This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
In 2018, I sat in the audience at AWS re:Invent as Andy Jassy announced AWS DeepRacer —a fully autonomous 1/18th scale race car driven by reinforcement learning. But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML.
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. Third, we’ll explore the robust infrastructure services from AWS powering AI innovation, featuring Amazon SageMaker , AWS Trainium , and AWS Inferentia under AI/ML, as well as Compute topics.
8B and 70B inference support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Trainium and Inferentia, enabled by the AWS Neuron software development kit (SDK), offer high performance and lower the cost of deploying Meta Llama 3.1 An AWS Identity and Access Management (IAM) role to access SageMaker.
Syngenta and AWS collaborated to develop Cropwise AI , an innovative solution powered by Amazon Bedrock Agents , to accelerate their sales reps’ ability to place Syngenta seed products with growers across North America. The collaboration between Syngenta and AWS showcases the transformative power of LLMs and AI agents.
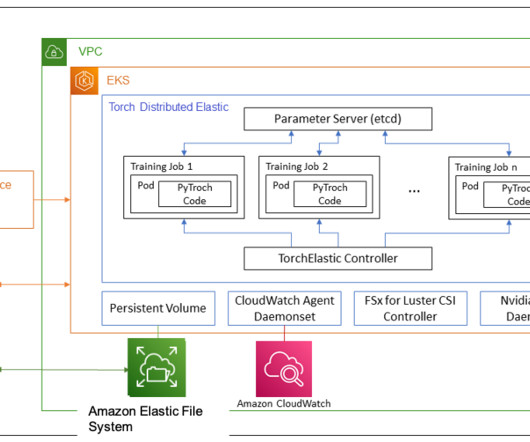
These recipes include a training stack validated by Amazon Web Services (AWS) , which removes the tedious work of experimenting with different model configurations, minimizing the time it takes for iterative evaluation and testing. The launcher will interface with your cluster with Slurm or Kubernetes native constructs.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise.
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deep learning training. What you get is an ML development environment that is consistent and portable.
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. You can execute each step in the training pipeline by initiating the process through the SageMaker control plane using APIs, AWS Command Line Interface (AWS CLI), or the SageMaker ModelTrainer SDK.
At AWS, we have played a key role in democratizing ML and making it accessible to anyone who wants to use it, including more than 100,000 customers of all sizes and industries. AWS has the broadest and deepest portfolio of AI and ML services at all three layers of the stack.
A challenge for DevOps engineers is the additional complexity that comes from using Kubernetes to manage the deployment stage while resorting to other tools (such as the AWS SDK or AWS CloudFormation ) to manage the model building pipeline. kubectl for working with Kubernetes clusters. eksctl for working with EKS clusters.
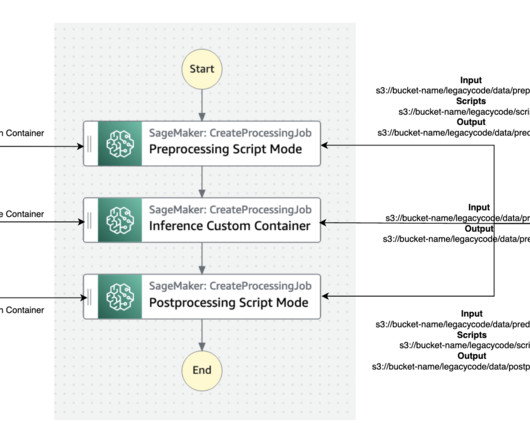
Tens of thousands of AWS customers use AWS machine learning (ML) services to accelerate their ML development with fully managed infrastructure and tools. The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK.
You can now use DeepSeek-R1 to build, experiment, and responsibly scale your generative AI ideas on AWS. The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. 48xlarge instance in the AWS Region you are deploying.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificial intelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
You can also access JumpStart models using the SageMaker Python SDK. In April 2023, AWS unveiled Amazon Bedrock , which provides a way to build generative AI-powered apps via pre-trained models from startups including AI21 Labs , Anthropic , and Stability AI. Clone and set up the AWS CDK application.
Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. run_opensearch.sh Running OpenSearch Locally A script to start OpenSearch using Docker for local testing before deploying to AWS. Implement and analyze search results using Python scripts.
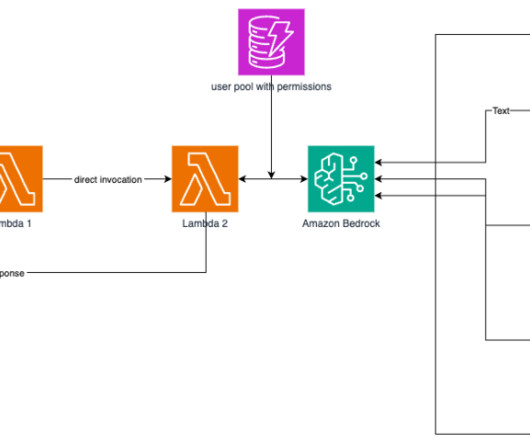
Because Amazon Bedrock is serverless, you don’t have to manage infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with. AWS Prototyping developed an AWS Cloud Development Kit (AWS CDK) stack for deployment following AWS best practices.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
Key AWS services used include: Amazon Bedrock Including Anthropics Claude 3.5 This could be, for example, Keep all your replies as short as possible or If I ask for code its always Python. For example, the query Remember to always use Python as a programming language will trigger the execution of this tool.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. The following diagram shows an example.
