This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Google Releases a tool for Automated ExploratoryDataAnalysis Exploring data is one of the first activities a data scientist performs after getting access to the data. This command-line tool helps to determine the properties and quality of the data as well the predictive power.
As part of the 2023 Data Science Conference (DSCO 23), AWS partnered with the Data Institute at the University of San Francisco (USF) to conduct a datathon. Participants, both high school and undergraduate students, competed on a data science project that focused on air quality and sustainability.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
Build a Stocks Price Prediction App powered by Snowflake, AWS, Python and Streamlit — Part 2 of 3 A comprehensive guide to develop machine learning applications from start to finish. Introduction Welcome Back, Let's continue with our Data Science journey to create the Stock Price Prediction web application.
Be sure to check out his talk, “ Build Classification and Regression Models with Spark on AWS ,” there! In the unceasingly dynamic arena of data science, discerning and applying the right instruments can significantly shape the outcomes of your machine learning initiatives. A cordial greeting to all data science enthusiasts!
How I cleared AWS Machine Learning Specialty with three weeks of preparation (I will burst some myths of the online exam) How I prepared for the test, my emotional journey during preparation, and my actual exam experience Certified AWS ML Specialty Badge source Introduction:- I recently gave and cleared AWS ML certification on 29th Dec 2022.
Before the launch of this feature, administrators were required to set up the initial storage integration to connect with Snowflake to create features for ML in Data Wrangler. For more details on the administration setup, refer to Import data from Snowflake. An AWS account with admin access.
These communities will help you to be updated in the field, because there are some experienced data scientists posting the stuff, or you can talk with them so they will also guide you in your journey. DataAnalysis After learning math now, you are able to talk with your data.
Blind 75 LeetCode Questions - LeetCode Discuss Data Manipulation and Analysis Proficiency in working with data is crucial. This includes skills in data cleaning, preprocessing, transformation, and exploratorydataanalysis (EDA).
Top 50+ Interview Questions for Data Analysts Technical Questions SQL Queries What is SQL, and why is it necessary for dataanalysis? SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. How would you segment customers based on their purchasing behaviour?
We explain the metrics and show techniques to deal with data to obtain better model performance. Prerequisites If you would like to implement all or some of the tasks described in this post, you need an AWS account with access to SageMaker Canvas. Indrajit is an AWS Enterprise Sr. Solutions Architect.
& AWS Machine Learning Solutions Lab (MLSL) Machine learning (ML) is being used across a wide range of industries to extract actionable insights from data to streamline processes and improve revenue generation. Huzefa Rangwala is a Senior Applied Science Manager at AIRE, AWS. This is a joint post by NXP SEMICONDUCTORS N.V.
R for Data Science Although not as broadly adopted as Python, R holds a strong position in Data Science, particularly for statistical analysis, advanced visualisation, and specialised techniques. Data Science Platforms Platforms like Databricks and Apache Zeppelin offer robust support for multi-language workflows.
At the core of Data Science lies the art of transforming raw data into actionable information that can guide strategic decisions. Role of Data Scientists Data Scientists are the architects of dataanalysis. They clean and preprocess the data to remove inconsistencies and ensure its quality.
For example, when it comes to deploying projects on cloud platforms, different companies may utilize different providers like AWS, GCP, or Azure. For instance, feature engineering and exploratorydataanalysis (EDA) often require the use of visualization libraries like Matplotlib and Seaborn.
Scikit-learn: A simple and efficient tool for data mining and dataanalysis, particularly for building and evaluating machine learning models. Data Normalization and Standardization: Scaling numerical data to a standard range to ensure fairness in model training.
Kaggle datasets) and use Python’s Pandas library to perform data cleaning, data wrangling, and exploratorydataanalysis (EDA). Extract valuable insights and patterns from the dataset using data visualization libraries like Matplotlib or Seaborn.
ExploratoryDataAnalysis This is one of the fun parts because we get to look into and analyze what’s inside the data that we have collected and cleaned. This is the highest accuracy achieved by fine-tuning the model on AWS SageMaker with the training data of 30,000 sentences between sentences 40,000 and 70,000.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. I’ll show you best practices for using Jupyter Notebooks for exploratorydataanalysis. When data science was sexy , notebooks weren’t a thing yet.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
Furthermore, the democratization of AI and ML through AWS and AWS Partner solutions is accelerating its adoption across all industries. For example, a health-tech company may be looking to improve patient care by predicting the probability that an elderly patient may become hospitalized by analyzing both clinical and non-clinical data.
Solution overview Scalable Capital’s ML infrastructure consists of two AWS accounts: one as an environment for the development stage and the other one for the production stage. The following diagram shows the workflow for our email classifier project, but can also be generalized to other data science projects. Use Version 2.x
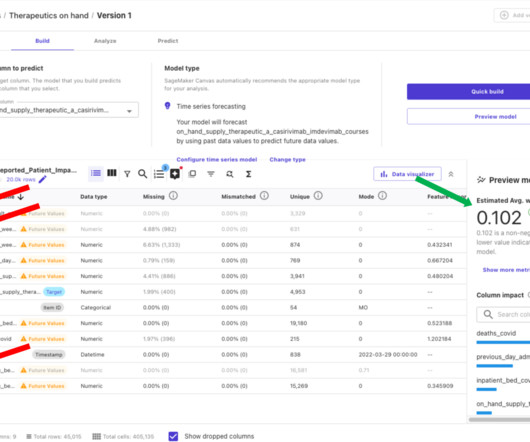
Exploratorydataanalysis After you import your data, Canvas allows you to explore and analyze it, before building predictive models. You can preview your imported data and visualize the distribution of different features. This information can be used to refine your input data and drive more accurate models.
In the following sections, we demonstrate how to perform exploratorydataanalysis and preparation, build the ML forecasting model, and generate predictions using Canvas. Solutions Architect at AWS supporting the US Public Sector. The dataset is updated periodically. About the authors Henrik Balle is a Sr.
GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do dataanalysis BI report generation/dataanalysis In BI/dataanalysis world, people usually need to query data (small/large).
Simply put, focusing solely on dataanalysis, coding or modeling will no longer cuts it for most corporate jobs. My personal opinion: its more important than ever to be an end-to-end data scientist. You have to understand data, how to extract value from them and how to monitor model performances. What to do then?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content