This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
We recommend referring to the Submit a model distillation job in Amazon Bedrock in the official AWS documentation for the most up-to-date and comprehensive information. Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities.
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe. Check out the Cohere on AWS GitHub repo.
Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account. model customization is available in the US West (Oregon) AWS Region. The required training dataset (and optional validation dataset) prepared and stored in Amazon Simple Storage Service (Amazon S3).
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
For more information on Mixtral-8x7B Instruct on AWS, refer to Mixtral-8x7B is now available in Amazon SageMaker JumpStart. Before you get started with the solution, create an AWS account. This identity is called the AWS account root user. For more detailed steps to prepare the data, refer to the GitHub repo.
The built-in project templates provided by Amazon SageMaker include integration with some of third-party tools, such as Jenkins for orchestration and GitHub for source control, and several utilize AWS native CI/CD tools such as AWS CodeCommit , AWS CodePipeline , and AWS CodeBuild. all implemented via CloudFormation.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Store your Snowflake account credentials in AWS Secrets Manager. Ingest the data in a table in your Snowflake account.
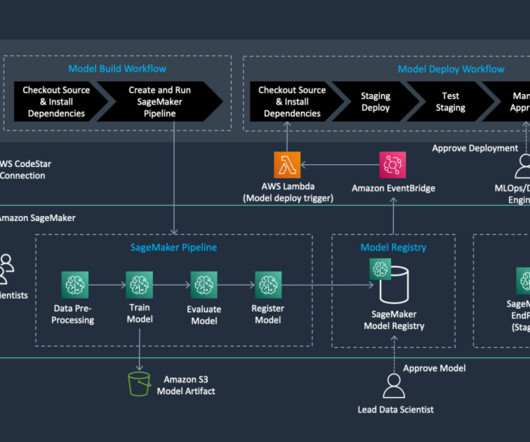
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. The full code can be found on the aws-samples-for-ray GitHub repository. About the Author Raju Rangan is a Senior Solutions Architect at Amazon Web Services (AWS).
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
Solution overview Scalable Capital’s ML infrastructure consists of two AWS accounts: one as an environment for the development stage and the other one for the production stage. The following diagram shows the workflow for our email classifier project, but can also be generalized to other datascience projects. Use Version 2.x
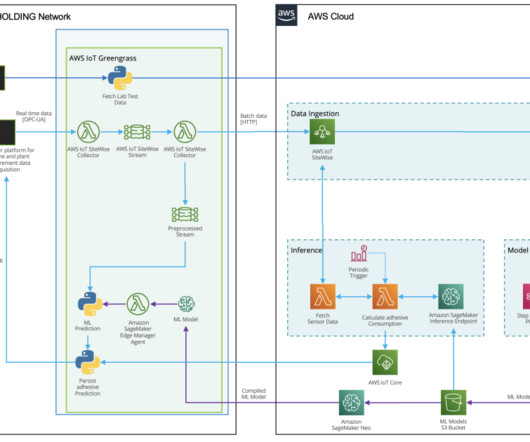
Input data is streamed from the plant via OPC-UA through SiteWise Edge Gateway in AWS IoT Greengrass. Model training and optimization with SageMaker automatic model tuning Prior to the model training, a set of datapreparation activities are performed. Samples are sent to a laboratory for quality tests.
Amazon OpenSearch OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. as our example data to perform retrieval augmented question answering on. Here, we walk through the steps for indexing to an OpenSearch service deployed on AWS.
Additional model training benefits can include lower training costs with Managed Spot Training, distributed training libraries to split models and training datasets across AWS GPU instances, and more. input_ids return batch #apply the datapreparation function to all of our fine-tuning dataset samples using dataset's.map method.
With SageMaker, data scientists and developers can quickly build and train ML models, and then deploy them into a production-ready hosted environment. In this post, we demonstrate how to use the managed ML platform to provide a notebook experience environment and perform federated learning across AWS accounts, using SageMaker training jobs.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Therefore, a common mistake when interviewing applicants is to focus on the minutia of a particular platform (AWS, GCP, Databricks, MLflow, etc.). Many people use the term “pipeline” in MLOps which can be confusing since pipeline is computerscience term that refers to a linear sequence with a single input/output.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as datapreparation, model training, tuning and validation. About the Authors Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He enjoys playing Table Tennis and is a sports fan.
Natural Language Processing (NLP) This is a field of computerscience that deals with the interaction between computers and human language. Computer Vision This is a field of computerscience that deals with the extraction of information from images and videos. Why is DataPreparation Crucial in AI Projects?
RAG applications on AWS RAG models have proven useful for grounding language generation in external knowledge sources. This configuration might need to change depending on the RAG solution you are working with and the amount of data you will have on the file system itself. For IAM role , choose Create a new role.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about datascience and Bayesian statistics. in computerscience from the University of California, Berkeley; and Bachelors and Masters degrees fromMIT.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content