increased interest in migrating and deploying MAS on AWS Cloud. The growing need for Maximo migration to AWS Cloud Migrating to cloud helps organizations to drive the operational resiliency and reliability, at the same time keeping software up to date with minimal upgrade effort and infrastructure constraint.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
However, the sharing of raw, non-sanitized sensitive information across different locations poses significant security and privacy risks, especially in regulated industries such as healthcare. Insecure networks lacking access control and encryption can still expose sensitive information to attackers.
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deep learning training. For more information, refer to the Neuron Setup Guide.
For information about how to use JumpStart models programmatically, see Use SageMaker JumpStart Algorithms with Pretrained Models. In April 2023, AWS unveiled Amazon Bedrock , which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs , Anthropic , and Stability AI.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The features are stored in Amazon S3 and encrypted with AWS Key Management Service (AWS KMS) for downstream use.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. The following diagram shows an example.
Whether you’re in Human Resources looking for specific clauses in employee contracts, or a financial analyst sifting through a mountain of invoices to extract payment data, this solution is tailored to empower you to access the information you need with unprecedented speed and accuracy. It consists of one AWS Lambda function.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content