This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and data science teams, and maintaining compliance with relevant financial regulations.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
The Hadoop environment was hosted on Amazon Elastic Compute Cloud (Amazon EC2) servers, managed in-house by Rockets technology team, while the data science experience infrastructure was hosted on premises. Communication between the two systems was established through Kerberized Apache Livy (HTTPS) connections over AWS PrivateLink.
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
In this post, we describe the end-to-end workforce management system that begins with location-specific demand forecast, followed by courier workforce planning and shift assignment using Amazon Forecast and AWS Step Functions. AWS Step Functions automatically initiate and monitor these workflows by simplifying error handling.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. AWS Athena and S3. Limits of Athena.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources , including Amazon Athena , which supports Apache Parquet. Canvas provides connectors to AWSdata sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
Specify the AWS Lambda function that will interact with MongoDB Atlas and the LLM to provide responses. As always, AWS welcomes feedback. About the authors Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. Choose Build and after the build is successful, choose Test.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
MLOps focuses on the intersection of data science and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, dataengineering, and data science.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. It can also be integrated into major data platforms like Snowflake.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
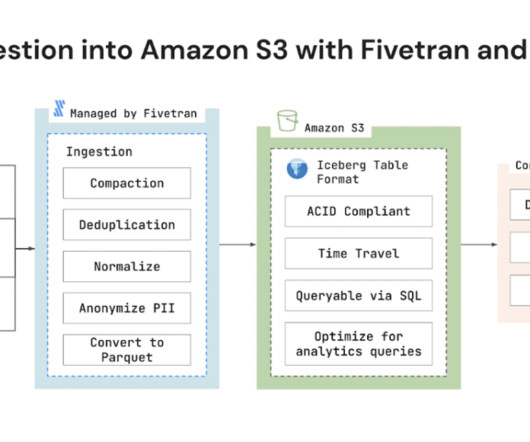
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificial intelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient data pipelines.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. Having a human-in-the-loop to validate each data transformation step is optional.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Note we have two folders.
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a data warehouse or datalake.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Big data isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed. This pushes into big data as well, as many companies now have significant amounts of data and large datalakes that need analyzing.
Collecting, processing, and carrying out analysis on streaming data , in industries such as ad-tech involves intense dataengineering. The data generated daily is huge (100s of GB data) and requires a significant processing time to process the data for subsequent steps. What is Delta Lake? End Result.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. Eitan Sela is a Generative AI and Machine Learning Specialist Solutions Architect at AWS.
This account manages templates for setting up new ML Dev Accounts, as well as SageMaker Projects templates for model development and deployment, in AWS Service Catalog. It also hosts a model registry to store ML models developed by data science teams, and provides a single location to approve models for deployment.
We outline how we built an automated demand forecasting pipeline using Forecast and orchestrated by AWS Step Functions to predict daily demand for SKUs. On an ongoing basis, we calculate mean absolute percentage error (MAPE) ratios with product-based data, and optimize model and feature ingestion processes.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. Given the range of tools and data types, a separate data versioning logic will be necessary.
Below, we explore five popular data transformation tools, providing an overview of their features, use cases, strengths, and limitations. Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
Qlik Replicate Qlik Replicate is a data integration tool that supports a wide range of source and target endpoints with configuration and automation capabilities that can give your organization easy, high-performance access to the latest and most accurate data. Matillion is not a no-code solution, but rather a low-code solution.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Accenture calls it the Intelligent Data Foundation (IDF), and it’s used by dozens of enterprises with very complex data landscapes and analytic requirements. Simply put, IDF standardizes dataengineering processes. IDF works natively on cloud platforms like AWS. Take a look at figure 1 below.
Data analysts often must go out and find their data, process it, clean it, and get it ready for analysis. This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. Cloud Services: Google Cloud Platform, AWS, Azure.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
For example, if you use AWS, you may prefer Amazon SageMaker as an MLOps platform that integrates with other AWS services. SageMaker Studio offers built-in algorithms, automated model tuning, and seamless integration with AWS services, making it a powerful platform for developing and deploying machine learning solutions at scale.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content