This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
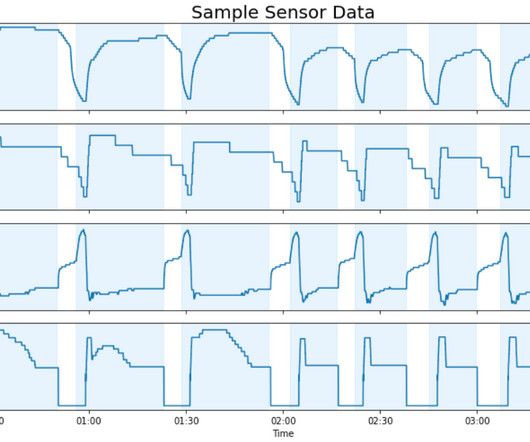
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
Starting with the AWS Neuron 2.18 release , you can now launch Neuron DLAMIs (AWSDeepLearning AMIs) and Neuron DLCs (AWSDeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS Systems Manager Parameter Store support Neuron 2.18
AWS Lambda AWS Lambda is a compute service that runs code in response to triggers such as changes in data, changes in application state, or user actions. Prerequisites If youre new to AWS, you first need to create and set up an AWS account. We use Amazon S3 to store sample documents that are used in this solution.
In this post, we show how the Carrier and AWS teams applied ML to predict faults across large fleets of equipment using a single model. We first highlight how we use AWS Glue for highly parallel data processing. AWS Glue allowed us to easily run parallel data preprocessing and feature extraction. Additionally, 10.4%
Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart. Virginia) and US West (Oregon) AWS Regions, and most recently announced general availability in the US East (Ohio) Region.
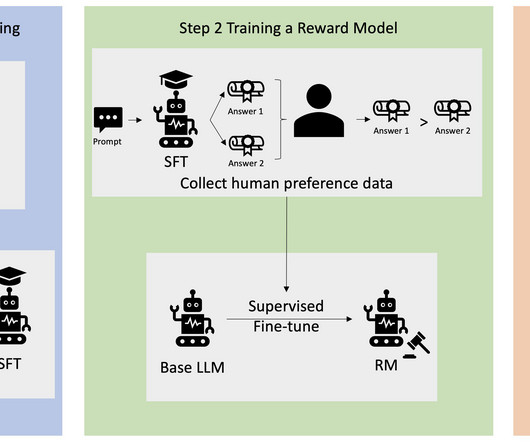
In this contributed article, Stefano Soatto, Professor of ComputerScience at the University of California, Los Angeles and a Vice President at Amazon Web Services, discusses generative AI models and how they are designed and trained to hallucinate, so hallucinations are a common product of any generative model.
See Amazon SageMaker geospatial capabilities to learn more. About the Author Xiong Zhou is a Senior Applied Scientist at AWS. He leads the science team for Amazon SageMaker geospatial capabilities. Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. He is an ACM Fellow and IEEE Fellow.
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container , an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS).
To address customer needs for high performance and scalability in deeplearning, generative AI, and HPC workloads, we are happy to announce the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P5e instances, powered by NVIDIA H200 Tensor Core GPUs. Karthik Venna is a Principal Product Manager at AWS.
In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. We have developed an FL framework on AWS that enables analyzing distributed and sensitive health data in a privacy-preserving manner. In this post, we showed how you can deploy the open-source FedML framework on AWS. Conclusion.
To mitigate these challenges, we propose a federated learning (FL) framework, based on open-source FedML on AWS, which enables analyzing sensitive HCLS data. It involves training a global machine learning (ML) model from distributed health data held locally at different sites. Request a VPC peering connection.
Some examples include extracting players and positions in an NFL game summary, products mentioned in an AWS keynote transcript, or key names from an article on a favorite tech company. We extract the default generic entities through the AWS SDK for Python (Boto3) as follows: import pandas as pd comprehend_client = boto3.client("comprehend")
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. Machine & DeepLearning Machine learning is the fundamental data science skillset, and deeplearning is the foundation for NLP.
Professional certificate for computerscience for AI by HARVARD UNIVERSITY Professional certificate for computerscience for AI is a 5-month AI course that is inclusive of self-paced videos for participants; who are beginners or possess intermediate-level understanding of artificial intelligence.
