This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
The post AWS ECS- Amazon’s Container Tool appeared first on Analytics Vidhya. But what exactly are these containers? In the field of information technology, a container is like a typical container you could encounter in daily life. It only holds […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction AWS S3 is one of the object storage services offered by Amazon Web Services or AWS. The post Using AWS S3 with Python boto3 appeared first on Analytics Vidhya.
Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems. Traditionally, ETL processes are […].
Organizations are collecting data at an alarming pace to analyze and derive insights for business enhancements. The abundant requirement for data collection made cloud data storage an unavoidable option concerning the […]. The post AWS Storage: Cost Optimization Principles appeared first on Analytics Vidhya.
Introduction to AWSAWS, or Amazon Web Services, is one of the world’s most widely used cloud service providers. AWS has many clusters of data centers in multiple countries across the globe. The post AWS Lambda Tutorial: Creating Your First Lambda Function appeared first on Analytics Vidhya.
The post Using AWS Athena and QuickSight for Data Analysis appeared first on Analytics Vidhya. Also, have you ever tried doing this with Athena and QuickSight? This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. Amazon’s perfect combination of […].
The post AWS Elastic BeanStalk Processing and its Components appeared first on Analytics Vidhya. Introduction If you are a beginner or have little time, configuring the environment for your application may be too complicated and time-consuming. You need to consider monitoring, logs, security groups, VMs, backups, etc.
The post Elastic Load Balancer in AWS and its Benefits appeared first on Analytics Vidhya. The most important aspect of cloud computing is the on-demand application delivery paradigm from the cloud customer’s perspective. As a result, cloud services […].
Businesses of all sizes are switching to the cloud to manage risks, improve data security, streamline processes and decrease costs, or other reasons. The post AWS VPC: Creating Your own Virtual Private Network on Cloud appeared first on Analytics Vidhya. Many services are available from top cloud […].
While not all of us are tech enthusiasts, we all have a fair knowledge of how Data Science works in our day-to-day lives. All of this is based on Data Science which is […]. The post Step-by-Step Roadmap to Become a DataEngineer in 2023 appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
The post Introduction to Amazon API Gateway using AWS Lambda appeared first on Analytics Vidhya. If you want to make noodles, you just take the ingredients out of the cupboard, fire up the stove, and make it yourself. This […].
Introduction Amazon Athena is an interactive query service based on open-source Apache Presto that allows you to analyze data stored in Amazon S3 using ANSI SQL directly. The post How is AWS Athena Different from other Databases appeared first on Analytics Vidhya.
Source: [link] Introduction Nowadays, a lot of data is being generated and consumed, resulting in a huge amount of internet traffic exponentially across the globe. The post AWS Route 53 – The Efficient DNS Solution appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview In this article, we will learn how to run/deploy containerized. The post Deploying Machine learning Application on AWS Fargate appeared first on Analytics Vidhya.
It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it […]. The post Basic Concept and Backend of AWS Elasticsearch appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction Data Lake architecture for different use cases – Elegant. The post A Guide to Build your Data Lake in AWS appeared first on Analytics Vidhya.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. Principal also used the AWS open source repository Lex Web UI to build a frontend chat interface with Principal branding.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Today, as companies have finally come to understand the value that data science can bring, more and more emphasis is being placed on the implementation of data science in production systems.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Solution overview The following diagram illustrates the ML platform reference architecture using various AWS services. The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , Amazon SageMaker , AWS DevOps services, and a data lake.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction Amazon Web Services (AWS) is a cloud computing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machine learning, etc.
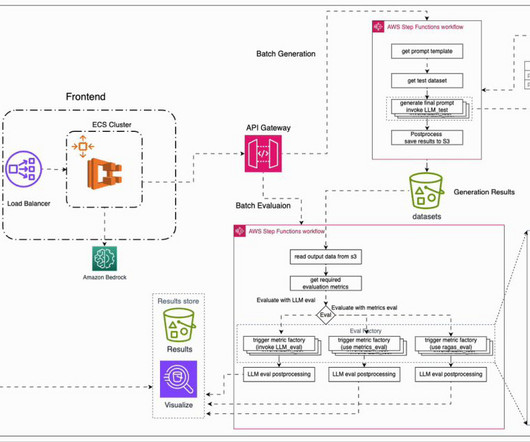
In this post, to address the aforementioned challenges, we introduce an automated evaluation framework that is deployable on AWS. We then present a typical evaluation workflow, followed by our AWS-based solution that facilitates this process. The UI service can be run locally in a Docker container or deployed to AWS Fargate.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Click here to open the AWS console and follow along. The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion.
Introduction: Gone are the days when enterprises set up their own in-house server and spending a gigantic amount of budget on storage infrastructure & The post Deployment of ML models in Cloud – AWS SageMaker?(in-built in-built algorithms) appeared first on Analytics Vidhya.
phData, a leading AI and data services company, announced today that it has achieved the AWS Generative AI Competency as an AWS Service Delivery partner. Achieving the AWS Generative AI Competency strengthens our commitment to helping our clients adopt AI.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Hear also from Adidas, GlobalFoundries, and University of California, Irvine.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
Introduction S3 is Amazon Web Services cloud-based object storage service (AWS). It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner.
Introduction Amazon Athena is an interactive query tool supplied by Amazon Web Services (AWS) that allows you to use conventional SQL queries to evaluate data stored in Amazon S3. Athena is a serverless service. Thus there are no servers to operate, and you pay for the queries you perform.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
Introduction Amazon Redshift is a fully managed, petabyte-scale data warehousing Amazon Web Services (AWS). It allows users to easily set up, operate, and scale a data warehouse in the cloud.
Naveen Edapurath Vijayan is a Sr Manager of DataEngineering at AWS, specializing in data analytics and large-scale data systems. Artificial intelligence (AI) is transforming the way businesses analyze data, shifting from traditional business intelligence (BI) dashboards to real-time, automated
Using an Amazon Q Business custom data source connector , you can gain insights into your organizations third party applications with the integration of generative AI and natural language processing. Alation is a data intelligence company serving more than 600 global enterprises, including 40% of the Fortune 100.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
Expand to generative AI use cases with your existing AWS and Tecton architecture After you’ve developed ML features using the Tecton and AWS architecture, you can extend your ML work to generative AI use cases. You can also find Tecton at AWS re:Invent. This process is shown in the following diagram.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content