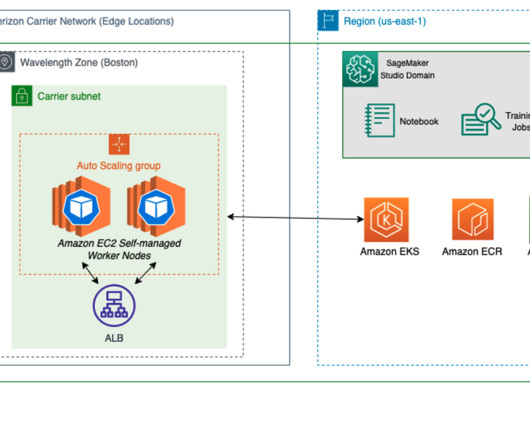
To reduce the barrier to entry of ML at the edge, we wanted to demonstrate an example of deploying a pre-trained model from Amazon SageMaker to AWS Wavelength , all in less than 100 lines of code. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications.
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code.
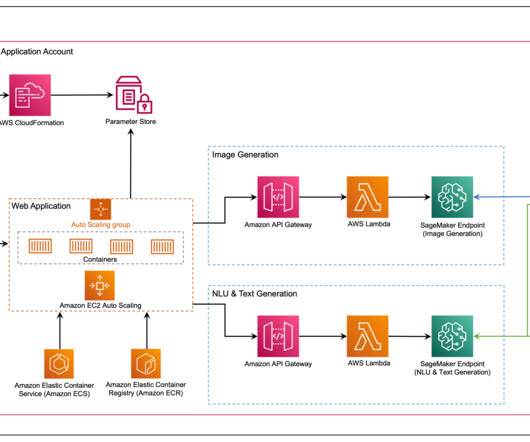
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies and AWS. Solution overview The following diagram provides a high-level overview of AWS services and features through a sample use case. The response only cites sources that are relevant to the query.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. SageMaker Studio runs inside an AWS managed virtual private cloud ( VPC ), with network access for SageMaker Studio domains, in this setup configured as VPC-only.
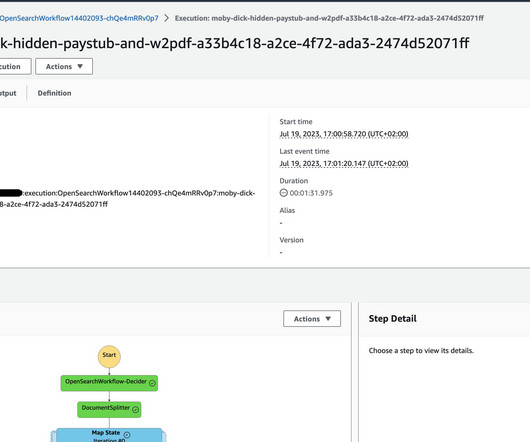
We’ll cover how technologies such as Amazon Textract, AWS Lambda , Amazon Simple Storage Service (Amazon S3), and Amazon OpenSearch Service can be integrated into a workflow that seamlessly processes documents. The main concepts used are the AWS Cloud Development Kit (CDK) constructs, the actual CDK stacks and AWS Step Functions.
Home Table of Contents Introduction to GitHub Actions for Python Projects Introduction What Is CICD? For Python projects, CI/CD pipelines ensure that your code is consistently integrated and delivered with high quality and reliability. Git is the most commonly used VCS for Python projects, enabling collaboration and version tracking.
With Amazon SageMaker , now you can run a SageMaker training job simply by annotating your Python code with @remote decorator. The SageMaker Python SDK automatically translates your existing workspace environment, and any associated data processing code and datasets, into an SageMaker training job that runs on the training platform.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. For more information, refer to Common techniques to detect PHI and PII data using AWS Services.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. In the past few years, numerous customers have been using the AWS Cloud for LLM training. We recommend working with your AWS account team or contacting AWS Sales to determine the appropriate Region for your LLM workload.
Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes. Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS).
We are excited to announce a new version of the Amazon SageMaker Operators for Kubernetes using the AWS Controllers for Kubernetes (ACK). ACK is a framework for building Kubernetes custom controllers, where each controller communicates with an AWS service API. They are also supported by AWS CloudFormation. Release v1.2.9
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
A grid system is established with a 48-meter grid size using Mapbox’s Supermercado Python library at zoom level 19, enabling precise spatial analysis. The geospatial notebook kernel is pre-installed with commonly used geospatial libraries, enabling direct visualization and processing of geospatial data within the Python notebook environment.
We cover two approaches: using the Amazon SageMaker Studio UI for a no-code solution, and using the SageMaker Python SDK. Prerequisites To try out this solution using SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all of your AWS resources. You can access the Meta Llama 3.2
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. Solution overview Amazon Transcribe is the go-to service for speaker diarization in AWS. PyAnnote is an open source toolkit written in Python for speaker diarization.
In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. A desired cluster can simply be configured using the eks.conf file and launched by running the eks-create.sh to launch the cluster.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content