Falcon 2 11B is supported by the SageMaker TGI DeepLearning Container (DLC) which is powered by Text Generation Inference (TGI) , an open source, purpose-built solution for deploying and serving LLMs that enables high-performance text generation using tensor parallelism and dynamic batching. Avan Bala is a Solutions Architect at AWS.
The workflow steps are as follows: Set up a SageMaker notebook and an AWS Identity and Access Management (IAM) role with appropriate permissions to allow SageMaker to access Amazon Elastic Container Registry (Amazon ECR), Secrets Manager, and other services within your AWS account. AWS Region Link us-east-1 (N.
In terms of security, both the input and output are secured using TLS using AWS Sigv4 Auth. In this post, we showcase two container options to create a SageMaker endpoint with response streaming: using an AWS Large Model Inference (LMI) and Hugging Face Text Generation Inference (TGI) container.
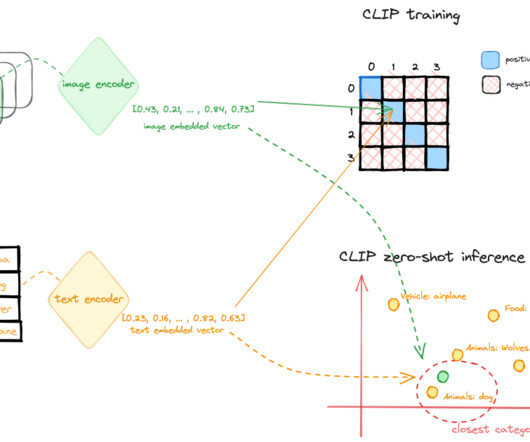
Multimodal is a type of deeplearning using multiple modalities of data, such as text, audio, or images. This feature is available in all AWS Regions where SageMaker is available. To learn more about deploying models on SageMaker, see Amazon SageMaker Model Deployment. gpu-py311-cu121-ubuntu20.04-sagemaker.
Libraries such as DeepSpeed (an open-source deeplearning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training. Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch.
MLSL’s high caliber talent, culture, and focus on aiding our realization of measurable and compelling results from machine learning investments enabled us to reduce suicide risk, improve career transition, and speed up important connections for our service members, veterans, and their families.” Applied AI Specialist Architect at AWS.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computerscience, algorithms, and so on. They’re looking for people who know all related skills, and have studied computerscience and software engineering.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Prerequisites To continue with the examples in this post, you need to create the required AWS resources.
For more information, refer to the AWS Sagemaker Developer Guide’s documentation on “ Clean Up ”. About the Authors Weifeng Chen is an Applied Scientist in the AWS Human-in-the-loop science team. Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud. at a minimum).
Although it provides various entry points like the SageMaker Python SDK, AWS SDKs, the SageMaker console, and Amazon SageMaker Studio notebooks to simplify the process of training and deploying ML models at scale, customers are still looking for better ways to deploy their models for playground testing and to optimize production deployments.
AWS AI services, such as Amazon Personalize and Amazon Bedrock, can help recommend and deliver products, content, and compelling marketing messages personalized to your users. For more information on working with generative AI on AWS, see to Announcing New Tools for Building with Generative AI on AWS. Jingwen Hu is a Sr.
This post provides an overview of a custom solution developed by the AWS Generative AI Innovation Center (GenAIIC) for Deltek , a globally recognized standard for project-based businesses in both government contracting and professional services. For technical support or to contact AWS generative AI specialists, visit the GenAIIC webpage.
Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
Alex Williams is an applied scientist in the human-in-the-loop science team at AWS AI where he conducts interactive systems research at the intersection of human-computer interaction (HCI) and machine learning. Patrick Haffner is a Principal Applied Scientist with the AWS Sagemaker Ground Truth team.
The Amazon Personalize Search Ranking plugin within OpenSearch Service allows you to improve the end-user engagement and conversion from your website and app search by taking advantage of the deeplearning capabilities offered by Amazon Personalize. Technical Product Manager working with AWS AI/ML on the Amazon Personalize team.
This post is co-written with Travis Bronson, and Brian L Wilkerson from Duke Energy Machine learning (ML) is transforming every industry, process, and business, but the path to success is not always straightforward. We evaluated the performance of two AWS services Amazon Rekognition and Amazon Lookout for Vision.
