This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock Knowledge Bases has extended its vector store options by enabling support for Amazon OpenSearch Service managed clusters, further strengthening its capabilities as a fully managed Retrieval Augmented Generation (RAG) solution. Why use OpenSearch Service Managed Cluster as a vector store?
Large language models (LLMs) have transformed naturallanguageprocessing (NLP), yet converting conversational queries into structured data analysis remains complex. Amazon Bedrock Knowledge Bases enables direct naturallanguage interactions with structured data sources.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. multilingual large language models (LLMs) are a collection of pre-trained and instruction tuned generative models. An AWS Identity and Access Management (IAM) role to access SageMaker. Meta Llama 3.1 by up to 50%.
Step 1: Cover the Fundamentals You can skip this step if you already know the basics of programming, machine learning, and naturallanguageprocessing. The key here is to focus on concepts like supervised vs. unsupervised learning, regression, classification, clustering, and model evaluation. So, lets get started.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
We walk through the journey Octus took from managing multiple cloud providers and costly GPU instances to implementing a streamlined, cost-effective solution using AWS services including Amazon Bedrock, AWS Fargate , and Amazon OpenSearch Service. Along the way, it also simplified operations as Octus is an AWS shop more generally.
We demonstrate this solution by walking you through a comprehensive step-by-step guide on how to fine-tune YOLOv8 , a real-time object detection model, on Amazon Web Services (AWS) using a custom dataset. The process uses a single ml.g5.2xlarge instance (providing one NVIDIA A10G Tensor Core GPU) with SageMaker for fine-tuning.
Amazon Bedrock Knowledge Bases offers a fully managed Retrieval Augmented Generation (RAG) feature that connects large language models (LLMs) to internal data sources. Users can interact with Amazon Bedrock Knowledge Bases using the AWS Management Console or an AWS SDK client, which sends naturallanguage queries.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. The pipeline leverages several AWS services familiar to Lumis team. Follow him on LinkedIn.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The features are stored in Amazon S3 and encrypted with AWS Key Management Service (AWS KMS) for downstream use.
Although rapid generative AI advancements are revolutionizing organizational naturallanguageprocessing tasks, developers and data scientists face significant challenges customizing these large models. It’s available as a standalone service on the AWS Management Console , or through APIs.
Prerequisites To use the methods presented in this post, you need an AWS account with access to Amazon SageMaker , Amazon Bedrock , and Amazon Simple Storage Service (Amazon S3). Statement: 'AWS is Amazon subsidiary that provides cloud computing services.' Finally, we compare approaches in terms of their performance and latency.
At this stage, the model is not tailored to any specific downstream task but rather builds a general-purpose language representation that can be adapted later using fine-tuning or PEFT methods. AWS provides comprehensive support for implementing various alignment techniques, each offering distinct approaches to achieving this goal.
Key AWS services used include: Amazon Bedrock Including Anthropics Claude 3.5 Sonnet model for naturallanguageprocessing. This means artists can focus on their creative process rather than worrying about precise phrasing or navigating complex menu structures.
Amazon SageMaker HyperPod offers an effective solution for provisioning resilient clusters to run ML workloads and develop state-of-the-art models. Whether youre processing financial statements, KYC documents, or complex reports, we encourage you to evaluate its potential for optimizing your document workflows.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. By integrating this model with Amazon SageMaker AI , you can benefit from the AWS scalable infrastructure while maintaining high-quality language model capabilities.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Solution overview The following diagram provides a high-level overview of AWS services and features through a sample use case.
Unsupervised Learning: Focuses on identifying patterns in unlabeled data, such as clustering customers based on purchasing behavior or reducing data dimensions for visualization. Cloud Computing: Scaling AI Solutions Cloud computing platforms like AWS, Google Cloud, and Microsoft Azure are indispensable for deploying and scaling AI models.
Tensor Processing Units (TPUs) Developed by Google, TPUs are optimized for Machine Learning tasks, providing even greater efficiency than traditional GPUs for specific applications. The demand for advanced hardware continues to grow as organisations seek to develop more sophisticated Generative AI applications.
To take advantage of the power of these language models, we use Amazon Bedrock. The integration with Amazon Bedrock is achieved through the Boto3 Python module, which serves as an interface to the AWS, enabling seamless interaction with Amazon Bedrock and the deployment of the classification model.
Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. Appendix Language models such as Meta Llama are more than 10 GB or even 100 GB in size.
Home Table of Contents Build a Search Engine: Setting Up AWS OpenSearch Introduction What Is AWS OpenSearch? What AWS OpenSearch Is Commonly Used For Key Features of AWS OpenSearch How Does AWS OpenSearch Work? Why Use AWS OpenSearch for Semantic Search? Looking for the source code to this post?