AWS , GCP , Azure , DigitalOcean , etc.) Course information: 81 total classes • 109+ hours of on-demand code walkthrough videos • Last updated: October 2023 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning.
AWS , GCP , Azure , DigitalOcean , etc.) Course information: 81 total classes • 109+ hours of on-demand code walkthrough videos • Last updated: October 2023 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning.
Amazon Personalize is excited to announce the new Next Best Action ( aws-next-best-action ) recipe to help you determine the best actions to suggest to your individual users that will enable you to increase brand loyalty and conversion. Technical Product Manager working with AWS AI/ML on Amazon Personalize.
We use the Stability AI SDK to deploy this model from SageMaker JumpStart after subscribing to this model on the AWS marketplace. About the Authors Yanwei Cui , PhD, is a Senior Machine Learning Specialist Solutions Architect at AWS. Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia.
DeepSpeed is a library that helps train very large deeplearning models faster and more efficiently. Reference LLaVA Visual Instruction Tuning (pdf) About the Authors Dr. Changsha Ma is an AI/ML Specialist at AWS. Jun Shi is a Senior Solutions Architect at Amazon Web Services (AWS).
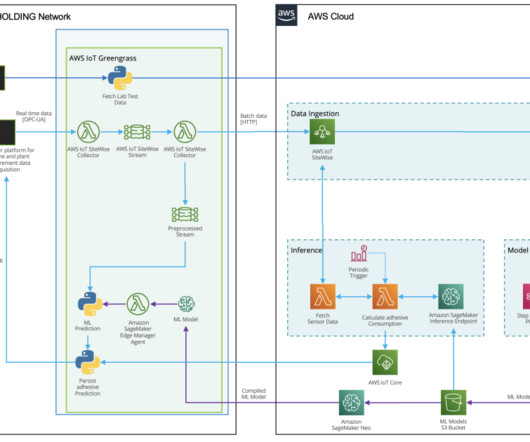
Input data is streamed from the plant via OPC-UA through SiteWise Edge Gateway in AWS IoT Greengrass. During the prototyping phase, HAYAT HOLDING deployed models to SageMaker hosting services and got endpoints that are fully managed by AWS. Take advantage of industry-specific innovations and solutions using AWS for Industrial.
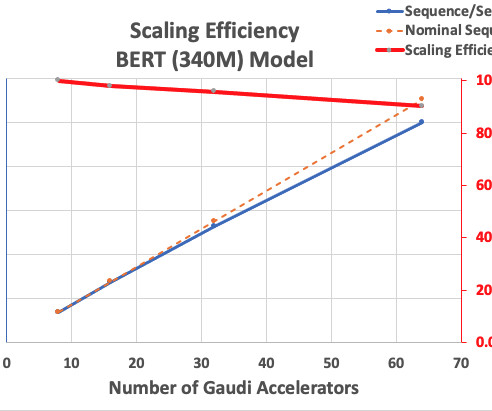
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod , an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale.
SageMaker JumpStart SageMaker JumpStart serves as a model hub encapsulating a broad array of deeplearning models for text, vision, audio, and embedding use cases. With over 500 models, its model hub comprises both public and proprietary models from AWS’s partners such as AI21, Stability AI, Cohere, and LightOn.
Furthermore, you don’t need to understand container lifecycle management and can simply run your workloads across different compute contexts (such as a local IDE, Studio, or training jobs) with minimal configuration overheads. He has an MS in ComputerScience and his areas of interest are Computer Security, Distributed Systems and AI/ML.
Speech-to-text technology relies on a combination of linguistics, computerscience, and artificial intelligence to function. Modern speech-to-text systems often use machine learning algorithms (particularly deeplearning neural networks) to improve their accuracy and adapt to different accents, languages, and speech patterns. Try
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered.
Not only is data larger, but models—deeplearning models in particular—are much larger than before. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch. They are often built by data scientists who are not software engineers or computerscience majors by training.
We introduce an AWS Lambda function as a proxy in front of the SageMaker endpoint to offer various types of data transformation. After provisioning this architecture and deploying our model using the AWS Cloud Development Kit (AWS CDK), we evaluated the latency characteristics of our model with different SageMaker instance types.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content