These services support single GPU to HyperPods (cluster of GPUs) for training and include built-in FMOps tools for tracking, debugging, and deployment. Solution overview CrewAI provides a robust framework for developing multi-agent systems that integrate with AWS services, particularly SageMaker AI.
I've created docker containers from scratch and set up AWS Fargate and all the related services to run them and connect them to a public IP address. I have about 3 YoE training PyTorch models on HPC clusters and 1 YoE optimizing PyTorch models, including with custom CUDA kernels.
This post was written by Claudiu Bota, Oleg Yurchenko, and Vladyslav Melnyk of AWS Partner Automat-it. As organizations adopt AI and machine learning (ML), theyre using these technologies to improve processes and enhance products. This approach was inspired by several AWS blog posts that can be found in the references section.
For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
We demonstrate how to build an end-to-end RAG application using Cohere’s language models through Amazon Bedrock and a Weaviate vector database on AWS Marketplace. Cohere Embed comes in two forms, an English language model and a multilingual model, both of which are now available on Amazon Bedrock.
In this post, we describe how we built our cutting-edge productivity agent NinjaLLM, the backbone of MyNinja.ai, using AWS Trainium chips. For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training.
Llama2 by Meta is an example of an LLM offered by AWS. Llama 2 is an auto-regressive language model that uses an optimized transformer architecture and is intended for commercial and research use in English. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
Historically, naturallanguageprocessing (NLP) would be a primary research and development expense. In 2024, however, organizations are using large language models (LLMs), which require relatively little focus on NLP, shifting research and development from modeling to the infrastructure needed to support LLM workflows.
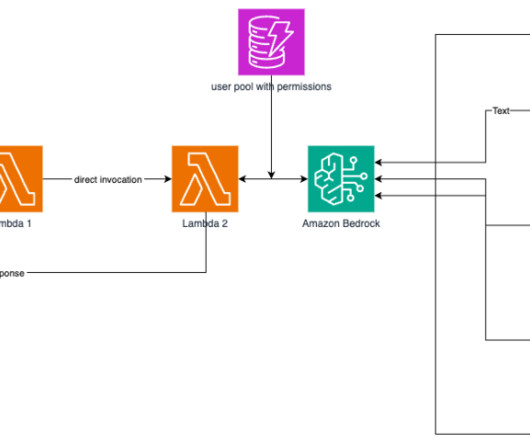
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. Delete the MongoDB Atlas cluster. As always, AWS welcomes feedback.
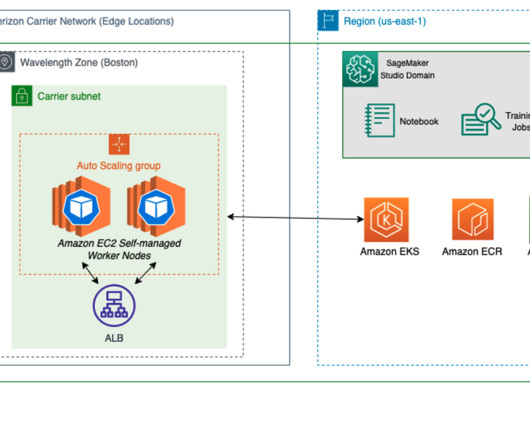
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications. Choose Manage.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. This same interface is also used for provisioning EMR clusters.
Genomic language models are a new and exciting field in the application of large language models to challenges in genomics. In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud.
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
AWS offers tools such as RStudio on SageMaker and Amazon Redshift to help tackle these challenges. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster. I acknowledge that AWS CloudFormation might create IAM resources with custom names.
Embeddings capture the information content in bodies of text, allowing naturallanguageprocessing (NLP) models to work with language in a numeric form. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. You can use it via either the Amazon Bedrock REST API or the AWS SDK.
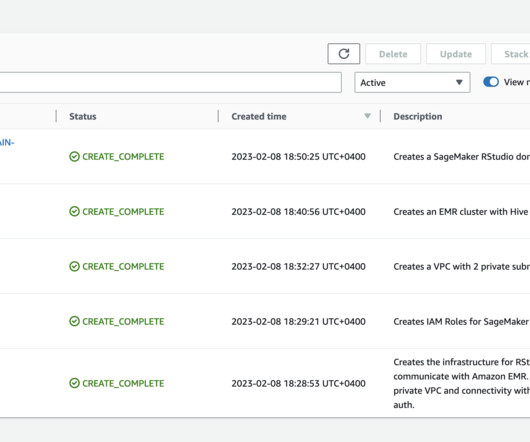
Using RStudio on SageMaker and Amazon EMR together, you can continue to use the RStudio IDE for analysis and development, while using Amazon EMR managed clusters for larger data processing. In this post, we demonstrate how you can connect your RStudio on SageMaker domain with an EMR cluster. Choose Create stack.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content